تراشه جدید انویدیا با افزایش ۵۰ برابری بهرهوری انرژی و کاهش هزینهها، توان پردازشی سیستمهای هوش مصنوعی را در تحلیل متنهای طولانی به شکل بیسابقهای ارتقا داد.
به گزارش سرویس سخت افزار تکناک، این شرکت با معرفی نسل تازه زیرساختهای هوش مصنوعی خود تحت عنوان Blackwell Ultra، گام تازهای در مسیر پاسخگویی به نیازهای رایانش عاملمحور برداشته است؛ حوزهای که اکنون به یکی از محورهای اصلی تحول در اکوسیستم هوش مصنوعی تبدیل شده است. تازهترین بنچمارکها نشان میدهد که پیکربندی GB300 NVL72 در پردازشهای کمتأخیر و بارهای کاری مبتنی بر کانتکست طولانی، عملکرد کمسابقهای ارائه میدهد.
از زمان جهش بزرگ هوش مصنوعی در سال ۲۰۲۲، تمرکز صنعت به تدریج از آموزش صرف مدلها به سمت استقرار سامانههای عاملمحور تغییر کرده است؛ سامانههایی که نیازمند پهنای باند حافظه بالا، ارتباطات پرسرعت میان پردازندهها و حداقل تأخیر عملیاتی هستند. در چنین فضایی، زیرساخت صرفاً یک لایه پشتیبان محسوب نمیشود، بلکه به عامل تعیینکننده در کیفیت پاسخگویی مدلها تبدیل شده است.
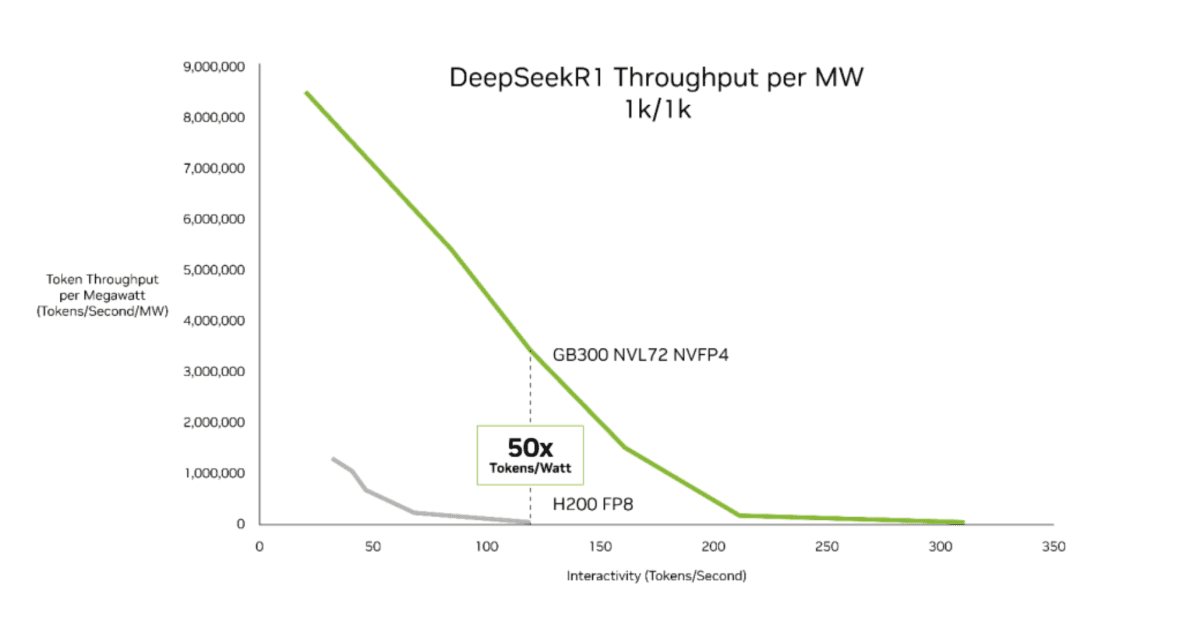
بر اساس گزارش Wccftech، این شرکت در ارزیابیهای جدید خود با استفاده از آزمون InferenceMAX متعلق به SemiAnalysis، بر شاخص «توکن بر وات» تمرکز کرده است؛ معیاری که اکنون به یکی از مهمترین گزینههای سنجش برای ابرمقیاسدهندگان در توسعه مراکز داده تبدیل شده است. طبق اعلام شرکت انویدیا، پیکربندی تراشه جدید توانسته است نسبت به پردازندههای نسل Hopper، تا ۵۰ برابر افزایش توان عملیاتی به ازای هر مگاوات را به ثبت برساند؛ عددی که نشاندهنده جهشی بنیادین در بهرهوری انرژی و گذردهی پردازش است.

بخش مهمی از این پیشرفت به ارتقای فناوری NVLink بازمیگردد. در معماری Blackwell Ultra، حداکثر ۷۲ پردازنده گرافیکی در قالب یک بستر یکپارچه NVLink با پهنای باند ارتباطی ۱۳۰ ترابایتبرثانیه به یکدیگر متصل میشوند. این در حالی است که معماری Hopper به طراحی هشتتراشهای محدود بود. علاوه بر این، بهینهسازی معماری رک و بهرهگیری از قالب دقت NVFP4، نقش تعیینکنندهای در افزایش گذردهی و بهبود نسبت عملکرد به مصرف انرژی ایفا کردهاند.
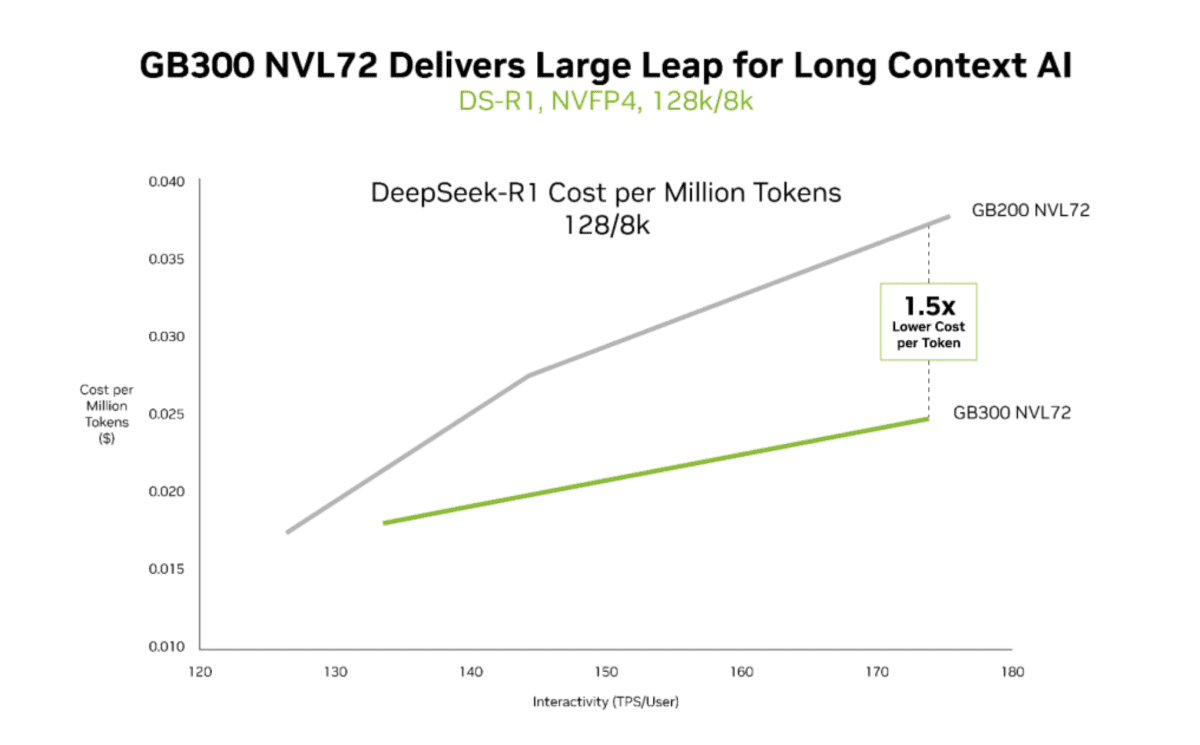
همچنین انویدیا در چارچوب موج هوش مصنوعی عاملمحور، هزینه پردازش توکن را در تراشه جدید خود مورد ارزیابی قرار داده است. بر اساس دادههای منتشرشده، هزینه هر یک میلیون توکن در GB300 NVL72 تا ۳۵ برابر کاهش یافته است؛ موضوعی که این پلتفرم را به گزینهای راهبردی برای آزمایشگاههای پیشرو و شرکتهای ابرمقیاس تبدیل میکند. این شرکت تأکید کرده است که قوانین مقیاسپذیری همچنان برقرار هستند و همافزایی طراحی سختافزار و نرمافزار، موتور محرک این شتاب عملکردی محسوب میشود.
در مقایسهای دیگر، انویدیا عملکرد GB200 و GB300 را در بارهای کاری با کانتکست طولانی بررسی کرده است؛ حوزهای که برای سامانههای عاملمحور اهمیت حیاتی دارد، چرا که حفظ وضعیت کامل یک کدبیس یا محیط عملیاتی مستلزم مصرف گسترده توکن است. بر اساس نتایج اعلامشده، Blackwell Ultra تا ۱.۵ برابر هزینه کمتر به ازای هر توکن و تا دو برابر سرعت بیشتر در پردازش attention ارائه میدهد.

در حالی که روند یکپارچهسازی Blackwell Ultra در زیرساخت ابرمقیاسدهندگان ادامه دارد، این نتایج از نخستین ارزیابیهای رسمی این معماری به حساب میآید و نشان میدهد که انویدیا همچنان جایگاه مسلط خود را در رقابت زیرساخت هوش مصنوعی حفظ کرده است و مسیر مقیاسپذیری عملکرد را همسو با نیازهای نسل جدید کاربردهای AI پیش میبرد.