
اینتل بهینهسازیهای جدیدی برای Llama 3.1، شتابدهندهی هوش مصنوعی خود، معرفی کرده است که عملکرد را در طیف وسیعی از محصولات این شرکت افزایش میدهد.
بهگزارش تکناک، مدل زبان بزرگ جدید شرکت متا، Llama 3.1، اکنون دردسترس قرار گرفته و اینتل نیز پشتیبانی کامل از این مدل را روی مجموعه محصولات خود ازجمله Gaudi ،Xeon ،Arc و Core اعلام کرده است.
اینتل بهطور مداوم روی اکوسیستم نرمافزاری هوش مصنوعی خود کار میکند و مدلهای جدید Llama 3.1 روی محصولات هوش مصنوعی این شرکت با پشتیبانی از فریمورکهای مختلفی مانند PyTorch ،Intel Extension for PyTorchv ،DeepSpeed، کتابخانههای Hugging Face Optimum و vLLM فعال شدهاند.
اینتل اطمینان میدهد که کاربران از عملکرد بهبودیافته روی محصولات هوش مصنوعی اینتل در دیتاسنتر و لبهی شبکه و کامپیوترهای شخصی برای اجرای هوش مصنوعی Llama 3.1 متا بهرهمند میشوند.
Wccftech مینویسد که Llama 3.1 مجموعهای از مدلهای زبان بزرگ چندزبانه (LLMs) است که مدلهای مولد پیشتنظیمشده و با دستورالعمل در اندازههای مختلف را ارائه میدهد. بزرگترین مدل پایهای معرفیشده در Llama 3.1، مدل ۴۰۵ میلیارد پارامتری است که قابلیتهای پیشرفتهای در دانش عمومی، هدایتپذیری، ریاضیات، استفاده از ابزار و ترجمهی چندزبانه بهارمغان میآورد.
مدلهای کوچکتر شامل مدلهای ۷۰ میلیارد و ۸ میلیارد پارامتری هستند؛ جایی که مدل ۷۰ میلیارد پارامتری عملکرد قدرتمندتر و درعینحال مقرونبهصرفهتری دارد و مدل ۸ میلیارد پارامتری مدلی سبک برای ارائهی پاسخهای بسیار سریع است.
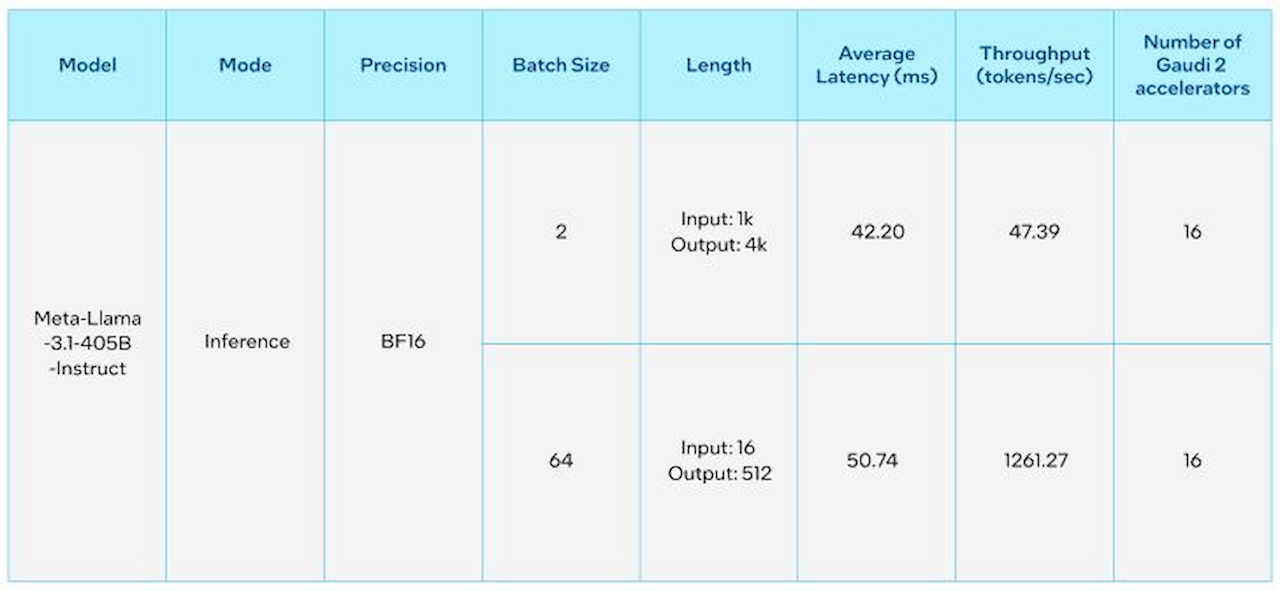
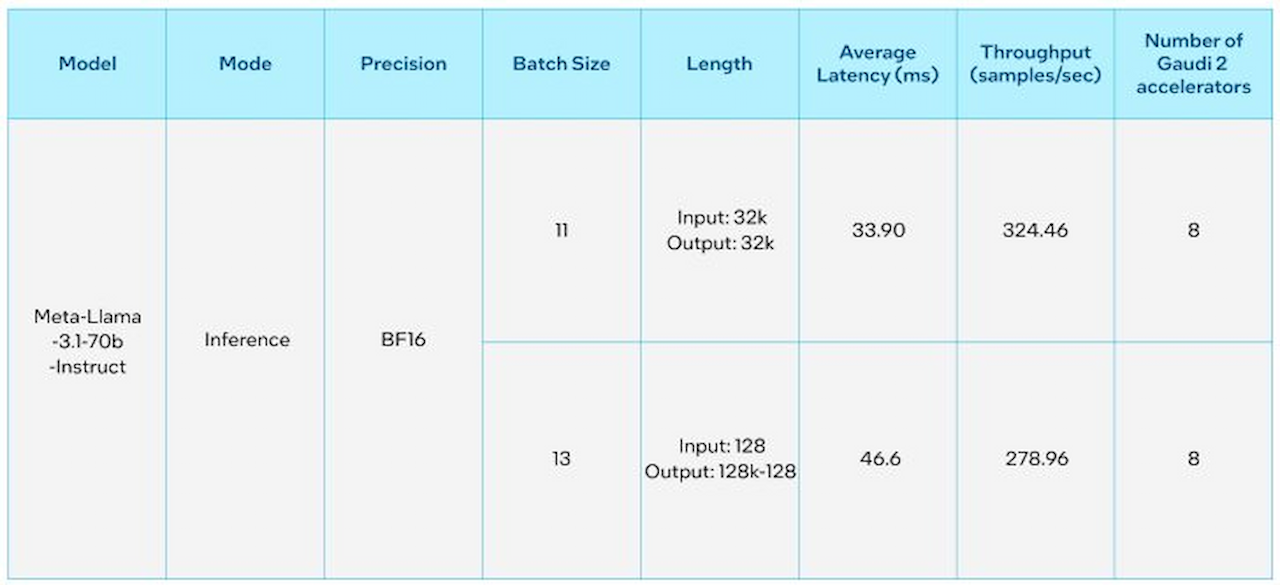
اینتل عملکرد مدل Llama 3.1 با ۴۰۵ میلیارد پارامتر را روی شتابدهندههای Gaudi خود آزمایش کرد. این شتابدهندهها پردازندههای ویژهای هستند که برای آموزش و استنتاج با عملکرد مطلوب و مقرونبهصرفه طراحی شدهاند.
نتایج واکنش سریع و توان عملیاتی چشمگیر را با طول توکنهای مختلف نشان میدهند که تواناییهای شتابدهندههای Gaudi 2 و نرمافزار Gaudi را بهنمایش میگذارند. بهطور مشابه، شتابدهندههای Gaudi 2 عملکرد حتی سریعتری روی مدل ۷۰ میلیارد پارامتری با طول توکنهای ۳۲ هزار و ۱۲۸ هزار نشان میدهند.
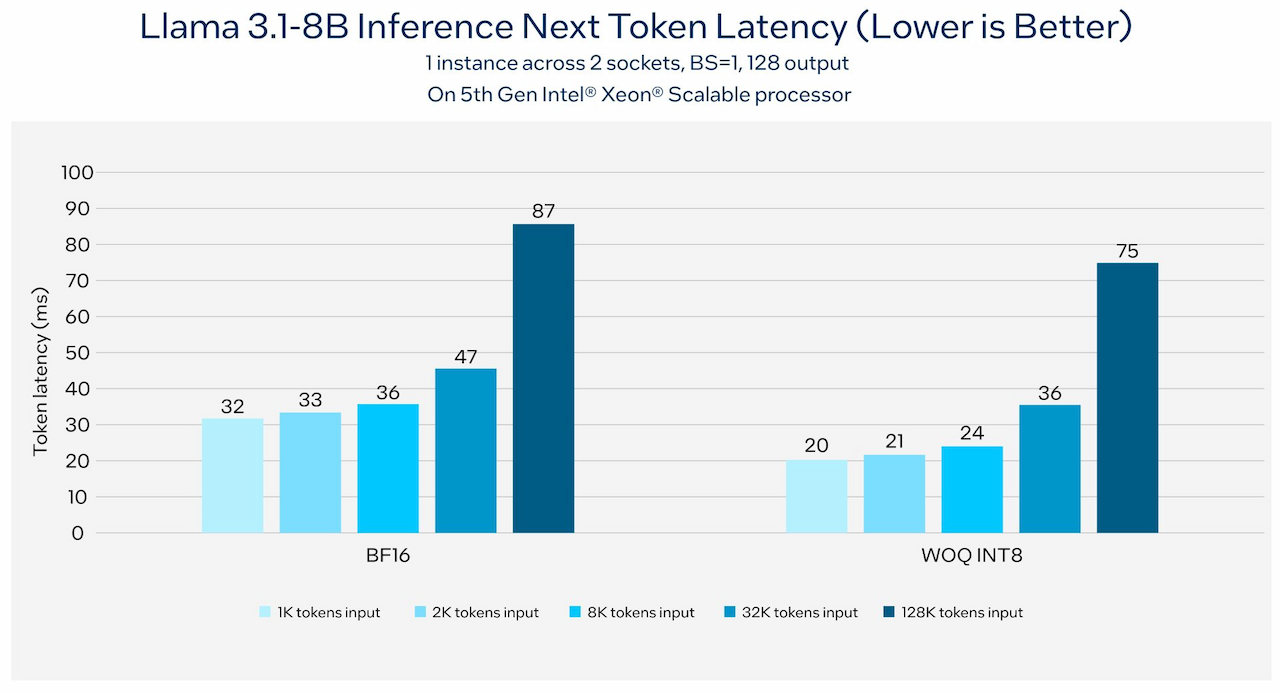
در مرحلهی بعد، عملکرد مدل Llama 3.1 روی پردازندههای نسل پنجم Xeon Scalable اینتل با طول توکنهای مختلف بررسی شد. با ورودیهای ۱,۰۰۰ و ۲,۰۰۰ و ۸,۰۰۰ توکن، تأخیر توکن در هر دو آزمایش BF16 و WOQ INT8 در محدودهی نزدیکی قرار دارد (عمدتاً کمتر از ۴۰ و ۳۰ میلیثانیه).
این نشاندهندهی پاسخ سریع پردازندههای Xeon اینتل است که از فناوری AMX این شرکت (دستورالعملهای ماتریس پیشرفته) برای عملکرد برتر هوش مصنوعی برخوردارند. حتی با ورودیهای ۱۲۸ هزار توکن، تأخیر در هر دو آزمایش کمتر از ۱۰۰ میلیثانیه باقی میماند.
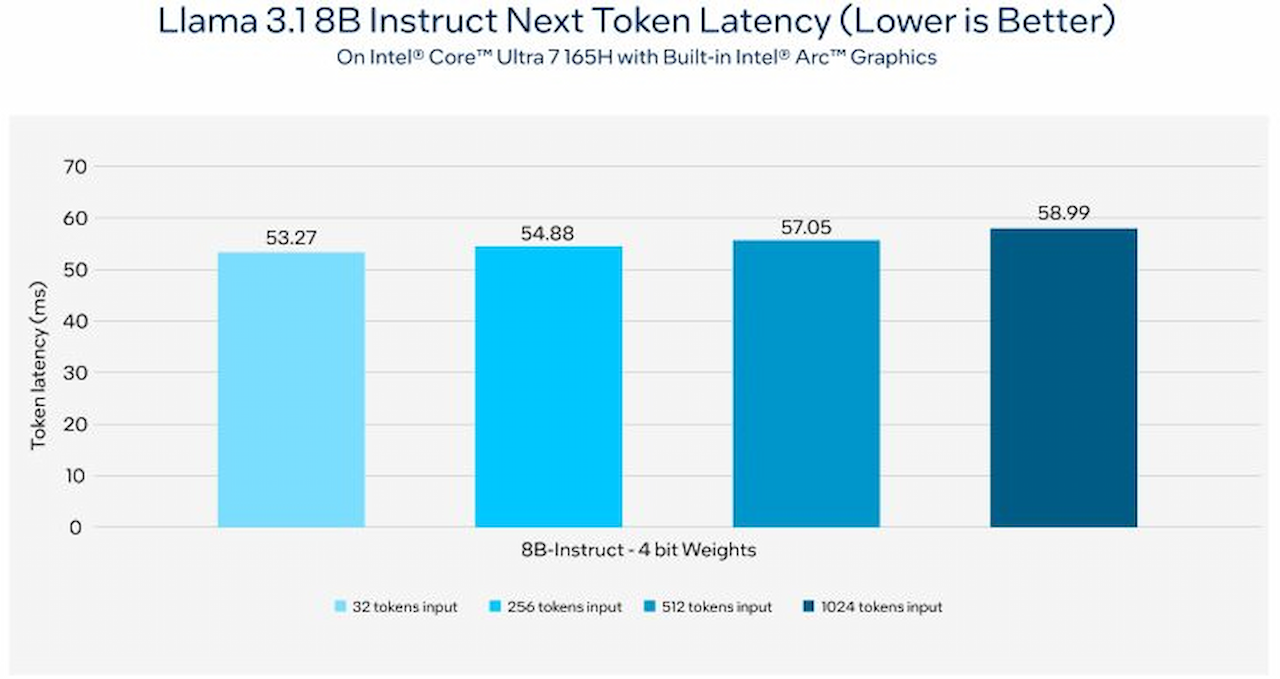
استنتاج مدل ۸ میلیارد پارامتری Llama 3.1 روی پردازندههای Core Ultra اینتل نیز با آزمایش مدل ۸ میلیارد پارامتری با دستورالعمل وزن ۴ بیتی بسیار سریع است. همانطورکه در پردازنده Core Ultra 7 165H با گرافیک مجتمع Arc آزمایش شد، تأخیر توکن با ورودیهای ۳۲، ۲۵۶، ۵۱۲ و ۱,۰۲۴ توکن بین ۵۰ تا ۶۰ میلیثانیه باقی میماند.
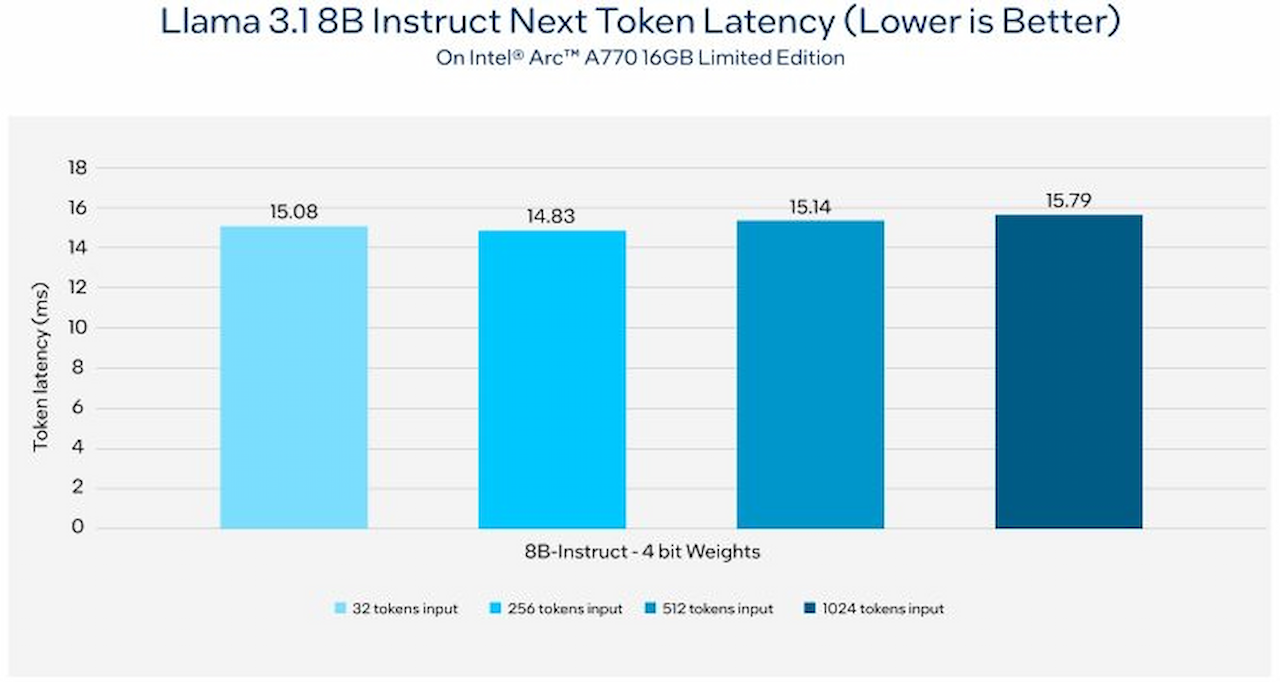
ناگفته نماند که روی کارت گرافیک مجزای Arc مانند Arc A770 16GB Limited Edition، تأخیر با هر چهار ورودی توکن با اندازههای مختلف، بسیار کم و حدود ۱۵ میلیثانیه باقی میماند.


















