
شرکت OpenAI روز سهشنبه از عرضهی دو مدل استدلال هوش مصنوعی با وزن باز خبر داد که از نظر توانایی با مدلهای سری o این شرکت مشابه هستند.
به گزارش تکناک، هر دو مدل بهصورت رایگان از پلتفرم توسعهدهندگان Hugging Face قابل دانلود هستند و براساس چندین معیار سنجش مدلهای باز، «در سطح پیشرفته» ارزیابی شدهاند.
این مدلها در دو اندازه عرضه شدهاند: مدل بزرگتر و قدرتمندتر gpt-oss-120b که قابلیت اجرا روی یک کارت گرافیک انویدیا را دارد، و مدل سبکتر gpt-oss-20b که روی لپتاپهای مصرفی با حافظهی ۱۶ گیگابایتی اجرا میشود.
تککرانچ مینویسد که در یک جلسهی توجیهی، OpenAI اعلام کرد که مدلهای باز این شرکت قادر خواهند بود پرسشهای پیچیده را به مدلهای هوش مصنوعی ابری ارسال کنند؛ همانطور که TechCrunch نیز پیشتر گزارش داده بود. این یعنی اگر مدل باز OpenAI قادر به انجام وظیفهای خاص مانند پردازش تصویر نباشد، توسعهدهندگان میتوانند آن را به یکی از مدلهای بسته و قدرتمندتر این شرکت متصل کنند.
در حالیکه OpenAI در روزهای آغازین خود مدلهای هوش مصنوعی را بهصورت متنباز ارائه میداد، اما در سالهای اخیر رویکردی مالکانه و بسته را در توسعهی مدلها در پیش گرفته است. این استراتژی به OpenAI کمک کرده تا کسبوکاری بزرگ در فروش دسترسی به مدلهای هوش مصنوعی از طریق API برای شرکتها و توسعهدهندگان ایجاد کند.
با این حال، مدیرعامل شرکت سم آلتمن در ژانویه اظهار کرد که OpenAI از نظر متنباز بودن فناوریهایش «در سوی نادرست تاریخ» قرار گرفته است. این شرکت امروز با فشار فزایندهای از سوی آزمایشگاههای هوش مصنوعی چینی مانند DeepSeek، Qwen متعلق به Alibaba و Moonshot AI روبهروست که چندین مدل باز پیشرفته و محبوب را توسعه دادهاند. (در حالیکه Meta پیشتر در حوزهی مدلهای باز پیشتاز بود، مدلهای Llama این شرکت در سال گذشته از رقابت عقب ماندهاند.)
در ماه ژوئیه، دولت ترامپ نیز از توسعهدهندگان آمریکایی خواست فناوریهای بیشتری را متنباز کنند تا پذیرش جهانی هوش مصنوعی منطبق با ارزشهای آمریکایی تقویت شود.
با عرضهی gpt-oss، OpenAI امیدوار است نظر مساعد توسعهدهندگان و دولت ترامپ را جلب کند؛ دو گروهی که شاهد اوجگیری آزمایشگاههای هوش مصنوعی چینی در فضای متنباز بودهاند.

سم آلتمن، مدیرعامل OpenAI در بیانیهای که با TechCrunch به اشتراک گذاشته، گفت: «از زمانی که در سال ۲۰۱۵ شروع کردیم، مأموریت OpenAI این بوده که AGI در خدمت همهی بشریت قرار گیرد. از اینرو، ما از اینکه جهان در حال ساختن پشتهی باز هوش مصنوعی مبتنی بر ایالات متحده و ارزشهای دموکراتیک است که برای همه رایگان و در دسترس باشد، هیجانزده هستیم.»
OpenAI قصد داشته مدل باز خود را در صدر مدلهای باز هوش مصنوعی قرار دهد و مدعی است که به این هدف دست یافته است.
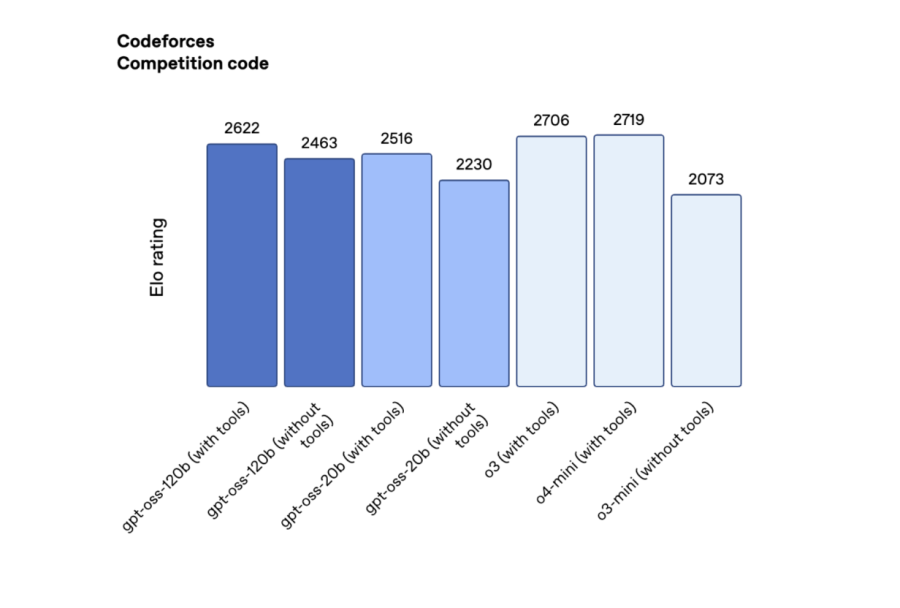
در آزمون برنامهنویسی رقابتی Codeforces (با ابزار)، مدلهای gpt-oss-120b و gpt-oss-20b به ترتیب امتیاز ۲۶۲۲ و ۲۵۱۶ کسب کردهاند که بهتر از مدل R1 شرکت DeepSeek است، اما از مدلهای o3 و o4-mini ضعیفتر عمل میکند.
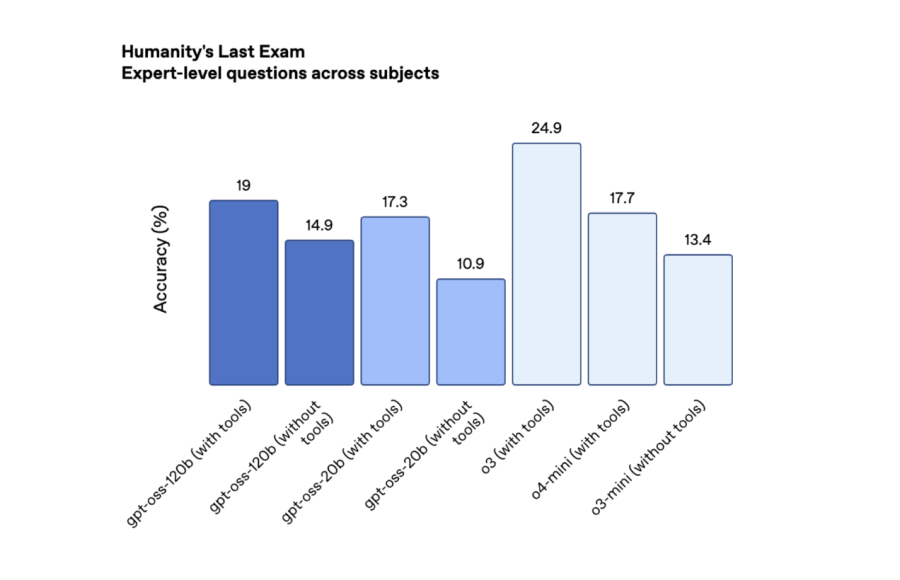
در آزمون دشوار Humanity’s Last Exam که شامل پرسشهای جمعسپاریشده از حوزههای مختلف است (با ابزار)، این دو مدل به ترتیب ۱۹٪ و ۱۷.۳٪ امتیاز کسب کردند. این نتایج نیز پایینتر از o3 است، اما از مدلهای پیشتاز DeepSeek و Qwen بهتر است.
قابل توجه است که مدلهای باز OpenAI نسبت به مدلهای پیشرفتهتر o3 و o4-mini، میزان «توهم» بسیار بیشتری دارند. میزان توهم یا hallucination در مدلهای جدید OpenAI رو به افزایش بوده و این شرکت پیشتر گفته که دلیل آن را بهطور کامل درک نکرده است. در یک مقالهی سفید، OpenAI اعلام کرده این موضوع «قابل انتظار» است، زیرا مدلهای کوچکتر از دانش جهانی مدلهای پیشرفته برخوردار نیستند و تمایل بیشتری به تولید اطلاعات نادرست دارند.
OpenAI دریافته که مدلهای gpt-oss-120b و gpt-oss-20b در آزمون PersonQA — معیار اختصاصی شرکت برای سنجش دقت دانش مدل درباره افراد — به ترتیب در ۴۹٪ و ۵۳٪ پرسشها دچار توهم شدهاند. این بیش از سه برابر نرخ توهم مدل o1 است که ۱۶٪ گزارش شده، و حتی از مدل o4-mini نیز که ۳۶٪ بود، بیشتر است.
OpenAI اعلام کرده که مدلهای باز با فرآیندی مشابه مدلهای اختصاصی آموزش داده شدهاند. این شرکت گفته که هر مدل باز از ساختار mixture-of-experts (MoE) استفاده میکند تا در هر پرسش تنها بخشی از پارامترها فعال شود و در نتیجه، عملکرد بهینهتری داشته باشد. برای مدل gpt-oss-120b که دارای ۱۱۷ میلیارد پارامتر کل است، شرکت گفته تنها ۵.۱ میلیارد پارامتر در هر توکن فعال میشود.
همچنین گفته شده که این مدلها با استفاده از reinforcement learning با محاسبات بالا (RL) آموزش داده شدهاند — فرآیندی پس از آموزش اولیه برای آموختن درست و نادرست به مدلهای هوش مصنوعی در محیطهای شبیهسازیشده با بهرهگیری از خوشههای بزرگ کارتهای گرافیک Nvidia. همین روش در آموزش مدلهای سری o نیز استفاده شده و مدلهای باز از همان فرآیند زنجیرهی تفکر بهره میبرند، که در آن برای رسیدن به پاسخ زمان و منابع بیشتری صرف میشود.
در نتیجهی این فرآیند پس از آموزش، OpenAI اعلام کرده که مدلهای باز هوش مصنوعیاش برای استفاده در Agentهای هوش مصنوعی بسیار مناسب هستند و میتوانند ابزارهایی مانند جستوجوی وب یا اجرای کد Python را بهعنوان بخشی از فرآیند استدلال خود فراخوانی کنند. با اینحال، شرکت تصریح کرده که این مدلهای باز فقط متنی هستند و قادر به پردازش یا تولید تصویر و صدا — مانند سایر مدلهای این شرکت — نخواهند بود.
مدلهای gpt-oss-120b و gpt-oss-20b تحت مجوز Apache 2.0 عرضه میشوند که بهطور کلی یکی از آزادترین مجوزها محسوب میشود. این مجوز به شرکتها اجازه میدهد تا از مدلهای باز OpenAI بهصورت تجاری بهرهبرداری کنند، بدون آنکه نیاز به پرداخت هزینه یا دریافت مجوز جداگانه داشته باشند.
با این حال، برخلاف مدلهای کاملاً متنباز ارائهشده توسط آزمایشگاههایی مانند AI2، OpenAI اعلام کرده که دادههای آموزشی مدلهای باز خود را منتشر نخواهد کرد. این تصمیم با توجه به دعاوی حقوقی فعال علیه ارائهدهندگان مدلهای هوش مصنوعی از جمله OpenAI که متهم به استفادهی نادرست از آثار دارای حقنشر در آموزش مدلها هستند، چندان تعجبآور نیست.
OpenAI عرضهی مدلهای باز خود را در ماههای اخیر چندین بار به تعویق انداخته بود، بخشی از این تأخیرها بهدلیل نگرانیهای ایمنی بوده است. افزون بر سیاستهای معمول ایمنی شرکت، OpenAI در مقالهای سفید اعلام کرده که بررسی کرده آیا کاربران مخرب میتوانند با تنظیم مدلهای gpt-oss، آنها را برای حملات سایبری یا ساخت سلاحهای زیستی یا شیمیایی مفیدتر کنند یا خیر.
پس از ارزیابیهای داخلی و بررسیهای انجامشده توسط ارزیابان مستقل، OpenAI اعلام کرده که مدل gpt-oss ممکن است بهصورت جزئی تواناییهای زیستی را افزایش دهد. با این حال، هیچ شواهدی مبنی بر آنکه این مدلها حتی پس از تنظیم مجدد بتوانند به آستانهی «قابلیت بالا» برای خطر در این حوزهها برسند، یافت نشده است.
با وجود آنکه مدل جدید OpenAI در میان مدلهای باز در سطح پیشرفته قرار دارد، توسعهدهندگان اکنون مشتاقانه منتظر عرضهی مدل DeepSeek R2 و نیز مدل باز جدیدی از آزمایشگاه ابرهوش Meta هستند.




















