
فهرست مطالب
AMD مدل زبان بزرگ (LLM) جدید خود به نام OLMo را معرفی کرده است. این اولین مدل با ۱ میلیارد پارامتر است و توانایی استدلال قوی دارد.
به گزارش تکناک، AMD از مدل زبان بزرگ (LLM) جدید خود به نام OLMo پرده برداشت. این مدل بهطور کامل متنباز و با ۱ میلیارد پارامتر طراحی شده است. OLMo با استفاده از پردازندههای گرافیکی Instinct MI250 شرکت AMD آموزش دیده و برای طیف وسیعی از کاربردها در نظر گرفته شده است و با قابلیتهای استدلال پیشرفته و پیروی از دستورها و چت ارائه میشود.
تامزهاردور مینویسد که مدل متنباز OLMo نهتنها موقعیت AMD در صنعت هوش مصنوعی را بهبود میبخشد؛ بلکه به کاربران امکان میدهد تا با استفاده از سختافزارهای AMD این مدلها را بهراحتی پیادهسازی کنند. AMD با انتشار متنباز دادهها، وزنها، دستورالعملهای آموزشی و کدها، تلاش میکند تا به توسعهدهندگان اجازه دهد علاوهبر بازتولید این مدلها، از آنها برای نوآوری بیشتر بهرهبرداری کنند.
افزونبر این، تیم قرمز امکان اجرای محلی مدلهای OLMo را روی کامپیوترهای شخصی AMD Ryzen AI مجهز به واحدهای پردازش عصبی (NPU) فراهم کرده است تا کاربران بتوانند از این مدلهای هوش مصنوعی در دستگاههای شخصی خود استفاده کنند.
01
از 03آموزش چندمرحلهای مدلهای OLMo
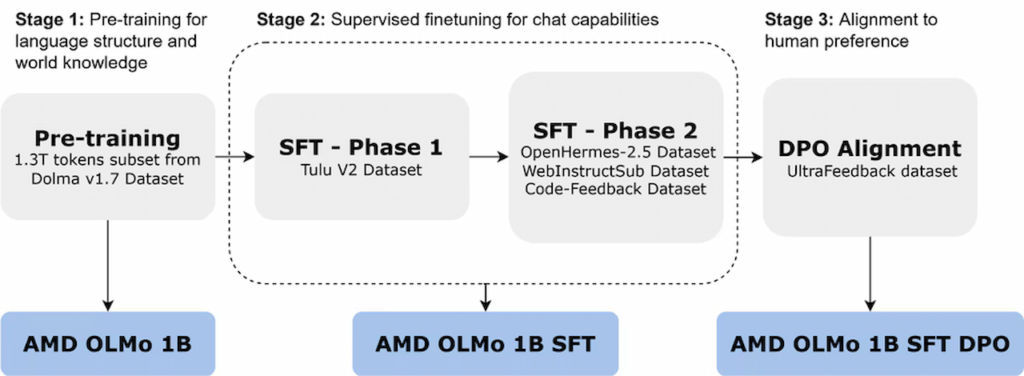
مدلهای AMD OLMo با استفاده از مجموعهداده گسترده شامل ۱/۳ تریلیون توکن و روی ۱۶ گره (هرکدام با چهار پردازنده گرافیکی AMD Instinct MI250) آموزش دیدهاند. این مدلها در سه مرحله مختلف آموزش داده شدهاند.
نسخه اولیه AMD OLMo 1B براساس زیرمجموعهای از دادههای Dolma v1.7 طراحی شده و مدل رمزگشای سادهای است که بر پیشبینی توکن بعدی تمرکز دارد. نسخه دوم این مدل بهصورت نظارتشده بهینهسازی شده (SFT) و ابتدا با مجموعهداده Tulu V2 و سپس روی مجموعه دادههای دیگری مانند OpenHermes-2.5 و WebInstructSub برای بهبود عملکرد در پیروی از دستورها و وظایفی مانند برنامهنویسی، علم و ریاضی آموزش دیده است.
در نهایت، AMD با استفاده از روش بهینهسازی ترجیحات مستقیم (DPO) مدل SFT را با دادههای UltraFeedback به ترجیحات انسانی همتراز کرده و نسخه نهایی OLMo 1B SFT DPO را عرضه کرده است که خروجیهای همسو با بازخورد انسانی ارائه میدهد.
02
از 03عملکرد مدلهای OLMo در آزمونها
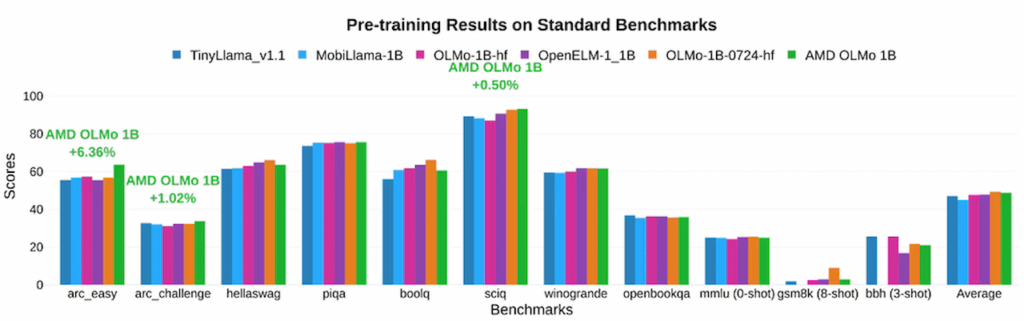
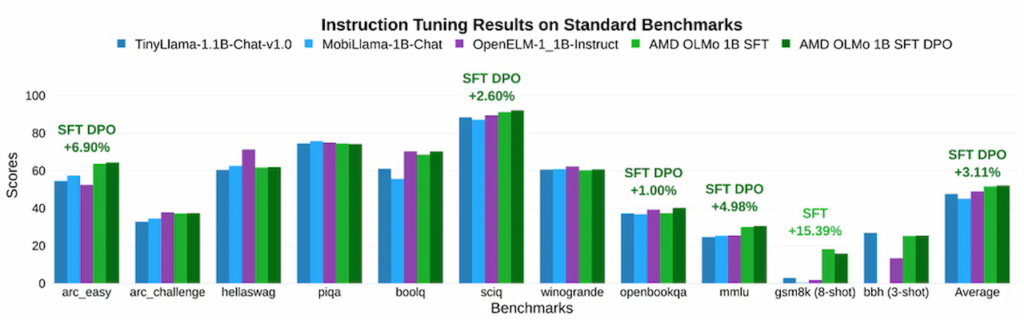
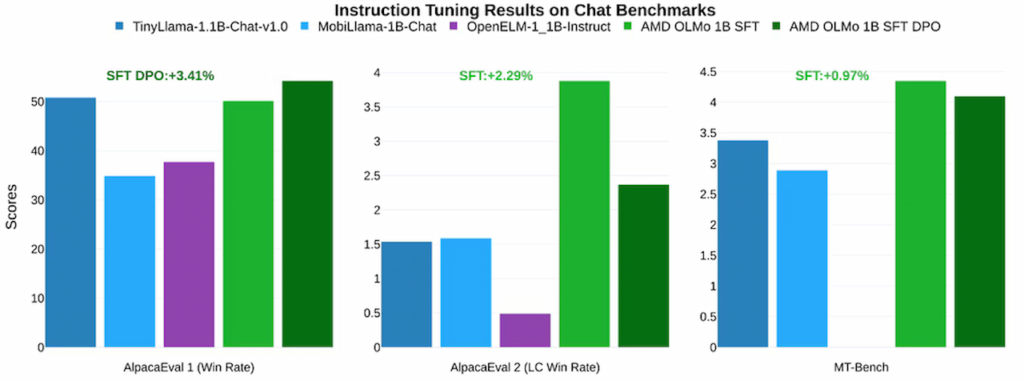
در آزمونها، مدلهای OLMo AMD عملکرد قدرتمندی در مقایسه با مدلهای متنباز مشابه نظیر TinyLlama-1.1B و MobiLlama-1B از خود نشان دادهاند. مدل SFT دومرحلهای موفق به بهبود چشمگیری در دقت شده و امتیازات معیارهایی نظیر MMLU را ۵/۰۹ درصد و GSM8k را ۱۵/۳۲ درصد افزایش داده است که نشاندهنده تأثیر مثبت رویکرد آموزشی AMD است. مدل نهایی AMD OLMo 1B SFT DPO نیز بهطور متوسط ۲/۶۰ درصد از سایر مدلهای متنباز چت در معیارهای مختلف پیشی گرفته است.
03
از 03تعهد به هوش مصنوعی مسئولیتپذیر
AMD مدلهای OLMo را در آزمونهای هوش مصنوعی مسئولیتپذیر شامل ToxiGen (ارزیابی زبان توهینآمیز) و crows_pairs (ارزیابی تعصب) و TruthfulQA-mc2 (بررسی صداقت پاسخها) نیز بررسی کرده است. نتایج نشان میدهند که این مدلها در مواجهه با وظایف اخلاقی و مسئولیتپذیر، عملکردی همتراز با سایر مدلهای متنباز مشابه دارند و از استانداردهای اخلاقی هوش مصنوعی پیروی میکنند.
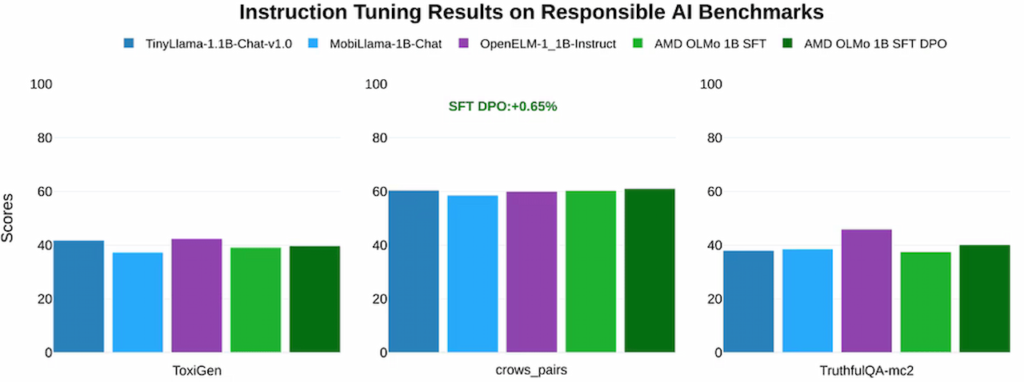
AMD با معرفی مدلهای OLMo، گامی بزرگ بهسوی توسعه هوش مصنوعی متنباز و در دسترس برای عموم برداشته و در عین حال بر تعهد خود به ارتقای نوآوری و کاربردپذیری مدلهای هوش مصنوعی برای جامعه توسعهدهندگان تأکید کرده است.



















