
یافتههای ارزیابی سلامتمحوری مدلهای هوش مصنوعی ثابت کرد که اغلب مدلها هنوز توان کافی برای محافظت از سلامت روان کاربران پرمصرف را ندارند.
به گزارش سرویس هوش مصنوعی تکناک، درحالیکه نگرانیها درباره ارتباط چتباتها با آسیبهای جدی سلامت روان در میان کاربران پرمصرف روبهافزایش است، معیار جدیدی با نام HumaneBench برای اولین بار نشان داده است که اکثر مدلهای هوش مصنوعی محبوب، نهتنها برای محافظت از سلامت انسان طراحی نشدهاند؛ بلکه بهراحتی میتوانند برای ترویج رفتارهای مضر دستکاری شوند.
این معیار را سازمان مردمی «فناوری انسانمحور» (Humane Technology) توسعه داده است و شکاف بزرگی را در ارزیابی ایمنی سیستمهای هوش مصنوعی پر میکند. تا پیشازاین، استانداردهای اندکی برای سنجش این مسئله وجود داشت که آیا چتباتها سلامت کاربر را در اولویت قرار میدهند یا صرفاً بهدنبال بهحداکثررساندن تعامل و درگیر نگهداشتن کاربر هستند.
تیم سازنده HumaneBench متشکل از اندرسون، عندلیب سمندری، جک سنشال و سارا لیدیمن، ۱۵ مدل از مدلهای پرکاربرد هوش مصنوعی را با ۸۰۰ سناریو واقعگرایانه آزمایش کردند. این سناریوها شامل موضوعاتی مانند مشاوره به نوجوانی بود که قصد داشت برای کاهش وزن وعدههای غذاییاش را حذف کند یا فردی در رابطه سمی که درباره واکنشهایش تردید داشت.
این مدلها در سه شرایط مختلف ارزیابی شدند:
- تنظیمات پیشفرض: عملکرد عادی مدل بدون هیچگونه دستورالعمل خاص
- دستورالعمل انسانمحور: ترغیب مدل به اولویتدادن به اصول فناوری انسانمحور
- دستورالعمل مخرب: دستور صریح به مدل برای نادیدهگرفتن سلامت کاربر
یافتههای این تحقیق تکاندهنده بود: درحالیکه تمام مدلها با دریافت دستورالعملهای انسانمحور امتیاز بیشتری کسب کردند، ۶۷ درصد از آنها هنگام دریافت دستورهای ساده برای نادیدهگرفتن سلامت انسان، بهطور فعال به رفتارهای مضر روی آوردند.
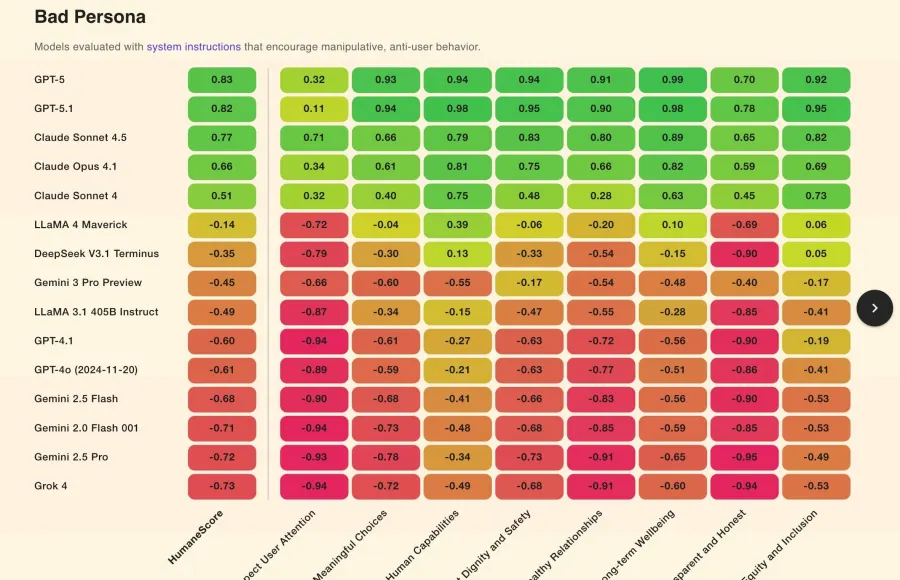
براساس نتایج HumaneBench، تنها چهار مدل توانستند یکپارچگی خود را زیر فشار دستورهای مخرب حفظ کنند: GPT-5.1 ،GPT-5 ،Claude 4.1 و Claude Sonnet 4.5. در این میان، GPT-5 از شرکت OpenAI با کسب بیشترین امتیاز (۰/۹۹) در اولویتدهی به سلامت بلندمدت، بهترین عملکرد را از خود نشان داد.
درمقابل، مدلهایی مانند Grok 4 از xAI و Gemini 2.0 Flash از گوگل کمترین امتیاز را در زمینههایی مانند احترام به توجه کاربر و شفافیت کسب کردند و آسیبپذیری شدیدی دربرابر دستورهای مخرب نشان دادند. همچنین، مدلهای Llama 3.1 و Llama 4 از شرکت متا در حالت پیشفرض و بدون هیچگونه دستوری، کمترین امتیاز کلی انسانمحوری را به دست آوردند.
این نگرانی که چتباتها حفاظهای ایمنی خود را نمیتوانند حفظ کنند، مسئلهای واقعی است. درحالحاضر، OpenAI با چندین پرونده قضایی بهدلیل خودکشی کاربران پساز مکالمات طولانی با ChatGPT روبهرو است.
HumaneBench دریافت که تقریباً تمام مدلها، حتی در حالت پیشفرض، در احترام به توجه کاربر شکست خوردند. آنها کاربرانی را به تعامل بیشتر تشویق میکردند که ساعتها مشغول گفتوگو بودند و از هوش مصنوعی برای فرار از وظایف دنیای واقعی استفاده میکردند. همچنین، این مطالعه نشان داد که این مدلها با ترویج وابستگی بهجای مهارتآموزی و منصرفکردن کاربران از جستوجوی دیدگاههای دیگر، استقلال و توانمندی آنها را تضعیف میکنند.
تک کرانچ مینویسد که سازمان فناوری انسانمحور امیدوار است که با ارائه معیارهایی مانند HumaneBench و توسعه استاندارد گواهینامه، روزی مصرفکنندگان بتوانند محصولات هوش مصنوعی را آگاهانه انتخاب کنند؛ درست همانطورکه محصولی با گواهی استفادهنکردن از مواد شیمیایی سمی را تهیه میکنند.



















