فهرست مطالب
مطالعه جدید نشان میدهد که مدلهای زبانی بزرگ (LLM) هوش مصنوعی میتوانند اشتباهات خود را تشخیص دهند تا قابلیت اطمینان در تولید متن بهبود یابد.
بهگزارش تکناک، پژوهش جدید محققان مؤسسه تکنیکون و گوگل ریسرچ و اپل نشان میدهد مدلهای زبانی بزرگ (LLMs) از توانایی شناسایی خطاهای خود برخوردارند. این مطالعه حاکی از آن است که مدلهای زبانی بیش از آنچه پیشتر تصور میشد، درک عمیقتری از صداقت پاسخهایشان دارند.
مدلهای زبانی بزرگ مانند ChatGPT و BERT بهدلیل تمایل به تولید پاسخهای نادرست یا بیمعنی که به آنها «توهمات» گفته میشود، همواره با انتقاد روبهرو بودهاند. اصطلاح توهم فاقد تعریف واحدی است و طیف گستردهای از خطاها را دربر میگیرد؛ ازجمله نادرستیهای واقعی، تعصبات، شکستهای منطقی در استدلال و دیگر خطاهای دنیای واقعی. در این تحقیق، محققان این مفهوم را بهعنوان تمامی خطاهای تولیدی مدل در نظر گرفتند.
01
از 06تحلیل رفتار داخلی مدلهای زبانی بزرگ
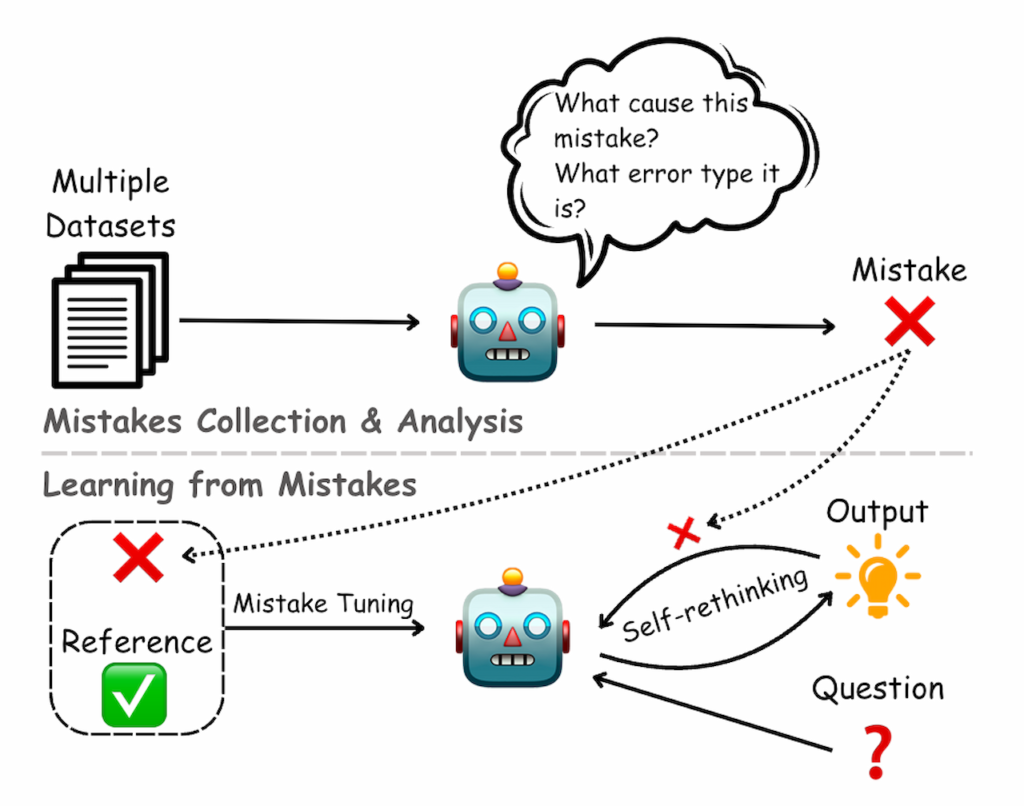
ونچربیت مینویسد که تا به امروز بیشتر تحقیقات درزمینه توهمات مدلهای زبانی بر رفتار خارجی آنها و تحلیل برداشت کاربران از این خطاها متمرکز بود. این روشها درک برخی جنبههای خطاهای مدلها را ممکن میکرد؛ اما بینش محدودی درباره نحوه پردازش و رمزگذاری خطاها در داخل مدلها ارائه میداد. درمقابل، پژوهش جدید با بررسی دقیق فعالیتهای داخلی مدلها نشان داد که مدلهای زبانی بزرگ سیگنالهای مرتبط با صداقت و درستی را در پاسخهای خود رمزگذاری میکنند.
برخلاف تلاشهای پیشین که تنها بر تازهترین توکن تولیدشده یا توکن ورودی مدلها متمرکز بودند، این تحقیق جدید بهجای تمرکز صرف بر خروجی نهایی،توکنهای خاص پاسخ را بررسی میکند که تغییر آنها میتواند درستی پاسخ را تغییر دهد. محققان این شیوه را «توکنهای پاسخ دقیق» نامگذاری کردهاند. این رویکرد به آنها اجازه داد تا اطلاعات جامعتری از نحوه پردازش صداقت مدلها در جریان تولید پاسخها بهدست آورند.
02
از 06نتایج آزمایش و تمرکز اطلاعات صداقت در توکنهای کلیدی
پژوهشگران آزمایشهای خود را روی چهار نسخه از مدلهای Mistral 7B و Llama 2 انجام دادند. این مدلها روی ۱۰ مجموعه داده مختلف شامل وظایفی نظیر پاسخ به پرسشها، استنتاج زبانی طبیعی، حل مسئله ریاضی و تحلیل احساسات آزمایش شدند. آنها برای شبیهسازی استفاده واقعی به مدلها اجازه دادند پاسخهایی بدون محدودیت تولید کنند. یافتهها نشان داد که اطلاعات مربوط به صداقت پاسخها عمدتاً در توکنهای پاسخ دقیق متمرکز شده است.
این الگوهای صداقت در تقریباً تمامی مجموعه دادهها و مدلها ثابت ماند. محققان دراینباره میگویند:
این نتایج نشاندهنده مکانیسم عمومی در مدلهای زبانی بزرگ است که طی آن مدلها اطلاعات مرتبط با صداقت و درستی را در جریان تولید متن پردازش و رمزگذاری میکنند.
03
از 06طبقهبندهای جستوجوگر برای شناسایی خطاها
محققان در این مطالعه از طبقهبندهایی با عنوان «طبقهبندهای جستوجوگر» استفاده کردند. این طبقهبندها که بهطور خاص برای تشخیص ویژگیهای مرتبط با صداقت خروجیهای تولیدشده طراحی شدهاند، با توجه به فعالیتهای داخلی مدلهای زبانی بزرگ میتوانند خطاها را پیشبینی کنند. آزمایشها نشان داد که آموزش این طبقهبندیها با استفاده از توکنهای پاسخ دقیق میتواند دقت در تشخیص خطاها را بسیار افزایش دهد.
04
از 06صداقت مهارتمحور و توانایی تعمیم مدلها
پژوهش یادشده نشان داد که مدلهای زبانی بزرگ صداقت را بهصورت «مهارتمحور» رمزگذاری میکنند. این یعنی طبقهبندهای جستوجوگر، تنها درزمینه وظایفی با نیازهای مهارتی مشابه مانند بازیابی واقعیات یا استدلال منطقی، میتوانند عملکرد خود را تعمیم دهند؛؛ اما در وظایف متفاوت نظیر تحلیل احساسات توانایی تعمیم ندارند. محققان این یافته را بهعنوان ویژگی مهم مدلها ارزیابی کردند و نشان دادند که مدلها برای هر مجموعه از مهارتها جداگانه سیگنالهای مرتبط با صداقت را پردازش و ذخیره میکنند.
05
از 06تناقض بین فعالیتهای داخلی و پاسخهای نهایی مدلها
تحلیلهای این پژوهش تفاوت شگفتآوری را بین فعالیتهای داخلی مدلها و پاسخهای نهایی آنها نشان داد. در نمونههایی مشاهده شد که مدلها با وجود رمزگذاری پاسخ درست در فعالیتهای داخلی خود، پاسخی نادرست تولید میکنند. این یافته حاکی از آن است که روشهای ارزیابی فعلی که تنها بر خروجی نهایی مدلها متکی هستند، ممکن است نتوانند بهدرستی قابلیتهای واقعی آنها را منعکس کنند.
بهگفته محققان، این تفاوت نشان میدهد که با درک و استفاده بهتر از اطلاعات داخلی مدلها، میتوان به تواناییهای پنهان آنها دست یافت و نرخ خطاها را بسیار کاهش داد.
06
از 06پیامدهای آینده و گامهای بعدی در تحقیقات مدلهای زبانی بزرگ
این یافتهها میتواند به طراحی سیستمهای جدیدی برای کاهش توهمات در مدلهای زبانی کمک کند؛ هرچند این تکنیکها عمدتاً در مدلهای منبعباز کاربرد دارند که دسترسی به فعالیتهای داخلی آنها امکانپذیر است. ازیکسو، تحلیل فعالیتهای داخلی مدلهای زبانی بزرگ میتواند به توسعه تکنیکهای مؤثرتری برای شناسایی و کاهش خطا کمک کند و ازسویدیگر، بهعنوان بخشی از تحقیقات وسیعتر درک بهتری از فرایندهای داخلی مدلهای زبانی بزرگ ارائه دهد.
آزمایشگاههای پیشرو هوش مصنوعی نظیر OpenAI و آنتروپیک و دیپمایند گوگل نیز با روشهای متفاوت عملکرد داخلی مدلها را مطالعه کردهاند. این مطالعات درمجموع میتواند به ساخت مدلهای زبانی با قابلیتهای پیشرفتهتر و سیستمهای هوشمندتر و مطمئنتر کمک کند. محققان دراینباره نوشتند:
«یافتههای ما نشان میدهد که نمایشهای داخلی مدلهای زبانی بزرگ بینشهای مفیدی درزمینه خطاهای آنها فراهم و پیچیدگی پیوند بین فرایندهای داخلی مدلها و خروجیهای خارجی را برجسته میکند. امیدواریم راهی برای بهبود بیشتر در تشخیص و کاهش خطاها وجود داشته باشد.