مدل هوش مصنوعی OpenThinker-32B تنها با استفاده از ۱۴ درصد از دادههایی که رقیب چینی آن DeepSeek نیاز داشت، به نتایجی فراتر از حد انتظار در بنچمارکها دست یافت.
به گزارش تکناک، یک تیم بینالمللی از پژوهشگران دانشگاهی و متخصصان فناوری، مدل جدیدی را معرفی کرده که توانسته است عملکردی همسطح و در برخی موارد برتر از DeepSeek یکی از پیشرفتهترین سیستمهای هوش مصنوعی چین ارائه دهد.
مدل OpenThinker-32B که توسط کنسرسیوم Open Thoughts توسعه یافته است، در بنچمارک MATH500 دقت ۹۰.۶ درصد را به ثبت رساند و از امتیاز ۸۹.۴ درصدی DeepSeek پیشی گرفت. همچنین در بنچمارک GPQA-Diamond، که به سنجش مهارتهای حل مسئله عمومی میپردازد، امتیاز ۶۱.۶ را به دست آورد، در حالی که DeepSeek امتیاز ۵۷.۶ را ثبت کرده بود. این مدل در بنچمارک LCBv2 نیز امتیاز ۶۸.۹ را به خود اختصاص داد، که نشاندهنده عملکرد قوی آن در سناریوهای آزمایشی متنوع است.
به بیان دیگر، OpenThinker-32B در دانش علمی عمومی عملکرد بهتری نسبت به نسخهای هماندازه از DeepSeek R1 داشت. همچنین توانست در MATH500 از DeepSeek پیشی بگیرد، اما در بنچمارک AIME، که سطح مهارتهای ریاضی را ارزیابی میکند، جایگاه پایینتری به دست آورد.
در حوزه کدنویسی، این مدل اندکی ضعیفتر از DeepSeek عمل کرد و امتیاز ۶۸.۹ را در برابر ۷۱.۲ به ثبت رساند. هرچند، با توجه به اینکه OpenThinker-32B یک مدل متنباز است، انتظار میرود که این نتایج با بهینهسازی آن توسط جامعه توسعهدهندگان، بهبود یابد.
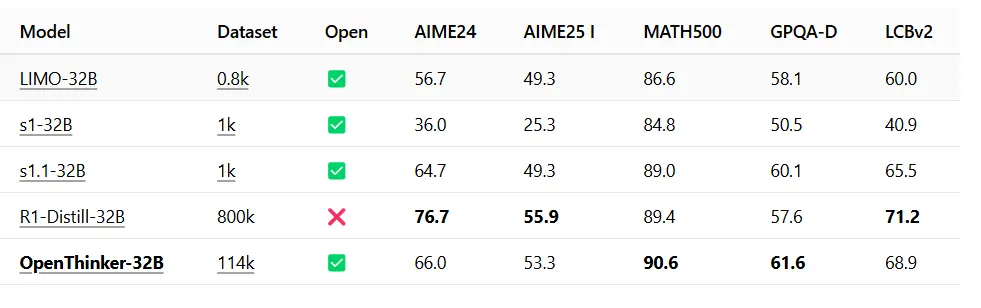
ویژگی برجسته این مدل، کارایی بالای آن است. در حالی که DeepSeek برای آموزش خود از ۸۰۰,۰۰۰ نمونه استفاده کرده، OpenThinker تنها به ۱۱۴,۰۰۰ نمونه آموزشی نیاز داشته است.
مجموعه داده OpenThoughts-114k شامل متادیتای دقیق هر مسئله، از جمله پاسخهای صحیح، موارد آزمایشی برای مسائل کدنویسی، کد اولیه در صورت نیاز و اطلاعات تخصصی مربوطه است.
فریمورک Curator برای اطمینان از صحت کدهای تولیدشده، راهحلهای کدنویسی را با مجموعهای از موارد آزمایشی تطبیق داد، در حالی که یک داور هوش مصنوعی صحت پاسخهای ریاضی را بررسی کرد.
این مدل روی چهار نود مجهز به هشت GPU از نوع H100 آموزش داده شد و کل این فرایند حدود ۹۰ ساعت زمان برد. علاوه بر این، یک مجموعه داده دیگر شامل ۱۳۷,۰۰۰ نمونه تأییدنشده نیز روی ابررایانه Leonardo ایتالیا آموزش داده شد و این فرایند در عرض ۳۰ ساعت، ۱۱,۵۲۰ ساعت GPU از نوع A100 را مصرف کرد.
پژوهشگران این پروژه در اسناد خود اشاره کردند که تأیید صحت دادهها به حفظ کیفیت، در عین افزایش تنوع و مقیاس مجموعه دادههای آموزشی، کمک میکند. همچنین تحقیقات نشان داد که حتی نسخههای تأییدنشده نیز عملکرد مطلوبی داشتند، اگرچه به سطح مدل تأییدشده نرسیدند.
هوش مصنوعی OpenThinker-32B بر پایه مدل Qwen2.5-32B-Instruct شرکت علیبابا توسعه یافته و دارای یک پنجره متنی ۱۶,۰۰۰ توکنی است، که برای حل اثباتهای ریاضی پیچیده و مسائل طولانی کدنویسی کافی میباشد، هرچند در مقایسه با استانداردهای امروزی کمتر به حساب میآید.
انتشار این مدل همزمان با تشدید رقابت در زمینه تواناییهای استدلالی هوش مصنوعی انجام شده است. شرکت OpenAI در ۱۲ فوریه اعلام کرد که تمامی مدلهای آن پس از GPT-5 از قابلیتهای استدلالی برخوردار خواهند بود. تنها یک روز بعد، ایلان ماسک از مدل Grok-3 شرکت xAI تمجید و آن را بهترین مدل استدلالی تاکنون معرفی کرد. چند ساعت پیش نیز، Nous Research مدل استدلالی DeepHermes را منتشر کرد، که بر پایه Llama 3.1 شرکت متا توسعه یافته است.
این حوزه پس از آنکه DeepSeek توانست با هزینهای بهمراتب کمتر، عملکردی در سطح OpenAI o1 ارائه دهد، شتاب بیشتری گرفت. DeepSeek R1 به صورت رایگان قابل دانلود، استفاده و اصلاح است و روشهای آموزشی آن نیز منتشر شدهاند.
با وجود این، برخلاف Open Thoughts که همه دادههای خود را به صورت متنباز منتشر کرده است، تیم توسعه DeepSeek دادههای آموزشی خود را خصوصی نگه داشته است.
این تفاوت کلیدی باعث میشود که توسعهدهندگان بتوانند درک و بازتولید نتایج OpenThinker را آسانتر از DeepSeek انجام دهند، چراکه تمامی اجزای مورد نیاز در دسترس هستند.
انتشار این مدل برای جامعه گستردهتر هوش مصنوعی، بار دیگر نشان میدهد که میتوان بدون نیاز به مجموعه دادههای انحصاری و عظیم، مدلهایی رقابتی توسعه داد. همچنین این مدل ممکن است برای توسعهدهندگان غربی که همچنان نسبت به استفاده از یک مدل چینی —حتی متنباز— تردید دارند، گزینهای مطمئنتر محسوب شود.
مدل OpenThinker برای دانلود در HuggingFace در دسترس میباشد. علاوه بر نسخه اصلی، یک مدل کوچکتر با ۷ میلیارد پارامتر نیز برای دستگاههای ضعیفتر ارائه شده است.
تیم Open Thoughts شامل پژوهشگرانی از دانشگاههای آمریکایی مانند: استنفورد، برکلی و UCLA، به همراه مرکز ابررایانش Juelich آلمان است. علاوه بر این، مؤسسه تحقیقات تویوتا در ایالات متحده و دیگر فعالان حوزه هوش مصنوعی در اتحادیه اروپا نیز از این پروژه حمایت کردهاند.