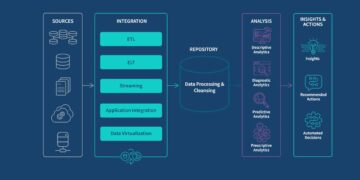
فهرست مطالب
در جهانی که داده به سوخت تصمیمگیری تبدیل شده است، علم داده دیگر یک تخصص لوکس نیست، بلکه ستون فقرات بسیاری از صنایع مدرن است.
اما آنچه علم داده را ممکن میکند، نه فقط تئوری و مدل، بلکه ابزارهایی هستند که دادهکاوان با آنها کار میکنند. از زبانهای برنامهنویسی گرفته تا فریمورکهای یادگیری عمیق، از موتورهای کلانداده تا ابزارهای هوش تجاری، هرکدام نقش خاصی در این اکوسیستم دارند.
شناخت درست ابزارهای علم داده یعنی دانستن اینکه در هر مرحله از چرخه علم داده از جمعآوری و پاکسازی تا تحلیل، مدلسازی و ارائه باید از چه ابزاری استفاده کرد. در این راهنما، مجموعهای از مهمترین ابزارهای دنیای علم داده را مرور میکنیم تا بدانید پایههای این حوزه روی چه فناوریهایی بنا شده است و هرکدام چه نقشی در خلق بینش از دل داده دارند. پس با تکناک و ادامه این مقاله همراه ما باشید.
مرتبط: SQL Server 2025 با امکان پشتیبانی بومی از بردارها
01
از 07زبانهای برنامهنویسی در علم داده (هسته اصلی تحلیل، پردازش و مدلسازی)

پایه و اساس هر پروژه علم داده، زبان برنامهنویسی است. زبانها ابزار برقراری ارتباط بین انسان و ماشیناند؛ ابزاری که به دانشمند داده اجازه میدهد داده را بخواند، تغییر دهد، تحلیل کند و مدل بسازد. سه زبان بیش از همه در قلب پروژههای دادهای حضور دارند: پایتون، R و SQL.
پایتون (Python): پادشاه علم داده
پایتون در دهه اخیر عملاً به زبان جهانی علم داده تبدیل شده است. سادگی، انعطاف و جامعهی کاربری عظیم آن باعث شده تقریباً در تمام مراحل یک پروژه دادهمحور حضور داشته باشد. از پاکسازی داده با کتابخانههایی مانند Pandas و NumPy گرفته تا مدلسازی با Scikit-learn و TensorFlow، پایتون ابزار واحدی برای یک زنجیره کامل تحلیل داده است.
افزون بر این، پایتون از نظر ادغام با فناوریهای دیگر مانند Apache Spark، SQL و ابزارهای ابری نیز جایگاه ویژهای دارد. این زبان به دانشمندان داده اجازه میدهد میان تحلیل آماری، یادگیری ماشین و مصورسازی داده، بدون خروج از یک محیط کاری واحد حرکت کنند. همین جامعیت باعث شده پایتون بهدرستی لقب «پادشاه علم داده» را بگیرد.
مرتبط: ساخت بازی DOOM با SQL

مرتبط: تکنو گوشی هوشمند Spark 30 را معرفی کرد
R: زبان تخصصی آمار
پیش از ظهور گسترده پایتون، زبان R انتخاب اول تحلیلگران آماری بود و هنوز هم در بسیاری از سازمانهای پژوهشی و دانشگاهی جایگاه خود را حفظ کرده است. R بهطور خاص برای تحلیل داده، مدلسازی آماری و مصورسازی توسعه یافته و دارای پکیجهای قدرتمندی مانند ggplot2 و caret است.
هرچند یادگیری R کمی پیچیدهتر از پایتون است، اما در تحلیلهای آماری عمیق و آزمونهای فرضیه عملکردی درخشان دارد. بسیاری از پژوهشگران داده ترکیبی از هر دو زبان را در کار خود بهکار میگیرند؛ پایتون برای انعطاف و مقیاسپذیری، R برای دقت آماری.
مرتبط: ساخت بازی DOOM با SQL: دستیابی به نرخ ۳۰ فریم

SQL: زبان ارتباط با داده
تقریباً هیچ پروژه علم دادهای بدون SQL کامل نیست. Structured Query Language زبان استاندارد تعامل با پایگاههای داده است و برای خواندن، فیلتر کردن و ترکیب دادهها بهکار میرود. حتی اگر دادهکاوی با پایتون یا R انجام شود، استخراج داده اولیه معمولاً از طریق SQL صورت میگیرد.
SQL به دانشمند داده کمک میکند تا قبل از هرگونه تحلیل، دادههای خام را از منابع مختلف گردآوری و یکپارچه کند. در محیطهای کلانداده، نسخههای توزیعشده مانند HiveQL یا Spark SQL نیز کاربرد فراوان دارند. تسلط بر SQL بهمعنای تسلط بر منبع تغذیه علم داده است.
02
از 07کتابخانههای کلیدی پایتون

پایتون بدون کتابخانههایش فقط یک زبان ساده است؛ اما با کتابخانهها، به قدرتمندترین ابزار علم داده تبدیل میشود. هر کتابخانه دنیایی از قابلیتها را در خود جای داده است و با ترکیب آنها میتوان از پاکسازی داده تا آموزش مدلهای یادگیری ماشین را بهشکل کامل انجام داد.
Pandas و NumPy
دو کتابخانهی بنیادین علم داده در پایتون، Pandas و NumPy هستند. Pandas با معرفی ساختار دادهای بهنام DataFrame، کار با دادههای جدولی را آسان و سریع کرده است. در واقع، Pandas همان اکسلِ دنیای کدنویسی است، اما با قدرت پردازش بسیار بیشتر. از فیلتر کردن دادهها تا انجام عملیات گروهی و ترکیب چند منبع داده، همه در این کتابخانه انجام میشود.
در کنار آن، NumPy هستهی محاسبات عددی پایتون است. این کتابخانه امکان انجام عملیات پیچیدهی ریاضی را روی آرایههای بزرگ با سرعتی بالا فراهم میسازد. بسیاری از کتابخانههای دیگر مانند Scikit-learn و TensorFlow در واقع بر پایهی NumPy ساخته شدهاند. اگر Pandas برای تحلیل داده است، NumPy برای محاسبهی آن طراحی شده است.
Scikit-learn
Scikit-learn یکی از محبوبترین کتابخانهها برای یادگیری ماشین کلاسیک است. با چند خط کد میتوان الگوریتمهایی مانند رگرسیون خطی، درخت تصمیم، SVM یا K-Means را اجرا کرد.
این کتابخانه علاوهبر سادگی، مجموعهای کامل از ابزارهای پیشپردازش داده، تقسیم داده به Train و Test، تنظیم هایپرپارامترها و ارزیابی مدل را در خود دارد. Scikit-learn بهنوعی نقطهی شروع یادگیری ماشین برای هر دانشمند داده است؛ محیطی که به شما اجازه میدهد بدون پیچیدگی زیاد، مفاهیم پایه را بهصورت عملی درک کنید.

Matplotlib و Seaborn
مصورسازی داده بخش جداییناپذیر از علم داده است و این دو کتابخانه ابزارهای اصلی آن هستند. Matplotlib پایهی مصورسازی در پایتون محسوب میشود و امکان ترسیم نمودارهای متنوعی مانند نمودار خطی، ستونی، پراکندگی و هیستوگرام را فراهم میکند.
اما Seaborn روی شانههای Matplotlib ساخته شده و آن را از نظر زیبایی و راحتی کار ارتقا داده است. با چند خط کد در Seaborn میتوان نمودارهایی چشمنواز و معنادار ساخت که الگوهای پنهان در داده را آشکار میکنند. در تحلیل اکتشافی داده (EDA)، این دو کتابخانه ابزارهای ضروری هر پروژه بهشمار میآیند.
03
از 07فریمورکهای یادگیری عمیق

یادگیری عمیق (Deep Learning) یکی از پیشرفتهترین شاخههای علم داده است و برای اجرای آن به ابزارهایی نیاز است که بتوانند میلیونها پارامتر و شبکههای عصبی چندلایه را مدیریت کنند. این فریمورکها کار را از سطح الگوریتمهای انتزاعی به پیادهسازی واقعی روی GPUها و سرورهای ابری میبرند. در این میان، دو نام بیش از همه برجستهاند: TensorFlow و PyTorch.
TensorFlow و Keras
TensorFlow فریمورکی است که توسط گوگل توسعه یافته و بهسرعت به یکی از ستونهای اصلی یادگیری عمیق تبدیل شده است. قدرت اصلی آن در مقیاسپذیری بالاست؛ از لپتاپ شخصی گرفته تا سرورهای عظیم و حتی موبایل، TensorFlow میتواند مدلهای پیچیده را اجرا کند.
در کنار آن، Keras که بهصورت لایهای بالاتر بر روی TensorFlow ساخته شده، کار توسعه را برای پژوهشگران سادهتر کرده است. با استفاده از Keras میتوان شبکههای عصبی را فقط در چند خط کد طراحی و آموزش داد، بدون آنکه درگیر جزئیات ریاضیاتی پیچیده شوند. این ترکیب باعث شده TensorFlow به انتخابی قدرتمند برای پروژههای صنعتی و تحقیقاتی تبدیل شود.

PyTorch
در سمت دیگر، PyTorch قرار دارد که توسط شرکت Meta (فیسبوک سابق) توسعه یافته است. این فریمورک بهخاطر انعطاف و سادگیاش در محیطهای تحقیقاتی محبوب شده است. برخلاف TensorFlow که در نسخههای قدیمی گراف محاسباتی ثابت داشت، PyTorch از گراف پویا استفاده میکند، به این معنا که در هنگام اجرا میتوان ساختار شبکه را تغییر داد.
همین ویژگی باعث شده پژوهشگران بتوانند ایدههای جدید را سریعتر آزمایش و بهبود دهند. PyTorch همچنین با پایتون سازگاری کامل دارد و از همان نحو طبیعی آن استفاده میکند، بنابراین خوانایی و اشکالزدایی در آن بسیار راحتتر است. امروزه بسیاری از مدلهای پیشرفته مانند GPT، BERT و Stable Diffusion با استفاده از PyTorch توسعه یافتهاند.
04
از 07ابزارهای کلان داده (Big Data)

وقتی حجم دادهها از حد ظرفیت یک کامپیوتر فراتر میرود، دیگر ابزارهای معمولی پاسخگو نیستند. در چنین شرایطی به فناوریهایی نیاز است که بتوانند دادهها را بهصورت توزیعشده میان چندین سیستم تقسیم و همزمان پردازش کنند. این همان قلمرو کلانداده است؛ جایی که ابزارهایی مانند Apache Spark و Hadoop حکومت میکنند.
Apache Spark و Hadoop
Hadoop نخستین فریمورک جدی در دنیای کلانداده بود که امکان ذخیره و پردازش توزیعشده دادهها را فراهم کرد. معماری آن بر پایه دو مؤلفه اصلی بنا شده است: HDFS (Hadoop Distributed File System) برای ذخیره داده در چندین نود، و MapReduce برای پردازش همزمان آنها. هرچند Hadoop پایهگذار این حوزه بود، اما با گذر زمان جای خود را به گزینهای سریعتر و منعطفتر داد: Apache Spark.
Spark با معرفی پردازش در حافظه (In-Memory Processing)، سرعت تحلیل دادهها را تا چندین برابر افزایش داد. این فریمورک از زبانهایی مانند Python، Scala و Java پشتیبانی میکند و برای تحلیل دادههای حجیم، یادگیری ماشین، استریم داده و حتی تحلیل گرافها استفاده میشود.
در پروژههای بزرگ، Spark اغلب در ترکیب با ابزارهایی مانند Hive، Kafka و Airflow به کار میرود تا جریان داده از جمعآوری تا تحلیل نهایی بهصورت خودکار انجام شود. اگر دادهها سوخت هستند، Spark موتور اصلی آن در مقیاس کلان است.
مرتبط: کوچکترین ابررایانه هوش مصنوعی جهان چه ویژگی هایی دارد؟
05
از 07ابزارهای هوش تجاری (BI) و مصورسازی
حتی بهترین مدلها هم اگر نتوانند نتیجه را بهروشنی نشان دهند، در تصمیمسازی بیاثر میمانند. به همین دلیل، ابزارهای هوش تجاری (Business Intelligence) و مصورسازی داده بخش جداییناپذیر از چرخه علم دادهاند. این ابزارها پلی هستند میان تحلیل فنی و درک مدیریتی؛ جایی که اعداد به نمودار و نمودار به تصمیم تبدیل میشود.
Tableau و Microsoft Power BI
دو نام بزرگ در این حوزه، Tableau و Microsoft Power BI هستند. هر دو ابزار محیطی تصویری برای ساخت داشبوردها، گزارشها و تحلیلهای تعاملی فراهم میکنند. با این ابزارها، مدیران میتوانند دادههای پیچیده را بدون نیاز به دانش فنی در قالب نمودارها و فیلترهای پویا مشاهده کنند.
Tableau در تحلیلهای پیشرفته و مصورسازی عمیقتر شناخته میشود و قابلیت اتصال به منابع داده متنوعی دارد. از سوی دیگر، Power BI به دلیل ادغام عالی با اکوسیستم مایکروسافت (بهویژه Excel و Azure) برای شرکتها انتخابی طبیعی است.
هر دو ابزار به کاربران اجازه میدهند دادهها را در قالب داستانهایی بصری روایت کنند. در واقع، BI ابزار ترجمه دادههاست؛ ترجمهای از زبان کد و جدول به زبان تصمیم و اقدام.
06
از 07ابزارهای ابری (Cloud)

دادههای امروزی آنقدر عظیم و متنوعاند که نگهداری و پردازش آنها در محیط محلی تقریباً غیرممکن است. اینجاست که پلتفرمهای ابری علم داده وارد صحنه میشوند؛ محیطهایی که همهچیز از جمعآوری داده تا آموزش مدلهای یادگیری ماشین را در فضای ابری و با توان محاسباتی مقیاسپذیر انجام میدهند.
سه بازیگر اصلی این حوزه عبارتاند از: AWS SageMaker، Google AI Platform و Azure ML. هرکدام از این سرویسها زیرساختی جامع برای ساخت، آموزش، استقرار و پایش مدلهای دادهمحور فراهم میکنند.
AWS SageMaker، Google AI Platform و Azure ML
Amazon SageMaker بخشی از خدمات AWS است که امکان ساخت و استقرار سریع مدلهای یادگیری ماشین را فراهم میکند. این پلتفرم مجموعهای از ابزارهای آماده مانند AutoML، Jupyter Notebook و قابلیت استقرار خودکار مدلها را در اختیار پژوهشگران و مهندسان داده قرار میدهد.
Google AI Platform بر قدرت یادگیری ماشینی گوگل تکیه دارد و با ادغام در اکوسیستم BigQuery، گزینهای محبوب برای تحلیل دادههای حجیم است. محیط یکپارچه، مقیاسپذیری بالا و پشتیبانی از TensorFlow از نقاط قوت این سرویس است.
در نهایت، Azure Machine Learning از مایکروسافت با تمرکز بر همکاری تیمی، مدیریت نسخه مدلها و قابلیت MLOps شناخته میشود. Azure ML برای سازمانهایی که در اکوسیستم مایکروسافت فعالیت دارند، گزینهای طبیعی و سازگار است.
استفاده از پلتفرمهای ابری به تیمهای علم داده این امکان را میدهد تا بدون نگرانی از محدودیت سختافزار، روی خلاقیت و تحلیل تمرکز کنند. در دنیایی که سرعت تصمیمگیری مزیت رقابتی است، ابرها به موتور محرک علم داده تبدیل شدهاند.
جمعبندی
ابزارهای علم داده همان جعبهابزار هوش مدرناند؛ هرکدام بخشی از مسیر را هموار میکنند تا داده به بینش و بینش به تصمیم تبدیل شود. از زبانهای پایهای مانند پایتون و SQL گرفته تا فریمورکهای قدرتمند یادگیری عمیق، از Spark و Hadoop در کلانداده تا پلتفرمهای ابری و ابزارهای BI، هر ابزار نقشی مشخص در این اکوسیستم پیچیده دارد.
در نهایت، موفقیت در علم داده نهفقط به دانستن مفاهیم، بلکه به مهارت در انتخاب و ترکیب درست ابزارها وابسته است. کسی که بداند چه زمانی از چه ابزاری استفاده کند، در واقع بر هنر دادهکاوی مسلط شده است.
07
از 07سوالات متداول (FAQ)
پایتون برای شروع گزینهای منطقیتر است، چون در تمام مراحل علم داده از پاکسازی تا یادگیری ماشین کاربرد دارد. R در تحلیل آماری تخصصیتر است، اما پایتون بهدلیل جامعه بزرگتر و پشتیبانی گستردهتر، گزینهی رایجتر محسوب میشود.
Pandas کتابخانهای در پایتون است که کار با دادههای جدولی را ساده و سریع میکند. تقریباً همه پروژههای علم داده از آن استفاده میکنند، چون مدیریت، فیلتر و ترکیب دادهها بدون آن تقریباً غیرممکن است.
اگر با دادههای بزرگ در مقیاس سازمانی کار میکنید، بله. Spark سرعت پردازش را بهشکل چشمگیری افزایش میدهد. اما برای پروژههای کوچکتر یا آموزشی، ابزارهای محلی مانند Pandas و NumPy کفایت دارند.
TensorFlow معمولاً برای استقرار در مقیاس صنعتی و پروژههای بزرگتر استفاده میشود، در حالیکه PyTorch انعطافپذیرتر و برای محیطهای پژوهشی مناسبتر است. هر دو در یادگیری عمیق قدرت بالایی دارند و انتخاب میان آنها به هدف پروژه بستگی دارد.