محققان مایکروسافت از طراحی یک مدل جدید هوش مصنوعی تبدیل متن به گفتار به نام VALL-E خبر دادند که میتواند صدای یک فرد را با استفاده از یک نمونه صوتی سه ثانیهای شبیهسازی کند.
به گزارش تکناک، زمانی که VALL-E صدای خاصی را یاد گرفت، میتواند صدای آن شخص را با حفظ لحن گوینده تقلید کند.
سازندگان آن حدس میزنند که VALL-E میتواند برای برنامههای کاربردی تبدیل متن به گفتار با کیفیت بالا، ویرایش صداهای ضبط شده و ایجاد محتوای صوتی در صورت ترکیب با سایر مدلهای هوش مصنوعی مانند GPT-3 استفاده شود.
مایکروسافت Vall-E را مدل زبان کدک عصبی می نامد و آن را از فناوری به نام EnCodec که متا در اکتبر 2022 عرضه کرد، ساخته است.
برخلاف سایر روش های تبدیل متن به گفتار که معمولا گفتار را با دستکاری شکل موج ترکیب می کند، VALL-E کدک های صوتی گسسته را از متن و پیام های صوتی تولید می کند.
Vall-E اساسا صدای یک شخص را تجزیه تحلیل می کند، اطلاعات را به نشانه های صوتی که توکن صوتی نامیده می شوند به لطف EnCodec تجزیه می کند، و از داده های آموزشی برای مطابقت با آنچه می داند برای تقلید صدا استفاده می کند .
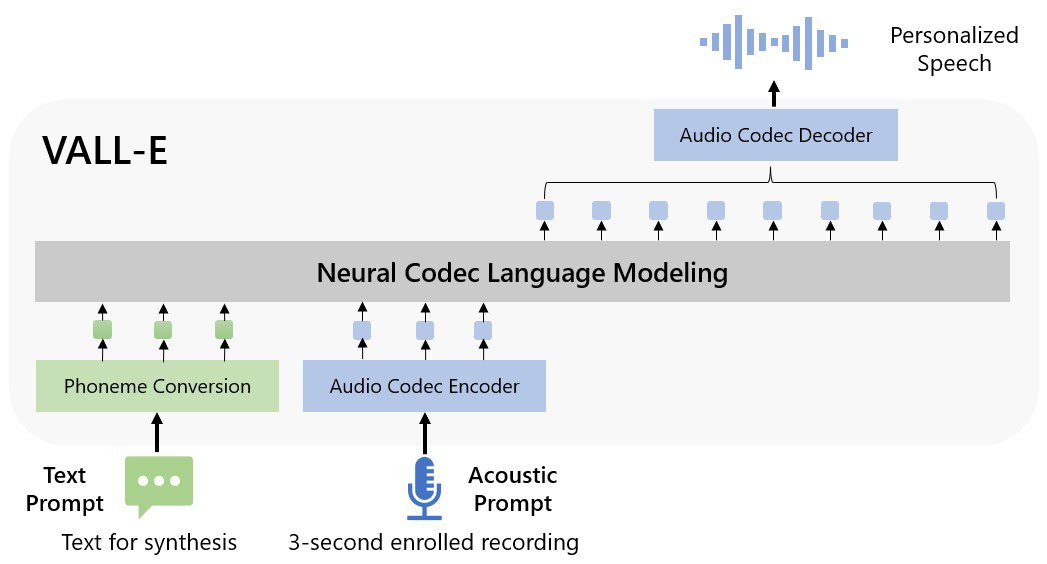
Microsoft (American multinational technology corporation) در مقاله خود بیان می کند:VALL-E برای ترکیب گفتار شخصی شده (مثلاً (zero-shot TTS توکنهای صوتی مربوطه را مشروط به نشانههای صوتی ضبط ثبتشده 3 ثانیهای از صدای سخنران و اعلان واج ایجاد میکند .در نهایت، توکن های آکوستیک تولید شده برای سنتز شکل موج نهایی با رمزگشای کدک عصبی مربوطه استفاده می شود.
مایکروسافت قابلیت های سنتز گفتار VALL-E را بر روی یک کتابخانه صوتی که توسط متا مونتاژ شده بود، به نام LibriLight آموزش داد. این شامل 60هزار ساعت سخنرانی به زبان انگلیسی از بیش از 7000 سخنران است که عمدتاً از کتابهای صوتی عمومی LibriVox استخراج شده است. برای اینکه VALL-E نتیجه خوبی ایجاد کند، صدای نمونه سه ثانیهای باید دقیقاً با صدای دادههای آموزشی مطابقت داشته باشد.
در وبسایت نمونه VALL-E، مایکروسافت دهها نمونه صوتی از مدل هوش مصنوعی در عمل ارائه میدهد. در بین نمونهها، «Speaker Prompt» صدای سه ثانیهای است که در اختیار VALL-E قرار گرفته و باید از آن تقلید کند.
” Ground Truth ” یک صدای ضبط شده از قبل موجود از همان گوینده است که یک عبارت خاص را برا مقایسه بیان می کند.
“Baseline” نمونه ای از سنتز است که با روش سنتز متن به گفتار مرسوم ارائه می شود و نمونه “VALL-E” خروجی از مدل VALL-E است.
محققان در حالی که از VALL-E برای تولید آن نتایج استفاده میکردند، تنها نمونه سه ثانیهای “Speaker Prompt” و یک رشته متن را به VALL-E وارد کردند. اگر نمونه « Ground Truth » را با نمونه «VALL-E» مقایسه کنید، در برخی موارد، این دو نمونه بسیار نزدیک هستند. برخی از نتایج VALL-E به نظر میرسد که توسط رایانه تولید شدهاند، اما برخی دیگر به طور بالقوه میتوانند با گفتار انسان اشتباه گرفته شوند، که هدف این مدل است.
VALL-E علاوه بر حفظ صدای صوتی و لحن احساسی گوینده، می تواند از نمونه صوتی “محیط آکوستیک” نیز تقلید کند. برای مثال، اگر نمونه از یک تماس تلفنی گرفته شده باشد، خروجی صدا ویژگیهای صوتی و فرکانس یک تماس تلفنی را در خروجی ترکیبی خود شبیهسازی میکند .
محققان مایکروسافت شاید به دلیل قابلیت استفاده برای مقاصد بد ، کد VALL-E را برای آزمایش به دیگران ارائه نکرده است،و به نظر می رسد محققان سازنده آن از آسیب اجتماعی بالقوه ای که این فناوری می تواند به همراه داشته باشد آگاه هستند.