شرکت گوگل با معرفی VaultGemma، نخستین مدل زبانی بزرگ خود با قابلیت حفظ حریم خصوصی، گامی تازه در مسیر توسعه هوش مصنوعی برداشت.
به گزارش تکناک، این مدل که توسط تیم Google Research توسعه یافته، بر پایه مدل Gemma 2 ساخته شده و با بهرهگیری از تکنیک «حریم خصوصی تفاضلی» (Differential Privacy) طراحی شده است تا احتمال بازتولید مستقیم دادههای آموزشی کاهش یابد.
یکی از چالشهای اصلی مدلهای زبانی بزرگ (LLM) استفاده از دادههای حساس کاربران در فرایند آموزش است. این مدلها در برخی موارد ممکن است بخشهایی از دادههای آموزشی خود را بدون تغییر بازگو کنند؛ مسئلهای که در صورت وجود اطلاعات شخصی یا محتوای دارای حق نشر، خطر نقض حریم خصوصی یا بروز مشکلات حقوقی را در پی دارد. شرکت گوگل برای جلوگیری از چنین اتفاقی، با افزودن نویز کنترلشده در مرحله آموزش تلاش کرده است تا مانع «حفظ شدن» دادهها در حافظه مدل شود.
هرچند بهکارگیری حریم خصوصی تفاضلی میتواند دقت مدل را کاهش دهد و نیاز پردازشی بیشتری ایجاد کند، اما پژوهشگران گوگل با بررسی «قوانین مقیاسپذیری حریم خصوصی» توانستهاند تعادلی میان دقت، حریم خصوصی و منابع پردازشی ایجاد کنند. نتایج نشان میدهد که VaultGemma با وجود تنها یک میلیارد پارامتر، عملکردی نزدیک به مدلهای غیرخصوصی همرده دارد.
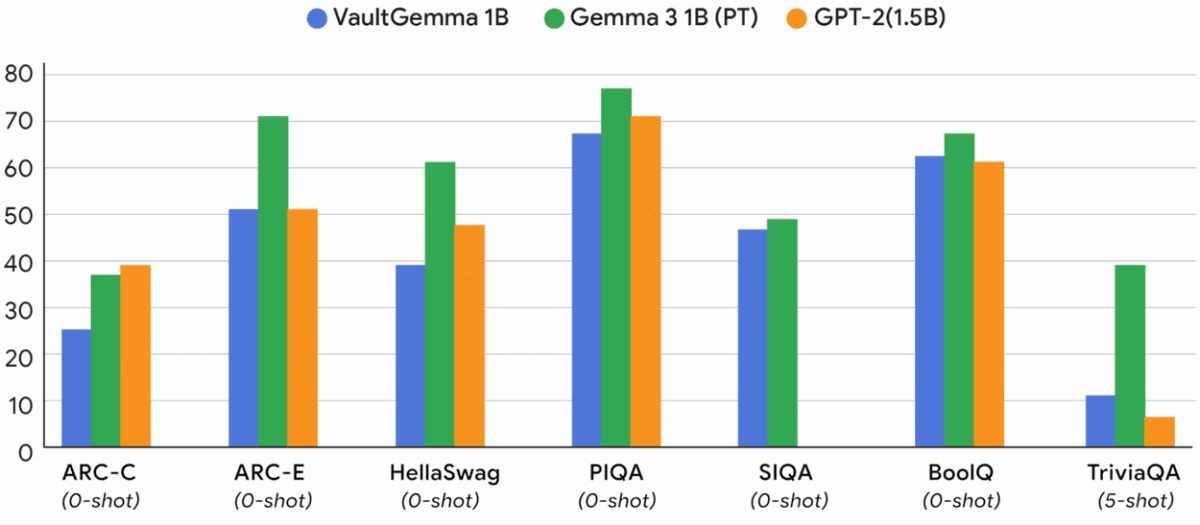
به گفته گوگل، مدل زبانی بزرگ VaultGemma فعلاً یک پروژه آزمایشی است، اما میتواند مبنای توسعه نسل جدید مدلهای زبانی با محوریت امنیت و حریم خصوصی باشد. این مدل اکنون با وزنهای باز (Open Weights) از طریق Hugging Face و Kaggle در دسترس پژوهشگران و توسعهدهندگان قرار گرفته است. با وجود این، مانند دیگر مدلهای خانواده Gemma، کاملاً متنباز نیست و کاربران ملزم به رعایت شرایط مجوز گوگل هستند.
کارشناسان اعتقاد دارند که این دستاورد میتواند زمینهساز توسعه مدلهای کوچکتر و هدفمندتر باشد؛ مدلهایی که در کاربردهای تخصصی، توازن میان کارایی و حفاظت از حریم خصوصی کاربران بیش از مقیاسپذیری صرف اهمیت دارد.