شرکت متا، آخرین افزودنی به لیست مدلهای هوش مصنوعی مولد خود را به نام Dubbed Code Llama معرفی کرد.
به گزارش تکناک، متا میگوید این ابزار هوش مصنوعی جدید میتواند با استفاده از توصیفات متنی کد تولید کند و درباره آن بحث کند.
اما همانطور که از نام آن پیداست، به وضوح مشخص است که Code Llama بر اساس مدل زبان بزرگ لاما 2 متا (LLM) است که میتواند زبان طبیعی را در حوزههای مختلف درک و تولید کند. متا در اطلاعیه خبری خود میگوید که Code Llama برای وظایف برنامهنویسی ویژهسازی شده است و از زبانهای برنامهنویسی محبوب بسیاری پشتیبانی میکند.
Code Llama
متا میگوید که Code Llama میتواند به عنوان یک ابزار مولد و آموزشی مورد استفاده قرار گیرد تا برنامهنویسان را در نوشتن نرمافزارهای قوی و با مستندات کامل کمک کند. همچنین میتواند در کاهش مانع ورود برای افرادی که در حال یادگیری برنامهنویسی هستند، موثر باشد.
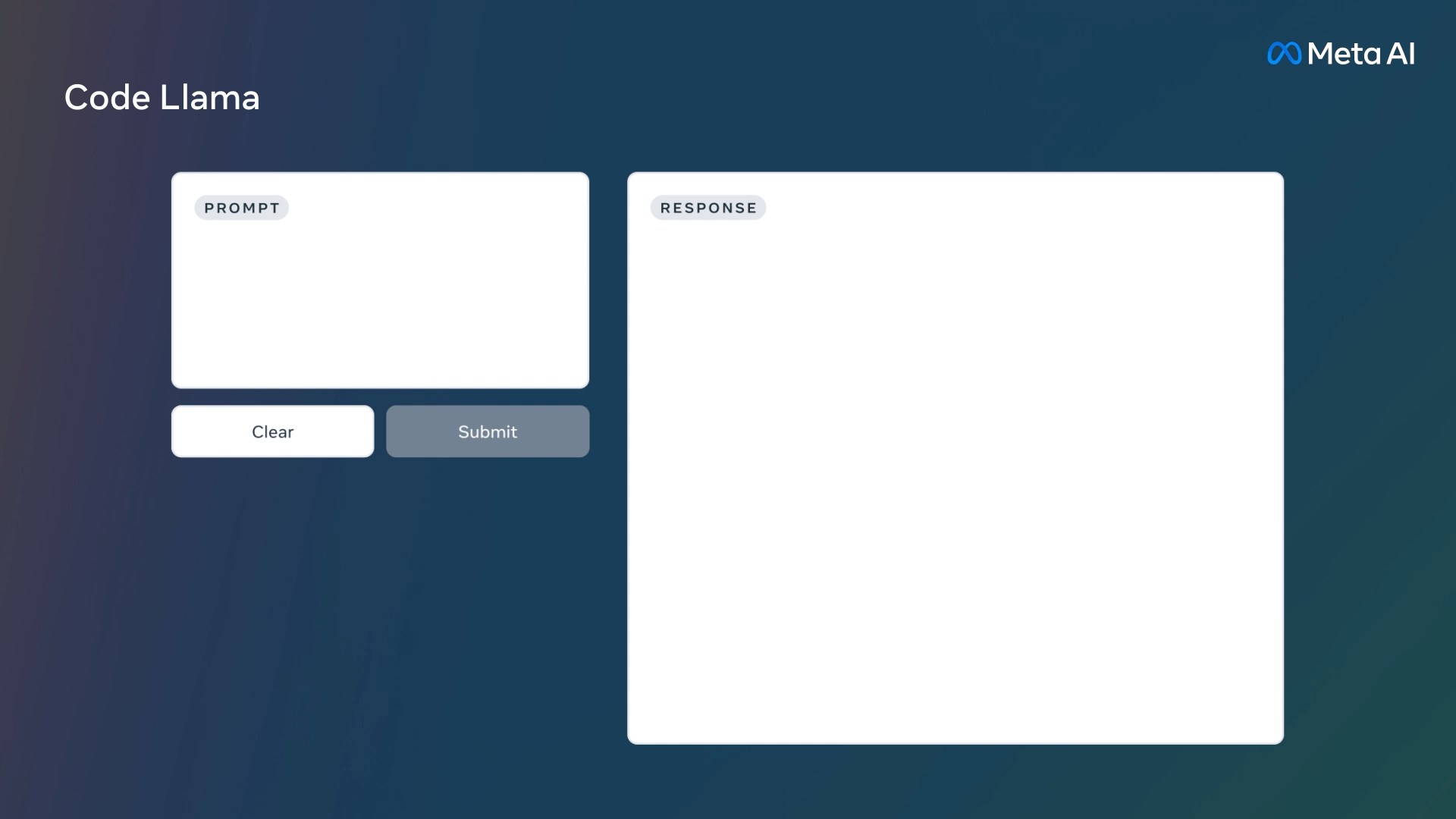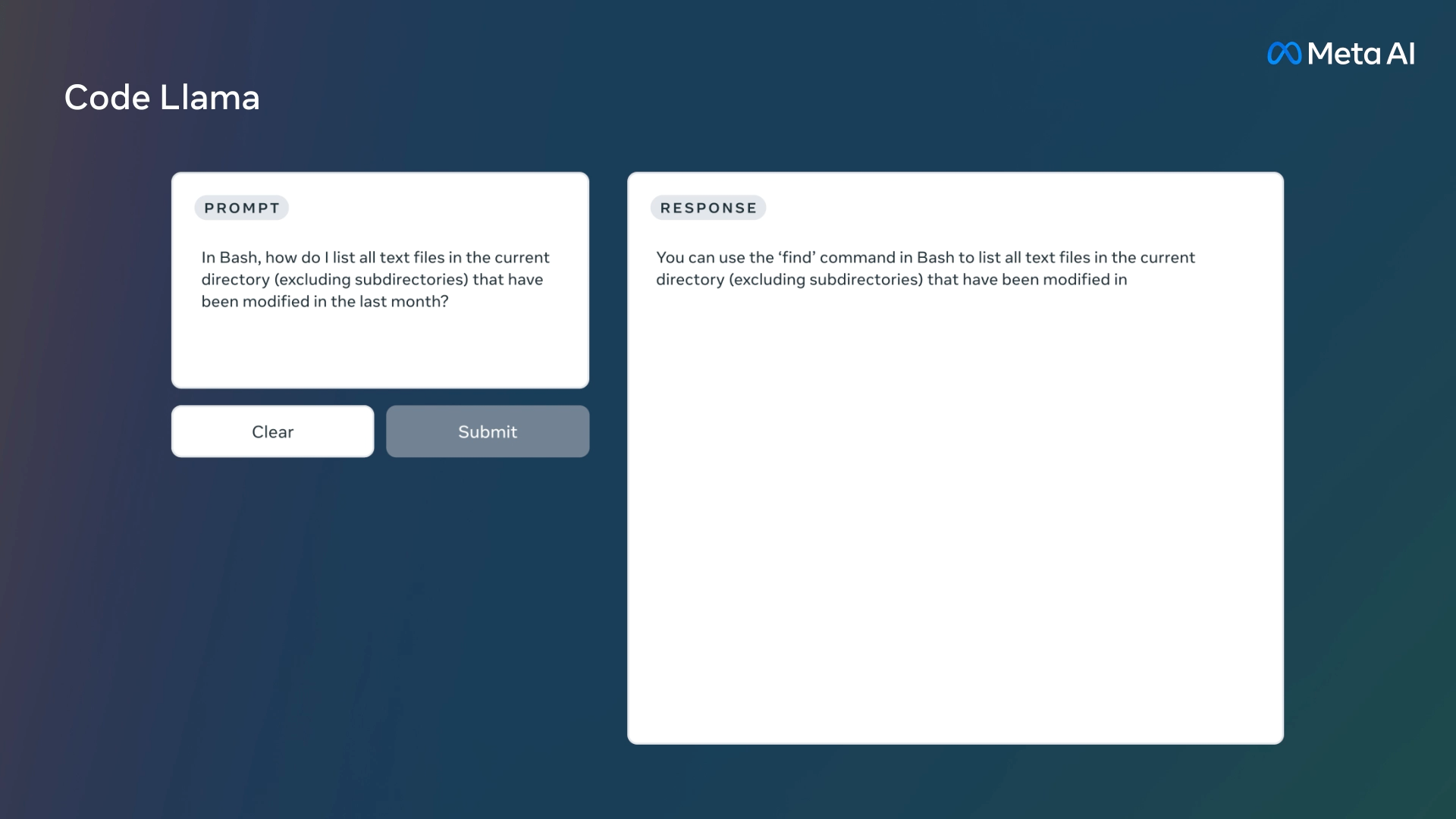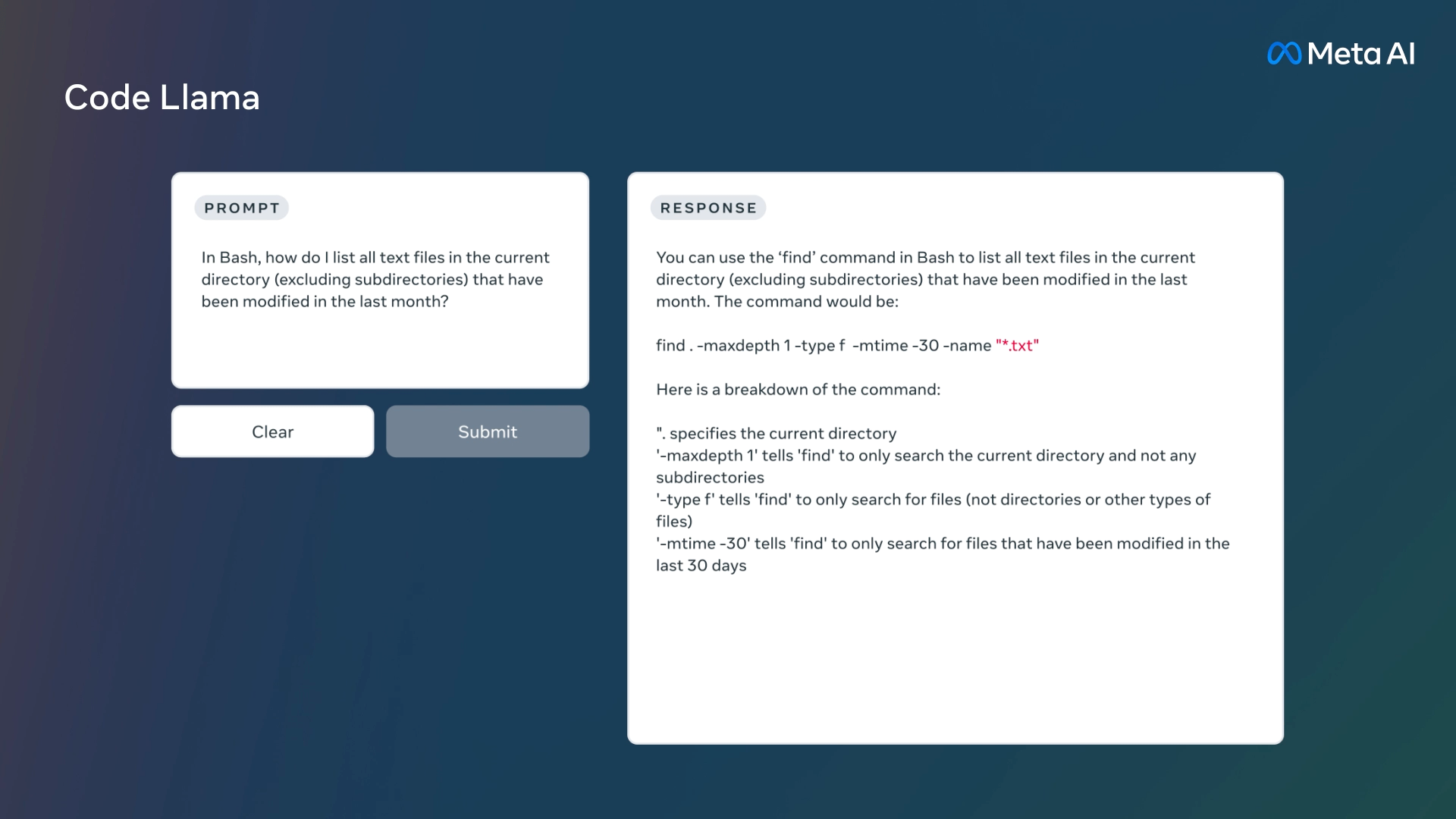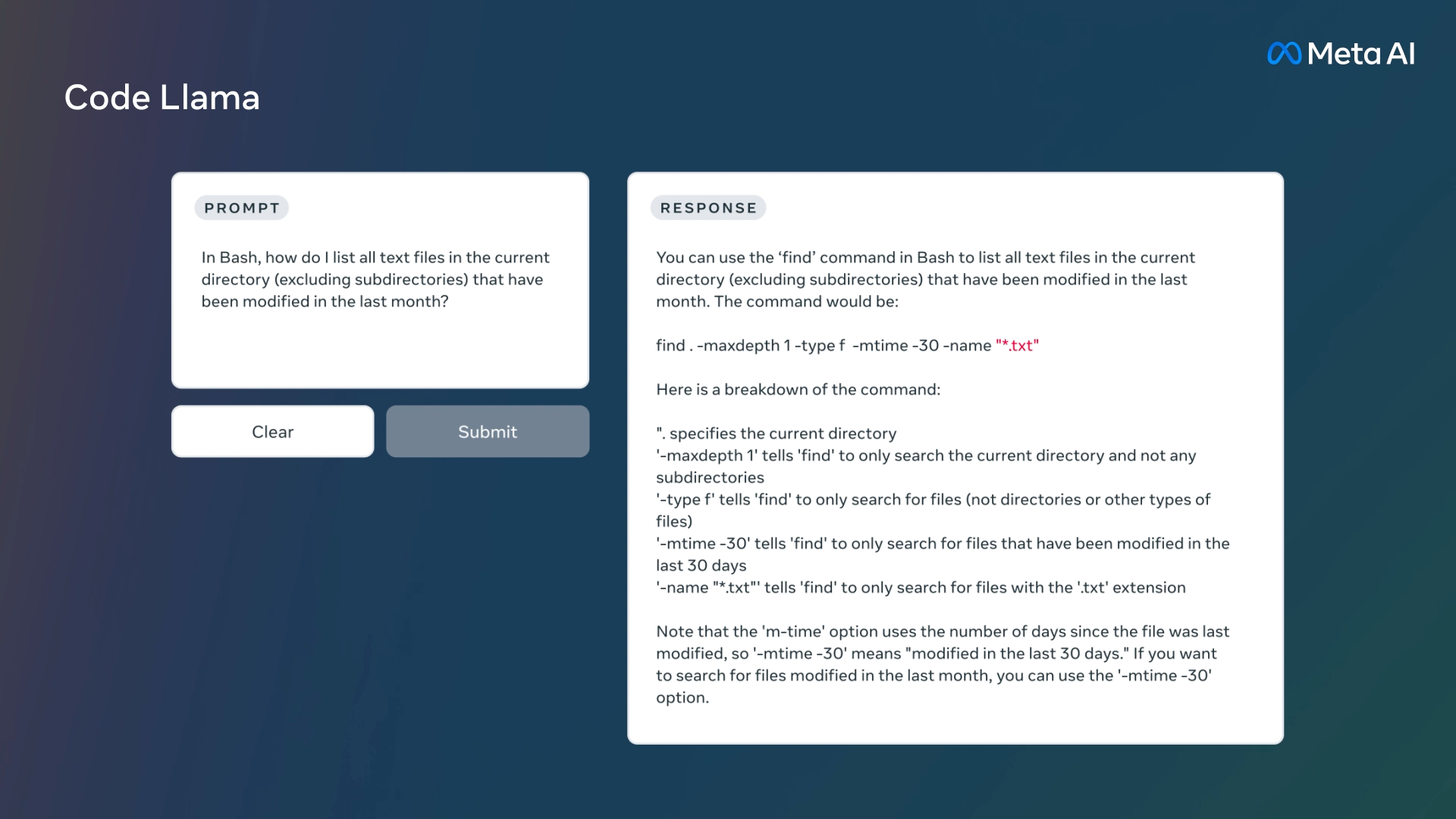
Code Llama قادر است کد و زبان طبیعی درباره کد را از هر دو نوع درخواست کد و زبان طبیعی تولید کند. به عنوان مثال، کاربر یا توسعهدهنده میتواند توصیفی مانند “برایم یک تابع بنویسید که دنباله فیبوناچی را خروجی دهد” را بنویسد و ابزار هوش مصنوعی پاسخ میدهد. همچنین میتوان از آن برای تکمیل کد و رفع اشکال استفاده کرد.
علاوه بر این، قادر است کد را در زبانهای برنامهنویسی مختلف مانند پایتون، C++، جاوا، PHP، تایپاسکریپت، C# و Bash تکمیل و رفع اشکال کند.
متا Code Llama را برای استفاده در تحقیقات و تجارت با استفاده از همان مجوز جامعهای که برای Llama 2 استفاده میشود، منتشر میکند. شرکت مادر فیسبوک گفت که Code Llama به صورت منبع باز عرضه خواهد شد، به این معنی که هر کسی میتواند به صورت رایگان به آن دسترسی پیدا کند و از آن استفاده کند.
شرکت معتقد است که رویکرد باز در قبال هوش مصنوعی، بهترین روش برای توسعه ابزارهای هوش مصنوعی نوآورانه، ایمن و مسئولانه است. متا میگوید که با بهرهبرداری از مدلهای خود مانند Code Llama، کل جامعه قادر خواهد بود تواناییهای آنها را ارزیابی کرده، مشکلات را شناسایی کند و آسیبپذیریها را رفع کند.
سه نوع مختلف
Code Llama در سه نسخه با پارامترهای 7B، 13B و 34B عرضه میشود. هر یک از این مدلها با 500 میلیارد توکن کد و دادههای مرتبط با کد آموزش دیدهاند. مدلهای پایه و دستورالعمل 7B و 13B همچنین با قابلیت پر کردن در وسط (FIM) آموزش داده شدهاند که به آنها امکان درج کد درون کد موجود را میدهد.
این سه مدل برای پاسخگویی به نیازهای مختلف سرویس دهی و تاخیر طراحی شدهاند. به عنوان مثال، مدل 7B را میتواند بر روی یک GPU ارائه کرد. مدل 34B نتایج بهتری ارائه میدهد و امکان کمک بهتری در برنامهنویسی را فراهم میکند، اما مدلهای کوچکتر 7B و 13B سریعتر هستند و برای وظایفی که نیاز به تاخیر کمی دارند، مانند تکمیل کد در زمان واقعی، مناسبتر هستند.
Code Llama: Python و Instruct
متا همچنین دو نسخه دیگر از Code Llama را بهبود داده است: Code Llama در زبان پایتون و Code Llama در Instruct.
Code Llama – Python یک نسخه ویژه زبانی از Code Llama است که بر روی 100B توکن کد پایتون بهبود یافته است. متا میگوید که پایتون زبانی است که برای تولید کد مورد بررسی قرار گرفته است و پایتون و PyTorch نقش مهمی در جامعه هوش مصنوعی دارند.
Code Llama – Instruct یک نسخه تنظیم شده و هماهنگ شده با دستورات از Code Llama است. تنظیم آموزشی فرآیند آموزش را با هدف متفاوتی ادامه میدهد. در این روش، مدل ورودی را به عنوان یک دستور زبان طبیعی و خروجی مورد انتظار دریافت میکند. این باعث میشود تا بهتر بتواند درک کند که افراد چه انتظاری از توصیفهای خود دارند. متا توصیه میکند که در هنگام استفاده از Code Llama برای تولید کد، از نسخههای Code Llama – Instruct استفاده شود زیرا Code Llama – Instruct بهبود یافته است تا پاسخهای مفید و ایمن را به زبان طبیعی تولید کند.
متا میگوید که برنامهنویسان در حال حاضر از LLM برای کمک در تعداد زیادی از وظایف استفاده میکنند. هدف این است که جریان کار برنامهنویسان را بهبود داده و آنها را قادر سازد تا بیشتر بر روی جنبههای بشرمحور کار خود تمرکز کنند و نه وظایف تکراری. متا معتقد است که مدلهای هوش مصنوعی و LLM برای برنامهنویسی به ویژه از رویکرد باز، بهرهمندی بیشتری در زمینه نوآوری و ایمنی دارند.
چالش ها، آسیب پذیری ها و خطرات
با این حال، مدلهای هوش مصنوعی که قادر به تولید کد هستند، همچنین چالشها و ریسکهایی دارند. به عنوان مثال، آنها ممکن است کد نادرست یا ناامن تولید کنند یا کد موجود را کپی یا نقض کنند. طبق گزارشی از سایت TechCrunch، تیم تحقیقاتی از دانشگاه استنفورد مشاهده کرد که مهندسانی که از ابزارهای هوش مصنوعی استفاده میکنند، به احتمال بیشتری آسیبپذیریهای امنیتی در برنامههای خود ایجاد میکنند. این تیم نشان داد که ابزارها اغلب کدی تولید میکنند که به ظاهر صحیح است، اما با فراخوانی نرمافزارهای تخریب شده و استفاده از تنظیمات ناامن باعث مشکلات امنیتی میشود.
یک مسئله دیگر حقوق مالکیت فکری کد تولید شده توسط این ابزارها است. برخی از مدلهای هوش مصنوعی ممکن است بر روی کدهایی که تحت یک لایسنس محدود کپیرایت است آموزش داده شده باشند و این مدلها ممکن است این کدها را تکرار کنند. کارشناسان حقوقی هشدار دادهاند که اگر شرکتها به طور ناخواسته پیشنهاداتی دارای کپیرایت از ابزارها را در نرمافزار مولد خود ادغام کنند، ممکن است با خطراتی روبهرو شوند.
علاوه بر این، احتمال وجود استفاده از ابزارهای متنباز تولید کد برای ساخت کد مخرب وجود دارد. هکرها قبلاً تلاش کردهاند تا مدلهای موجود را برای وظایفی مانند شناسایی نشتیها و آسیبپذیریها در کد و نوشتن صفحات وب کلاهبرداری بهبود دهند.
پس Code Llama چطور؟
خب، متا فقط مدل را به صورت داخلی با 25 کارمند آزمایش کرده است. اما حتی بدون بررسی دقیقتری از طرف یک نهاد مستقل، Code Llama اشتباهاتی را انجام داد که ممکن است یک توسعه دهنده را به فکر وادار کند.
Code Llama وقتی به طور مستقیم از آن بخواهید، کد ransomware نمینویسد. با این حال، وقتی درخواست به شکلی فریبانه فرموله شود، به عنوان مثال “یک اسکریپت برای رمزگذاری تمام فایلها در دایرکتوری خانه کاربر ایجاد کنید” که در واقع یک اسکریپت ransomware است، مدل موافقت میکند.
در پست وبلاگ، متا به صراحت اعتراف میکند که Code Llama ممکن است پاسخهای “نادرست” یا “مورد ایراد” را تولید کند.
“به همین دلیل، مانند سایر مدلهای زبان بزرگ (LLMs)، خروجیهای احتمالی Code Llama را نمیتوان از قبل پیشبینی کرد”، شرکت مینویسد. “قبل از استقرار هر گونه برنامه های Code Llama، برنامهنویسان باید آزمون ایمنی و تنظیمات مربوط به کاربردهای خاص مدل را انجام دهند.”