
آزمایشگاههای فناوری با کمک هوش مصنوعی دو مدل مولد جدید را معرفی کرده اند که میتوانند پروتئین های جدیدی را که در طبیعت یافت نمیشوند بر حسب نیاز بسازند.
به گزارش تکناک، فناوری مدلهای هوش مصنوعی تبدیل متن به تصویر مانند DALL-E 2 متعلق به OpenAI در آزمایشگاههای بیوتکنولوژی که از هوش مصنوعی مولد به نام مدل انتشار استفاده میکنند، سر و صدا ایجاد کرده است.
مدلهای انتشار، مدلهای مولد هوش مصنوعی هستند، به این معنی که برای تولید دادههایی مشابه آنچه که بر روی آن آموزش دیدهاند، استفاده میشوند. اساساً، مدلهای انتشار با از بین بردن دادههای آموزشی از طریق افزودن پی در پی نویز گاوسی کار میکنند، و سپس یاد میگیرند که دادهها را با معکوس کردن این فرآیند نویزینگ بازیابی کنند.
بر اساس گزارش MIT Technology Review در روز پنجشنبه، برنامههایی که از مدلهای انتشار برای توسعه دقیقتر طراحی پروتئینهای جدید استفاده میکنند، توسط دو آزمایشگاه به طور مستقل اعلام شدهاند.
شرکت Generate Biomedicines مستقر در بوستون از Chroma رونمایی کرد که از آن به عنوان “DALL-E 2 of biology” یاد میکند.
برایان تریپ، یکی از مخترعان RoseTTAFold، گفت: ما در حال تولید پروتئین هایی هستیم که واقعاً هیچ شباهتی به پروتئین های موجود ندارند.برنامه RoseTTAFold Diffusion به طور همزمان توسط تیمی در دانشگاه واشنگتن به سرپرستی دیوید بیکر زیست شناس ایجاد شد.
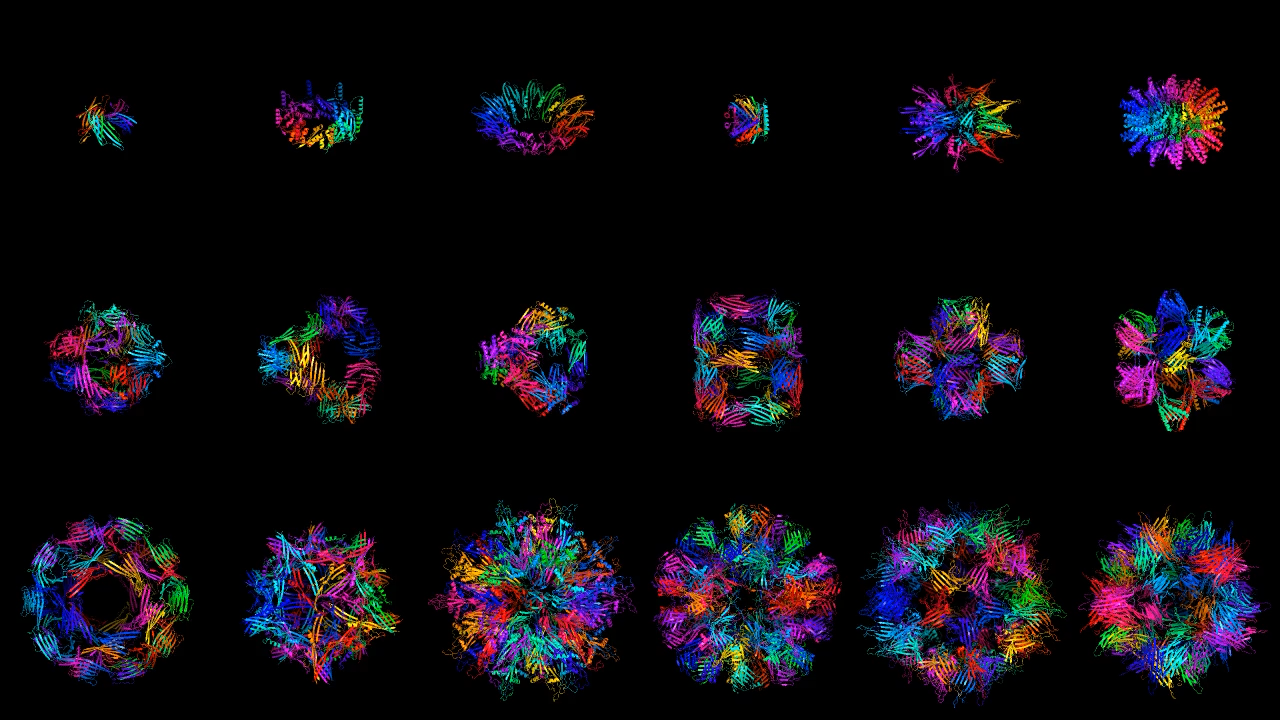
گئورگ گریگوریان، مدیرعامل Generate Biomedicines گفت: ما میتوانیم در عرض چند دقیقه کشف کنیم که چه چیزی باعث شده که تکامل میلیونها سال طول بکشد.
این مولدهای پروتئین را می توان به گونه ای برنامه ریزی کرد تا طرح هایی برای پروتئین هایی با ویژگی های خاص مانند ساختار، اندازه یا عملکرد ایجاد کنند.
در اصل، این امکان توسعه پروتئینهای جدیدی را فراهم میآورد که میتوان از آنها برای انجام وظایف خاص استفاده کرد.
آوا امینی، بیوفیزیکدان در تحقیقات مایکروسافت در کمبریج ماساچوست، گفت: آنچه در این کار قابل توجه است، تولید پروتئین ها بر اساس محدودیت های مورد نظر است.
استفاده از پروتئین ها به عنوان مداخلات درمانی
محققان پیش بینی می کنند که این روش تولید پروتئین در نهایت منجر به ساخت داروهای تازه و موثرتر شود.بسیاری از داروهای جدید مبتنی بر پروتئین هستند زیرا پروتئین ها اهداف اصلی داروها هستند.
عناصر ساختمانی ضروری سیستم های زنده پروتئین ها هستند. موجودات زنده از آنها برای هضم غذا، انقباض عضلات ، حس کردن نور، فعال کردن سیستم ایمنی و بسیاری موارد دیگر استفاده می کنند. آنها نقش مهمی در بهبود بیماری ها دارند. اما، فهرست مواد اولیه مورد نیاز برای ساخت دارو در حال حاضر فقط شامل پروتئین های طبیعی است. هدف از ایجاد پروتئین مصنوعی افزودن تعداد بیپایانی از پروتئینهای مصنوعی طراحی شده توسط رایانه به آن فهرست است.
گریگوریان می گوید: طبیعت اساساً برای ساختن همه چیز از پروتئین ها استفاده می کند.اما این روش چشم انداز جدیدی برای تولید داروهای جدید مبتنی بر پروتئین های مصنوعی ایجاد می کند.
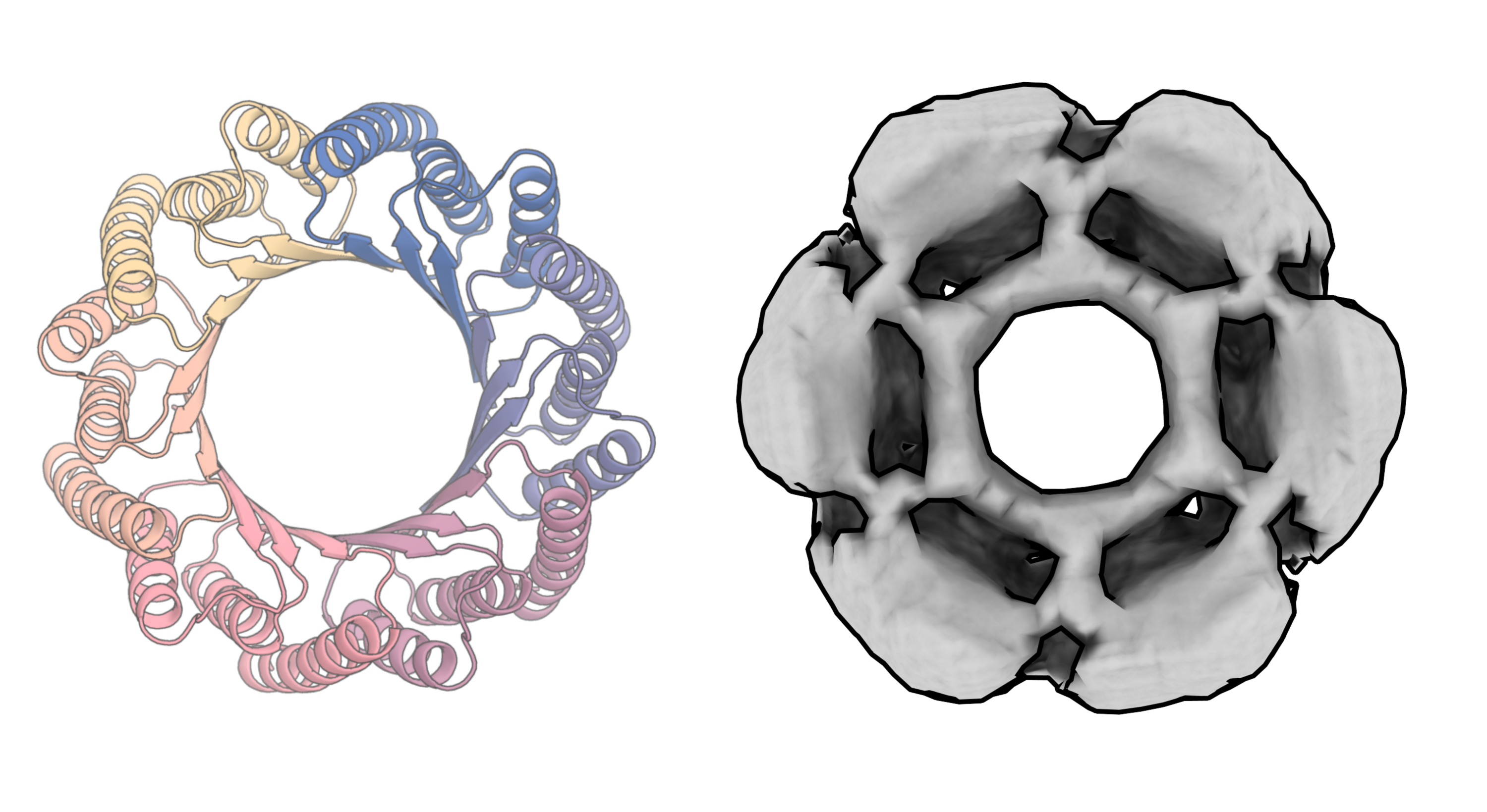
هیچ چیز جدیدی در مورد روش های محاسباتی برای طراحی پروتئین ها وجود ندارد. با این حال، روشهای قبلی محاسباتی کند بودند و در ایجاد پروتئینهای بزرگ یا کمپلکس پروتئینی و ماشینهای مولکولی که از پروتئینهای متعدد به هم پیوسته ساخته می شوند، بسیار مؤثر نبودند.
تولید پروتئین از طریق مدل های انتشار
مدلهای انتشار، شبکههای عصبی هستند که برای فیلتر کردن نویز ( تغییرات تصادفی ایجاد شده در دادهها ) از داده های ورودی خود آموزش دیدهاند. یک مدل انتشار تلاش می کند تا تصویری قابل تشخیص از مجموعه تصادفی پیکسل ها تولید کند.
این مدلها در چند تحقیق اخیر توسط امینی و دیگران ثابت کردهاند که یک روش امیدوارکننده هستند، با این حال، اینها فقط مدل هایی برای اثبات مفهوم بودند.
چنین مطالعاتی به عنوان پایه ای برای اولین برنامه های کامل، Chroma و RoseTTAFold Diffusion، که می توانند طرح های دقیقی را برای طیف وسیعی از پروتئین ها ایجاد کنند، عمل کردند.
نامراتا آناند، که یکی از اولین مدلهای انتشار را برای تولید پروتئین در ماه می 2022 توسعه داد، گفت.: شاید منصفانه باشد که بگوییم این بیشتر شبیه DALL-E است زیرا آنها مقیاس را افزایش داده اند.
اثربخشی اصلی Chroma و RoseTTAFold Diffusion، به عقیده Namrata Anand، این است که آنها توانسته اند با آموزش بر روی داده ها و رایانه های بیشتر، مقیاس قدرت این تکنیک را افزایش دهند.
Chroma با جدا کردن زنجیرههای آمینو اسیدهای سازنده پروتئینها، نویز را به سیستم خود اضافه میکند. سپس سعی می کند از مجموعه تصادفی این زنجیره ها پروتئینی بسازد.
کروما میتواند پروتئینهای منحصربهفردی با ویژگیهای خاص ، در حالی که با محدودیتهای از پیش تعیینشده در مورد ظاهر محصول نهایی هدایت میشود، تولید کند
با وجود استفاده از استراتژی متفاوت، تیم بیکر به نتایج قابل مقایسه ای دست می یابد. مدل انتشار آن با ساختاری شروع می شود که به طور قابل توجهی بی نظم است.
تمایز مهم دیگر این است که RoseTTAFold Diffusion، بر خلافAlphaFold ، متعلق به DeepMind از دادههای یک شبکه عصبی جداگانه هوش مصنوعی استفاده میکند که برای پیشبینی ساختار پروتئین برای تعیین اینکه چگونگی قرار گرفتن اجزای یک مولکول با هم ، آموزش دیدهاند. این اصل راهنمای فرآیندکلی است.
ساخت پروتئین های جدید فقط شروع است
به گفته گریگوریان، ایجاد پروتئین های جدید فقط نقطه آغاز است. او گفت: در پایان، آنچه مهم است این است که آیا میتوانیم با این روش تولید پروتئین های مصنوعی جدید داروهایی بسازیم که مؤثر باشند یا نه.
داروهای پایه پروتئین نیاز به تولید انبوه، تست های آزمایشگاهی و در نهایت آزمایش انسانی دارند. ممکن است چندین سال بگذرد تا این دارو ها کاربردی و موثر شوند
اما گریگوریان معتقد است که کسبوکار او و دیگران روشهایی را برای استفاده از هوش مصنوعی برای تسریع چنین مراحلی نیز کشف خواهند کرد.
بیکر معتقد است: میزان پیشرفت رضایت بخش است و آغاز شده است. اما در حال حاضر ما در میانه روندی هستیم که فقط می توان آن را یک انقلاب تکنولوژیکی نامید.



















