
شرکت انویدیا مدعی است که پردازنده گرافیکی H100 انویدیا دو برابر سریعتر از MI300X ایامدی است و ایامدی از نرمافزار بهینهشده برای دستگاه DGX H100 استفاده نکرده است.
بهگزارش تکناک، هنگام عرضه Instinct MI300X، ایامدی ادعا کرد که جدیدترین پردازنده گرافیکیاش برای هوش مصنوعی (AI) و محاسبات با عملکرد بالا (HPC)، در بارگیریهای استنتاجی بسیار سریعتر از پردازنده گرافیکی H100 انویدیاست. بااینحال، هفته گذشته انویدیا نشان داد که وضعیت کاملاً برعکس است. این شرعکت ادعا میکند با بهینهسازی مناسب، سرورهای مبتنیبر H100 از سرورهای Instinct MI300X سریعتر هستند.
تامزهاردور گزارش میدهد که انویدیا ادعا میکند ایامدی از نرمافزار بهینهشده برای دستگاه DGX H100 استفاده نکرده است و برای مقایسه عملکرد آن با سرور مبتنیبر Instinct MI300X استفاده شده است. شرکت یادشده اشاره میکند که عملکرد مطلوب هوش مصنوعی به چهارچوب محاسبات موازی قوی، مجموعهای از ابزارهای چندمنظوره، الگوریتمهای بسیار بهروزشده و سختافزار عالی وابسته است. بهگفته انویدیا، بدون هریک از این شاخصها، عملکرد ضعیف خواهد بود.
انویدیا میافزاید ویژگیهای TensorRT-LLM شامل بهینهسازیهای پیشرفته در سطح کرنل برای معماری Hopper است که عاملی حیاتی برای عملکرد پردازندههای گرافیکی H100 و مشابه آن محسوب میشود. این تنظیم دقیق امکان اجرای عملیات شتابدهنده FP8 روی پردازندههای گرافیکی H100 با مدلهایی مانند Llama 2 70B را بدون کاهش دقت استنتاجها فراهم میکند.
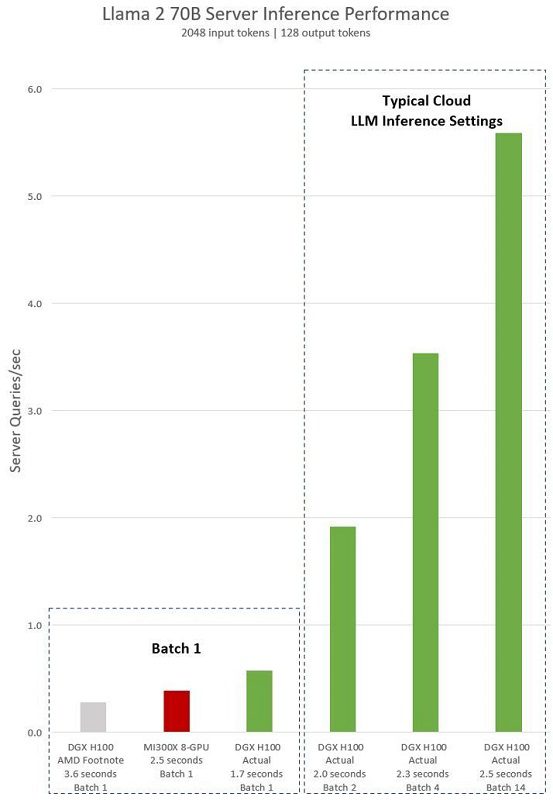
انویدیا برای اثبات حرف خود، معیارهای عملکرد را برای سرور DGX H100 با ۸ پردازنده گرافیکی H100 ارائه داد که مدل Llama 2 70B را اجرا میکند. DGX H100 وظیفه استنتاجی را زمانیکه به اندازه یک دسته (Batch) تنظیم شده است، میتواند تنها در 1.7 ثانیه بهاتمام برساند.
این یعنی هر درخواست را همزمان پردازش میکند که درمقایسهبا ماشین هشتگانه MI300X ایامدی با زمان 2.5 ثانیه (بر اساس اعداد منتشرشده ایامدی) کمتر است. این تنظیمات سریعترین پاسخ را برای پردازش مدل ارائه میدهد.
بهطورکلی، بهمنظور توازن بین زمان پاسخ و کارایی کلی، خدمات ابری اغلب از زمان پاسخ استانداردی برای برخی از وظایف (مانند 2.0 و 2.3 و 2.5 ثانیه در نمودار) استفاده میکنند. این رویکرد به آنها امکان میدهد تا چندین درخواست استنتاج را همزمان در دستههای بزرگتر پردازش کنند و درنتیجه، تعداد کل استنتاجهای روی سرور در هر ثانیه را افزایش دهند. این روش اندازهگیری عملکرد که شامل زمان پاسخ مشخصی است، استانداردی رایج در بنچمارکهای صنعتی مانند MLPerf است.
حتی اصلاحات کوچک در زمان پاسخ میتوانند تعداد استنتاجهایی را بسیار افزایش دهد که سرور همزمان مدیریت میکند. بهعنوان مثال، با زمان پاسخ تعیینشده 2.5 ثانیه، سرور DGX H100 هشتگانه میتواند بیش از ۵ استنتاج Llama 2 70B را در هر ثانیه انجام دهد. این افزایش درخورتوجهی درمقایسهبا پردازش کمتر از یک استنتاج در ثانیه با تنظیمات یک دسته (Batch-One) است. درعینحال، انویدیا عددی برای Instinct MI300X ایامدی در زمان اندازهگیری عملکرد در این تنظیمات نداشت.



















