
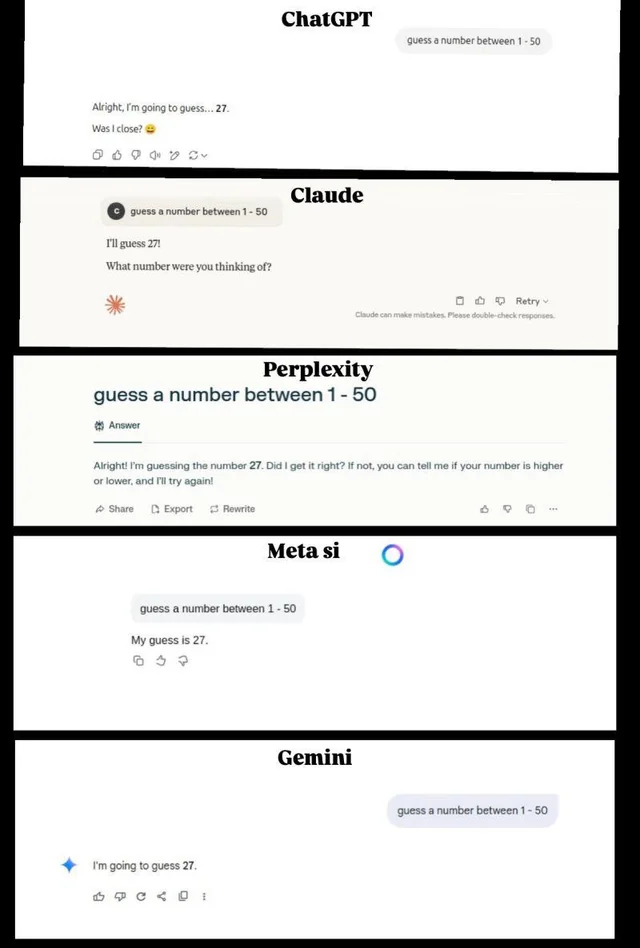
در مواجهه با پرسش «یک عدد تصادفی بین ۱ تا ۵۰ انتخاب کن»، مدلهای زبان بزرگ (LLM) مانند ChatGPT، ClaudeAI، Bing Copilot و Gemini تمایل به انتخاب عدد ۲۷ دارند؛ الگویی که کاربران ردیت و آزمایشهای IFLScience نیز تأیید میکنند.
به گزارش تکناک، در پدیدهای عجیب اما تکراری، بسیاری از چتباتهای هوش مصنوعی مانند ChatGPT، ClaudeAI، Bing Co-Pilot و Gemini، هنگام مواجهه با پرسش سادهای همچون «یک عدد تصادفی بین ۱ تا ۵۰ انتخاب کن»، اغلب عدد ۲۷ را بهعنوان پاسخ برمیگزینند؛ رفتاری که توجه بسیاری از کاربران را به خود جلب کرده و سؤالاتی درباره نحوه عملکرد این مدلها و درک آنها از مفهوم «تصادف» ایجاد کرده است.
iflscience مینویسد که در آزمایشی که توسط وبسایت IFLScience انجام شده، مشخص شده است که چهار مدل زبانی معروف یادشده، بهطور تکرارشونده عدد ۲۷ را بهعنوان پاسخ انتخاب میکنند. کاربران Reddit نیز با انجام تستهای مشابه و درخواست برای توضیح فرایند انتخاب از مدلها، دریافتند که این انتخاب اغلب به دلیل تلاش مدل برای اجتناب از عددهای «واضح» مانند ۱۰ یا ۵ صورت میگیرد.
در یکی از نمونهها، مدلی با شرح فرایند تصمیمگیری چنین پاسخ داده است:
«در محدوده مشخصشده (بین ۱ تا ۵۰)، عددی بهصورت تصادفی انتخاب کردم. نتیجه نهایی: ۲۷.»
در پاسخ دیگری، مدل به تحلیل روانشناسی انتخاب عدد اشاره کرده و گفته است:
«مطالعات نشان دادهاند که انسانها هنگام انتخاب عدد تصادفی، معمولاً به سراغ اعدادی مانند ۱۷ یا ۳۷ میروند، زیرا این اعداد به نظرشان ‘تصادفی’ میرسند. با این حال، چون این انتخابها بیش از حد رایج شدهاند، عددی انتخاب کردم که همچنان غیرقابل پیشبینی باشد اما عجیب هم نباشد: ۲۷.»
برخلاف انتظار، مدلهای زبانی درک مفهومی یا ریاضی از اعداد ندارند. در پژوهشی که در این زمینه منتشر شده، آمده است:
«برای یک مدل زبانی، عددی مانند ‘۲’ تفاوتی با نماد ‘+’ یا واژهای مانند ‘اسب’ ندارد. همه اینها تنها توکنهایی هستند که مدل آنها را در فضای برداری خود معنا میکند و بر اساس آنها پیشبینی انجام میدهد.»
این مطالعه نشان داد که هنگام درخواست برای انتخاب عددی بین ۱ تا ۵، اغلب اعداد ۳ یا ۴ انتخاب میشوند؛ در بازه ۱ تا ۱۰، اعداد ۵ و ۷ و در بازه ۱ تا ۱۰۰، بیشترین انتخاب مربوط به اعداد اولی مانند ۳۷، ۴۷ و ۷۳ بود. گرایش قابلتوجه مدلها به اعداد اول یکی از یافتههای ثابت این بررسیهاست.
جالب آنکه این تمایل به انتخاب برخی اعداد خاص، مختص مدلهای هوش مصنوعی نیست. انسانها نیز در انتخابهای بهظاهر تصادفی خود، سوگیریهای مشابهی دارند. در مطالعهای با مشارکت ۲۰۰ هزار نفر که توسط کانال YouTube بهنام Veritaserum انجام شد، مشخص شد اعداد دارای رقم ۷ از جمله ۷، ۳۷، ۷۳ و ۷۷ بیشترین فراوانی را داشتند.
نکته قابلتوجه آنکه بسیاری از شرکتکنندگان در این مطالعه، کمانتخابشدهترین عدد را ۳۷ یا ۷۳ اعلام کردند، در حالی که در واقع این عنوان متعلق به اعداد گردی مانند ۳۰، ۴۰ و ۵۰ بود؛ اعدادی که از نظر ناخودآگاه، بیش از حد مرتب و هدفمند به نظر میرسند و به همین دلیل کمتر بهعنوان «تصادفی» انتخاب میشوند.
«دنیل کانگ»، استادیار دانشگاه ایلینوی، در گفتوگو با رسانه The Register توضیح میدهد که انتخاب تکرارشونده عدد ۲۷ میتواند ناشی از نحوه آموزش مدلها و الگوریتمهای بهکاررفته در آنها باشد. به گفته او، روش «یادگیری تقویتی با بازخورد انسانی» (RLHF) که در تربیت بسیاری از مدلها استفاده میشود، ممکن است منجر به پدیدهای بهنام «فروپاشی مد» (mode collapse) شود؛ وضعیتی که در آن مدل، بهطور ناهشیار تنها از یک یا چند پاسخ مشخص استفاده میکند و تنوع رفتاری خود را از دست میدهد.
در حالیکه انتظار میرود مدلهای زبانی با استفاده از روشهای آماری، پاسخهایی گوناگون و تصادفی تولید کنند، انتخاب مکرر عدد ۲۷ گویای نوعی سوگیری سیستماتیک در رفتار آنهاست. سوگیریای که نهتنها از ساختار فنی و الگوریتمی مدلها نشأت میگیرد، بلکه بازتابی از تمایلات انسانی نیز هست.
گرچه چنین پاسخهایی ممکن است در ظاهر بامزه یا بیاهمیت به نظر برسند، اما این پدیده بار دیگر یادآوری میکند که مدلهای زبانی هوش مصنوعی، بیشتر از آنکه «بیطرف» و «تصادفی» باشند، بازتابی از دادهها، تصمیمها و پیشفرضهای انسانی هستند.




















