شرکت شیائومی از مدل زبانی متنباز MiMo-V2-Flash با تمرکز بر سرعت بالا و معماری بهینه رونمایی کرد که در زمینه استدلال و کدنویسی، رقیب جدی مدلهای مطرح بازار است.
به گزارش سرویس هوش مصنوعی تکناک، این مدل زبانی بزرگ، بخشی از تلاشهای رو به رشد شیائومی در حوزه هوش مصنوعی پایه به حساب میآید.
شرکت شیائومی، مدل زبانی MiMo-V2-Flash را به عنوان رقیب مستقیم مدلهای پیشرویی مانند DeepSeek V3.2 و Claude 4.5 Sonnet معرفی کرده است. در ادامه نگاه دقیقتری به نحوه عملکرد، ویژگیهای کلیدی و نحوه دسترسی به این مدل خواهیم داشت.
این مدل بر پایه ساختار «ترکیبی از متخصصان» (MoE) با مجموع ۳۰۹ میلیارد پارامتر طراحی شده است، که ۱۵ میلیارد پارامتر آن به صورت فعال عمل میکنند. بر اساس گزارش Gizmochina، این مدل به طور ویژه برای سناریوهای مرتبط با عوامل هوشمند مصنوعی و تعاملات چندمرحلهای توسعه یافته است، که نیازمند استنتاج سریع هستند. شیائومی در این محصول از یک معماری توجه ترکیبی ۱ به ۵ استفاده کرده است، که توجه جهانی را با توجه پنجره لغزان (SWA) ترکیب میکند. طول محتوای بومی آن ۳۲ هزار توکن است و توانایی پشتیبانی تا ۲۵۶ هزار توکن را دارد. این طراحی به مدل کمک میکند تا ضمن حفظ کارایی بالا در وظایف مرتبط با متون طولانی، مقیاسپذیری داشته باشد. شیائومی ادعا کرده است که این مدل، خروجی را سریعتر از چندین مدل پیشرو از جمله DeepSeek و Claude ارائه میدهد و در عین حال هزینههای عملیاتی کمتری دارد.

نتایج بنچمارکها نشان میدهد که مدل زبانی MiMo-V2-Flash شیائومی در حوزههای مختلف در سطح برتر قرار میگیرد. این مدل در وظایف استدلالی مانند AIME 2025 و GPQA-Diamond رتبه دوم را در میان مدلهای متنباز کسب کرده است. در بنچمارکهای مهندسی نرمافزار نیز عملکردی فراتر از سایر مدلهای متنباز داشته و به سطوحی قابل مقایسه با GPT-5 و Claude 4.5 Sonnet رسیده است. قیمتگذاری این رابط برنامهنویسی (API) برای هر میلیون توکن ورودی ۰.۱ دلار و برای هر میلیون توکن خروجی ۰.۳ دلار تعیین شده است. طبق اعلام شرکت، این مدل با سرعت ۱۵۰ توکن در ثانیه پاسخها را تولید میکند، در حالی که تنها ۲.۵ درصد از هزینه استنتاج مدل Claude را به همراه دارد.
نوآوریهای فنی این مدل شامل پیشبینی چند توکنی (MTP) است، که اجازه میدهد چندین توکن به صورت موازی تولید و پیش از خروجی تایید شوند. این روش توان عملیاتی رمزگشایی را بدون افزایش بار حافظه بهبود میبخشد. همچنین شیائومی روش جدیدی به نام تقطیر سیاست آنلاین چند استاده (MOPD) را معرفی کرده است، که به مدل اجازه میدهد با صرف منابع آموزشی بسیار کمتر نسبت به روشهای سنتی، به عملکرد بالایی دست یابد.
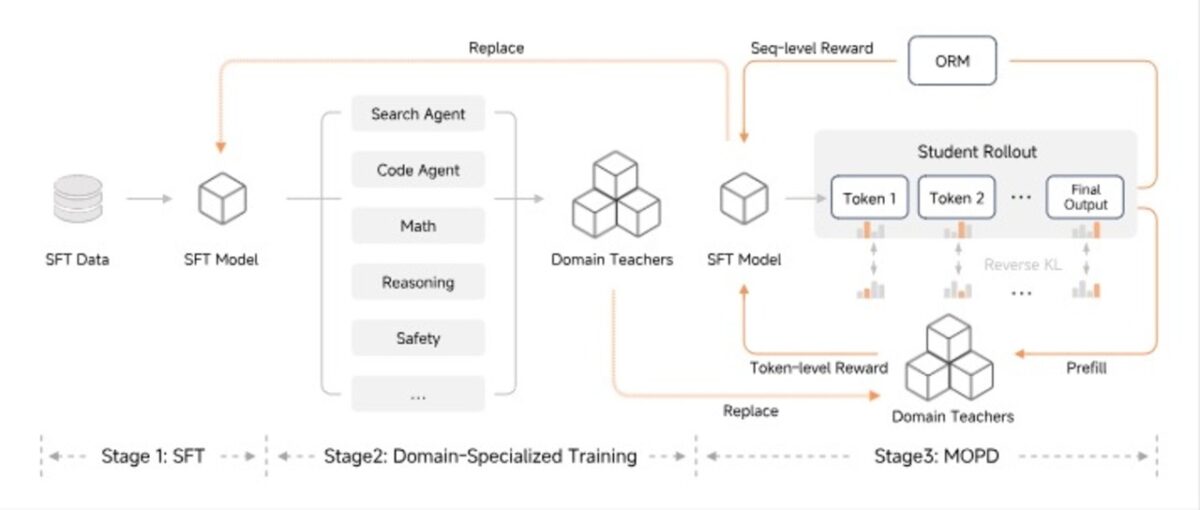
دسترسی به این مدل از طریق رابط چت MiMo Studio فراهم شده است که از جستوجوی وب، جریانهای کاری عاملمحور و تولید کد پشتیبانی میکند. این سرویس قابلیت تغییر حالت بین پاسخهای فوری و پاسخهای تاملی را برای استدلالهای عمیقتر دارد. همچنین MiMo-V2-Flash به طور کامل تحت لیسانس MIT به صورت متنباز منتشر شده و وزنهای مدل در Hugging Face و کدهای استنتاج آن در GitHub در دسترس است.