در حوزه ریاضیات، نمیتوان به مدلهای زبانی بزرگ (LLM) کاملاً اعتماد کرد. در این مطلب، توضیح میشود که چرا مدلهای زبانی بزرگ در ریاضیات ضعف دارند.
بهگزارش تکناک، هنگام بررسی مدلهای زبانی بزرگ (LLM)، ممکن است تصور کنید که آنها راهحلی جادویی برای بیشتر مشکلات شما هستند. آنها را میتوان برای برنامهریزی روزانه یا مطرحکردن انواع سؤالات بهکار برد، با این امید که به بهترین نحو ممکن به شما پاسخ میدهند. بااینهمه، یک حوزه وجود دارد که نباید بهطور کامل به LLMها اعتماد کرد: ریاضیات.
بهطور خاص، درحالیکه LLMها میتوانند الگوهای ریاضی را از دادههای وسیع یاد بگیرند و با اعداد کوچکتر به نتایج دقیقتری برسند، همچنان به پای محاسبات ماشینحساب نمیرسند. این ضعف بارز در محاسبات ریاضی LLMها قبلاً در تحقیقات و مقالاتی مانند «GPT میتواند مسائل ریاضی را بدون ماشینحساب حل کند”» بررسی شده است.
دانشگاه Tsinghua مدلی به نام MathGLM را معرفی کرد که برای حل مسائل ریاضی آموزش دیده و نشان داده شده است که دقت زیادی دارد. این مدل درمقایسهبا GPT-4 و ChatGPT عملکرد بهتری دارد.

همانطورکه از محاسبات بالا مشخص است، MathGLM عملکرد بهتری از هر دو GPT-4 و ChatGPT دارد. بااینحال، مشکل موجود این است که حتی با محاسبات پنجرقمی، بهترین نتیجهای که میتوانید از مدلی با ۲ میلیارد پارامتر دریافت کنید، دقت ۸۵.۱۶درصد است. بدون توجه به هرچیزی، ۱۰,۰۰۰×۵ همچنان ۵۰,۰۰۰ است و اگر LLM به آن نزدیک شود؛ ولی دقیقاً همان نباشد، پس همچنان جواب اشتباه است. ماشینحساب همهی این مشکلات را با دقت ۱۰۰ درصد در هر زمانی حل خواهد کرد.
با افزایش اندازه اعداد، دقت کاهش مییابد که احتمالاً بهدلیل تمرکز بر محاسبات کوچکتر در دادههای آموزشی است. مدلها واقعاً در حال انجام محاسبات نیستند؛ بلکه در حال شناسایی الگوها هستند. برای استفاده از MathGLM میتوانید به GitHub تیم مراجعه کنید؛ اما اجرای آن نیازمند کامپیوتری قدرتمند است.
درمقابل، گوگل با FunSearch خود که LLM پیشآموزشدیدهای را با ارزیاب خودکار ترکیب میکند تا اشتباهات را کاهش دهد، موفقیتهایی را کسب کرده است. این روش به LLMها اجازه میدهد تا ضمن حفظ خلاقیت، از انحرافات بیشازحد جلوگیری کنند. درحالیکه LLMها در ریاضیات ضعیف هستند، در ایجاد ایدههای خلاقانه برتری دارند.
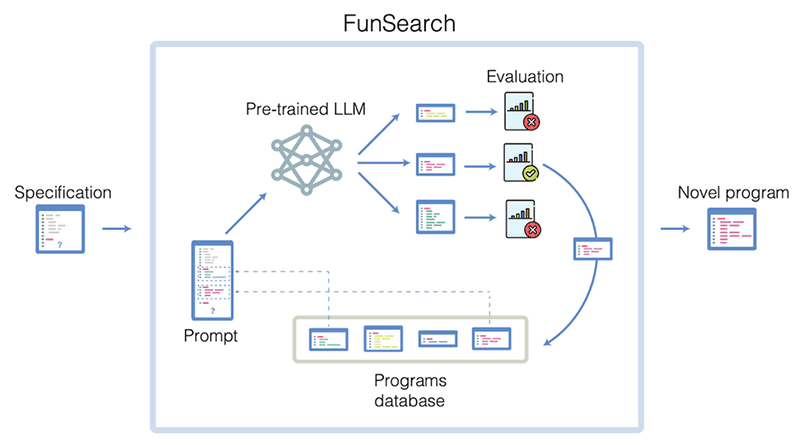
FunSearch رویکردی جدید از گوگل است که با استفاده از توضیحات مسائل ریاضی بهشکل کد کار میکند. این توضیحات بهعنوان اساسی برای ارزیابی خروجیها و ایجاد مجموعهای اولیه از برنامهها عمل میکنند. در هر تکرار، FunSearch برخی از برنامهها را انتخاب و به LLM مانند PaLM 2 ارائه میدهد تا برنامههای جدیدی ایجاد کند. بهترینها برای بهبود مداوم انتخاب میشوند.
FunSearch در یافتن بزرگترین مجموعههای cap موفق بود که از بهترینهای شناختهشده برخی از دانشمندان برجسته جهان فراتر رفت. طبق مقالهای در Nature، این ممکن است اولین کشف علمی باشد که LLM به آن نائل شده است.
گوگل با FunSearch نشان داده که LLMها میتوانند ابزارهای قدرتمندی برای ریاضیات باشند؛ اما نه بهتنهایی. با ترکیب خلاقیت LLMها با ارزیابهای دقیق، میتوان به حل مسائل پیچیده و تولید ایدههای نوآورانه پرداخت. این نمایانگر توانایی LLMها در ریاضی نیست؛ بلکه بیشتر مهارت مهندسان در هدایت آنها بهسمت نتایج دقیق و معنادار است.
وقتی از مدلی زبان بزرگ (LLM) مانند ChatGPT یا بارد میخواهید مفهوم ریاضی را شرح دهد (مثلاً نحوه ضرب دو ماتریس)، معمولاً میتوانید انتظار داشته باشید که توضیحات دقیق و صحیحی دریافت کنید. این مدلها در تشریح مفاهیم و فرایندهای نظری تبحر دارند و میتوانند اطلاعات مرتبط را به شیوهای مفهوم ارائه دهند.
بااینحال، وقتی میخواهید که LLMها بهطور خودکار محاسبات را انجام دهند (مثلاً ضرب دو ماتریس واقعی)، دقتشان ممکن است کاهش یابد. این اغلب بهدلیل محدودیتها و مسائل درک متن و ساختار دادههای ریاضی بهواسطه این مدلهاست. ممکن است ابعاد نادرستی را محاسبه کنند یا در مراحل محاسبه اشتباهاتی ایجاد شوند.
بنابراین، اگر قصد دارید از LLMها برای کمک در ریاضیات استفاده کنید، بهتر است از آنها برای فهمیدن مفاهیم نظری و فرایندهای حل مسئله استفاده کنید؛ ولی برای محاسبات واقعی و دقیق، بهتر است خودتان آنها را انجام دهید یا از ابزارهای مخصوص محاسبه استفاده کنید.
حتی اگر پاسخ در مجموعه دادههای آموزشی مدل باشد، همیشه امکان خطا وجود دارد. درنهایت، یادگیری و انجام محاسبات خودتان، بهترین رویکرد برای دقت و درک عمیقتر است.