
پژوهشگران شرکت اپل اعلام کردهاند که مدلهای استدلالی هوش مصنوعی (Reasoning Models) به اندازهای که تبلیغ میشود، «هوشمند» نیستند.
به گزارش تکناک، مدلهای استدلالی، مانند Claude متعلق به شرکت Anthropic، o3 از OpenAI و R1 از DeepSeek، نسل پیشرفتهتری از مدلهای زبانی بزرگ (LLMs) هستند که برای دستیابی به دقت بالاتر، از توان محاسباتی و زمان بیشتری استفاده میکنند.
رشد این مدلها باعث شد شرکتهای بزرگ فناوری مجدد ادعا کنند که ممکن است در آستانه توسعه هوش عمومی مصنوعی (AGI) باشند؛ سیستمهایی که از انسان در اغلب وظایف پیشی میگیرند. اما مطالعه جدیدی که در تاریخ ۷ ژوئن در وبسایت تحقیقاتی اپل منتشر شده، ضربهای جدی به این ادعاها وارد کرده است. پژوهشگران میگویند که مدلهای استدلالی نهتنها توانایی استدلال عمومی را نشان نمیدهند، بلکه با پیچیدهتر شدن وظایف، دقت آنها بهطور کامل فرو میریزد.
محققان اپل در این زمینه گفتند:
«از طریق آزمایشهای گسترده روی معماهای متنوع، نشان دادیم که مدلهای پیشرفته استدلالی در برابر پیچیدگیهای بالا دچار فروپاشی کامل در دقت میشوند. همچنین آنها یک محدودیت مقیاسی متناقض از خود نشان میدهند: تلاش برای استدلال با افزایش پیچیدگی مسائل تا حدی افزایش مییابد، سپس کاهش پیدا میکند؛ این موضوع حتی با وجود تخصیص مناسب از توکنها دیده میشود.»
مدلهای زبانی بزرگ از طریق جذب حجم انبوهی از دادههای انسانی آموزش میبینند و با استخراج الگوهای آماری از این دادهها، به تولید پاسخ میپردازند. در مدلهای استدلالی، از روش «زنجیره فکر» (Chain-of-Thought) برای بهبود دقت استفاده میشود؛ یعنی مدل گامبهگام منطق خود را بیان میکند تا مانند انسان به نتیجه برسد.
اما این روند، برخلاف تصور، مبتنی بر «درک واقعی» نیست، بلکه صرفاً بر پایه حدسهای آماری است. همین مسئله باعث میشود که این مدلها دچار پدیدهای موسوم به «توهمزایی» شوند؛ یعنی پاسخهای اشتباه، گمراهکننده یا حتی خطرناک تولید کنند.
گزارشی فنی از OpenAI نشان میدهد که مدلهای استدلالی هوش مصنوعی نسبت به مدلهای عمومی، بیشتر مستعد توهمزایی هستند. به عنوان مثال، مدلهای o3 و o4-mini هنگام خلاصهسازی اطلاعات درباره افراد، به ترتیب در ۳۳ و ۴۸ درصد مواقع دچار خطا شدند، در حالی که این نرخ در مدل o1 تنها ۱۶ درصد بود. خود OpenAI نیز اذعان دارد که دلیل این مسئله روشن نیست و «نیاز به تحقیقات بیشتر» دارد.
در ادامه مطالعه اپل آمده است: «ما معتقد هستیم که فقدان تحلیلهای سیستماتیک درباره این پرسشها، به محدودیتهای الگوهای ارزیابی فعلی بازمیگردد. آزمونهای موجود عمدتاً بر سنجههای ریاضی و کدنویسی متمرکز هستند، که علاوه بر آلودگیهای دادهای، امکان کنترل شرایط تجربی را فراهم نمیکنند.»
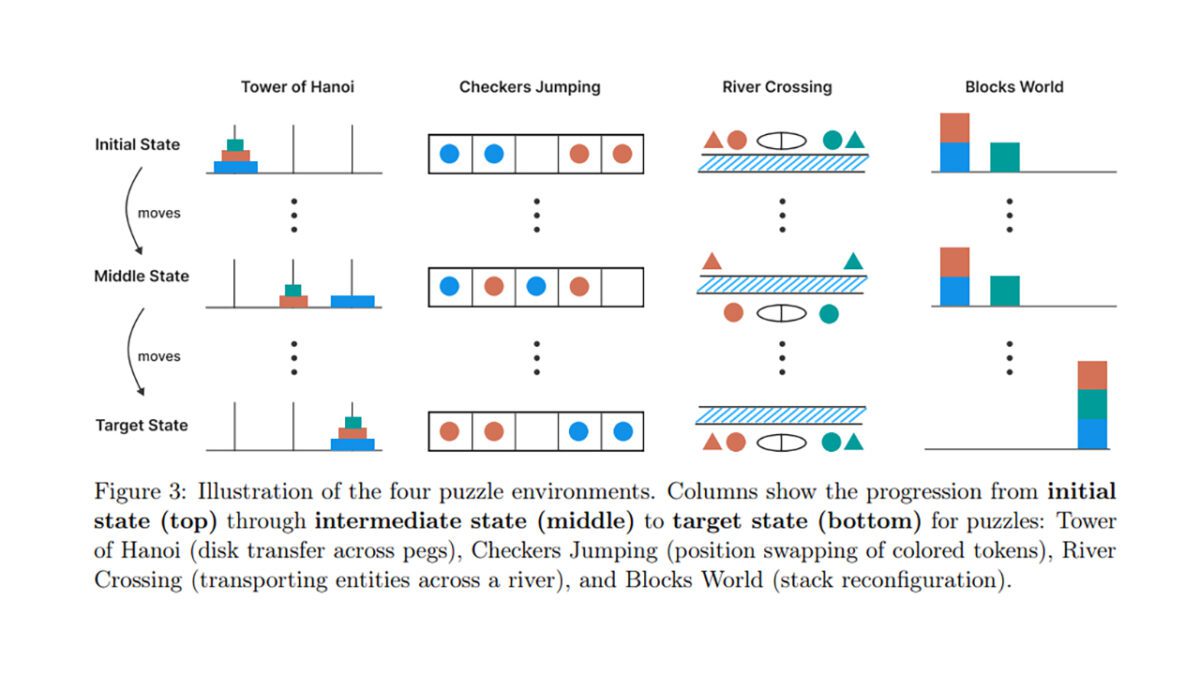
پژوهشگران اپل برای بررسی دقیقتر، مجموعهای از مدلهای عمومی و استدلالی (از جمله o1، o3، Claude 3.7، R1، Gemini) را روی چهار معمای کلاسیک آزمایش کردند، که شامل عبور از رودخانه، پرش مهرهها، چیدن بلوکها و برج هانوی بود. سطح پیچیدگی این معماها نیز در سه سطح تنظیم شده بود.
مدلهای عمومی در سطح پایین، عملکرد بهتری داشتند، چرا که زنجیرههای استدلالی مدلهای پیشرفته، هزینه محاسباتی بیشتری داشتند. با افزایش پیچیدگی، مدلهای استدلالی برای مدتی برتری پیدا کردند، اما در نهایت، در مواجهه با مسائل بسیار پیچیده، عملکرد هر دو گروه «به صفر رسید».
پژوهشگران مشاهده کردند که پس از عبور از یک آستانه مشخص، مدلهای استدلالی هوش مصنوعی حتی تعداد توکنهای اختصاصدادهشده را کاهش دادند و زنجیره استدلال را رها کردند؛ حتی در حالتی که پاسخ صحیح در اختیار آنها قرار گرفت. برای مثال، مدلها در معمای برج هانوی توانستند تا ۱۰۰ حرکت درست انجام دهند، اما در معمای عبور از رودخانه، بیش از ۵ حرکت صحیح نداشتند.
نتایج نشان میدهد که این مدلها بیشتر به شناسایی الگو متکی هستند. با وجود این، پژوهشگران اپل نیز به محدودیتهای پژوهش خود اذعان دارند و تأکید کردهاند که دامنه معماها، نماینده کامل تمام وظایف ممکن نیست.
شرکت اپل نیز در رقابت هوش مصنوعی از رقبا عقب افتاده است. طبق یک بررسی، سیری، دستیار صوتی اپل، ۲۵ درصد کمدقتتر از ChatGPT گزارش شده و اپل به جای تمرکز بر مدلهای عظیم، بر توسعه هوش مصنوعی کارآمد و مبتنی بر پردازش دروندستگاهی متمرکز شده است.
برخی این رویکرد را به دیده طعنه نگریستهاند. پدروس دومینگوس، استاد بازنشسته دانشگاه واشنگتن، در پستی در X نوشت: «استراتژی جدید و درخشان اپل برای هوش مصنوعی این است که ثابت کند اصلاً وجود ندارد!»
با وجود این، برخی پژوهشگران این مطالعه را به عنوان زنگ هشدار مهمی در برابر ادعاهای اغراقآمیز در مورد هوش مصنوعی ارزیابی کردهاند. آندری بوروکوف، کارشناس هوش مصنوعی و رهبر پیشین تیم یادگیری ماشین در شرکت گارتنر در X نوشت: «اپل با انتشار مقالهای داوریشده نشان داد که مدلهای زبانی بزرگ، صرفاً شبکههای عصبی هستند و تمام محدودیتهای همین شبکهها را دارند. شاید حالا دوباره به مسیر علم واقعی بازگردیم؛ مدلها را نه مانند یک روانشناس بلکه مانند ریاضیدان مطالعه کنیم.»



















