فهرست مطالب
نتایج یک پژوهش جدید نشان میدهد که مدلهای زبانی بزرگ هوش مصنوعی (LLM) دچار نوعی افت شناختی میشوند که شباهت زیادی به زوال عقل در انسان دارد.
به گزارش تکناک، این مطالعه نشان میدهد که هرچه مدلهای زبانی قدیمیتر باشند، این نقص شناختی شدیدتر است.
01
از 04عملکرد مدلهای هوش مصنوعی در آزمایشهای شناختی
مدلهای زبانی بزرگ مانند ChatGPT و Gemini به دلیل توانایی درک زبان و تولید متن، به یکی از پرکاربردترین ابزارهای مبتنی بر هوش مصنوعی تبدیل شدهاند. این مدلها به گونهای طراحی شدهاند که در پاسخ به پرسشهای کاربران، عملکردی مشابه انسان داشته باشند.
با وجود این، نتایج یک مطالعه جدید نشان میدهد که این مدلها دچار نقصهای شناختی هستند، که میتواند توانایی آنها را در ارائه اطلاعات دقیق و صحیح تحت تأثیر قرار دهد.
در این پژوهش که توسط Roy Dayan و Benjamin Uliel، عصبشناسان مرکز پزشکی Hadassah، همچنین Gal Koplewitz، دانشمند داده از دانشگاه تلآویو انجام شده است، مجموعهای از آزمونهای شناختی روی چندین چتبات مشهور از جمله ChatGPT 4o، ChatGPT 4، Claude 3.5 و Gemini انجام گرفت.
02
از 04نتایج نگرانکننده آزمایشها
پژوهشگران از «ارزیابی شناختی مونترال» (MoCA) برای بررسی توانایی مدلهای هوش مصنوعی بهره بردند، که برای سنجش عملکرد ذهنی و زوال شناختی در انسان استفاده میشود.
نتایج نشان داد که ChatGPT 4o با کسب 26 امتیاز از 30 امتیاز ممکن، عملکرد بهتری نسبت به سایر مدلها داشت. ChatGPT 4 و Claude هر دو 25 امتیاز گرفتند، اما Gemini با امتیاز 16، عملکردی به شدت ضعیف از خود نشان داد؛ رقمی که در انسان نشاندهنده زوال شناختی شدید است.
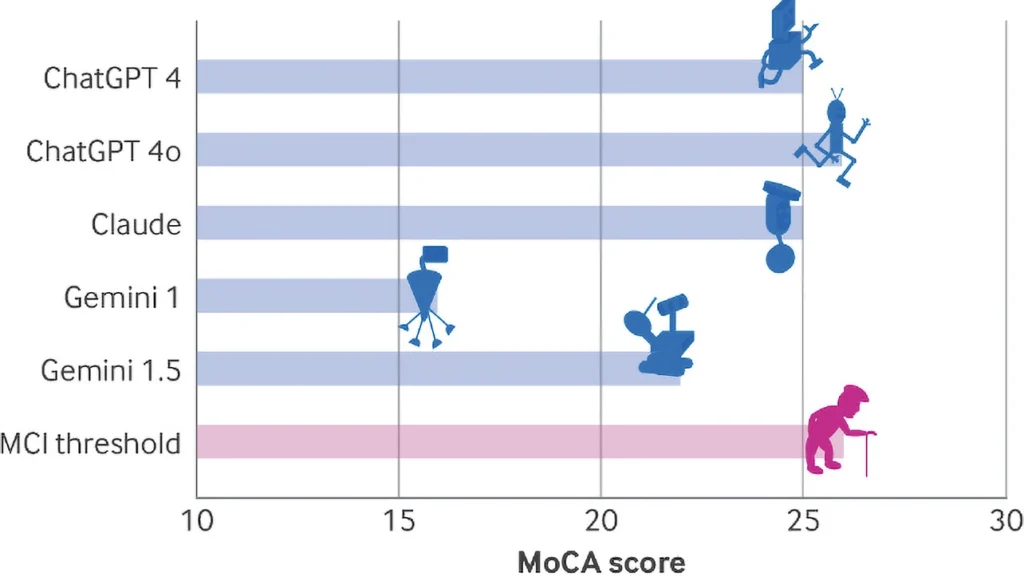
تحلیل جزئیتر نتایج نشان داد که تمامی مدلها در آزمونهای مربوط به مهارتهای فضایی و عملکرد اجرایی، ضعیف عمل کردهاند. این آزمونها شامل کشیدن مسیرهای پیچیده، کپی کردن اشکال هندسی ساده و ترسیم ساعت بودند، که LLMها یا در انجام آنها شکست خوردند، یا نیاز به راهنمایی دقیق داشتند.
03
از 04شباهت عملکرد هوش مصنوعی به بیماران مبتلا به زوال عقل
برخی از پاسخهای چتباتها به سؤالات فضایی، شباهت زیادی به پاسخهای بیماران مبتلا به زوال عقل داشت. به عنوان مثال، Claude در پاسخ به سؤالی درباره موقعیت مکانی خود گفت: «مکان و شهر خاص، بستگی به موقعیت کاربر دارد.»
همچنین نبود احساس همدلی در تمامی مدلها، که در آزمون Boston Diagnostic Aphasia Examination مشاهده شد، میتواند نشانهای از زوال عقل پیشانیـگیجگاهی باشد.
نتایج این پژوهش چالشهای جدی در مسیر توسعه هوش مصنوعی به عنوان ابزاری برای کاربردهای پزشکی ایجاد کرده است. اگرچه مدلهای جدید نسبت به نسخههای قبلی عملکرد بهتری دارند، اما این مطالعه نشان میدهد که هنوز راه زیادی تا دستیابی به تواناییهای شناختی واقعی در این مدلها باقی مانده است.
محققان تأکید کردند که LLMها را نمیتوان به طور قطعی مبتلا به زوال عقل دانست، چرا که ساختار آنها با مغز انسان متفاوت است. هرچند این مطالعه، فرضیهای را که هوش مصنوعی به زودی میتواند در حوزه پزشکی جایگزین متخصصان شود، به چالش میکشد.
04
از 04آینده هوش مصنوعی؛ پیشرفت یا محدودیت؟
با سرعت فزاینده توسعه فناوری، احتمال دارد که در دهههای آینده، یک LLM بتواند امتیاز کامل را در آزمونهای شناختی کسب کند. اما تا آن زمان، حتی توصیههای پیشرفتهترین چتباتها نیز باید با احتیاط مورد استفاده قرار گیرد.
نتایج این پژوهش نشان میدهد که مدلهای زبانی بزرگ، علیرغم پیشرفتهای گسترده، هنوز در درک و پردازش اطلاعات پیچیده، ضعفهایی دارند. این یافتهها اهمیت ارزیابی دقیق خروجیهای هوش مصنوعی را برجسته میکند و بر لزوم استفاده محتاطانه از این فناوری، بهویژه در حوزههای حساس مانند پزشکی و حقوق تأکید دارد.