محققان اپل با معرفی مدل هوش مصنوعی VSSFlow، مرزهای تولید محتوا را جابهجا کردند؛ سیستمی که برخلاف مدلهای قبلی، همزمان جلوههای صوتی و دیالوگ میسازد.
به گزارش سرویس هوش مصنوعی تکناک، تیمی متشکل از محققان اپل و دانشگاه رنمین چین، از مدل هوش مصنوعی نوینی با نام VSSFlow پردهبرداری کردهاند که قابلیت چشمگیری در تولید همزمان جلوههای صوتی و گفتار از ویدئوهای صامت دارد. این سیستم یکپارچه و واحد با نتایجی پیشرفته، مشکلات دیرینه در حوزه تولید محتوای صوتی از ویدئو را حل میکند و پارادایم جدیدی را در هوش مصنوعی مولد بنیان مینهد.
درحالحاضر، مدلهای هوش مصنوعی فعال در این زمینه معمولاً با محدودیتهای تخصصی روبهرو هستند. اکثر مدلهای تبدیل ویدئو به صدا (Video-to-Sound یا V2S) که برای تولید صدا از ویدئوهای صامت آموزش دیدهاند، در تولید گفتار عملکرد ضعیفی از خود نشان میدهند. به همین ترتیب، مدلهای تبدیل متن به گفتار (Text-to-Speech یا TTS) که هدف متفاوتی دارند، در تولید صداهای غیرگفتاری ناتوان هستند.
تلاشهای پیشین برای یکپارچهسازی این دو وظیفه، اغلب بر این فرض استوار بود که آموزش مشترک میتواند به کاهش عملکرد منجر شود. این تصور غلط طراحی سیستمهایی را بهدنبال داشت که آموزش گفتار و صدا را در مراحل جداگانه انجام میدادند و بدینترتیب، پیچیدگی فرایند را بهشدت افزایش میدادند.
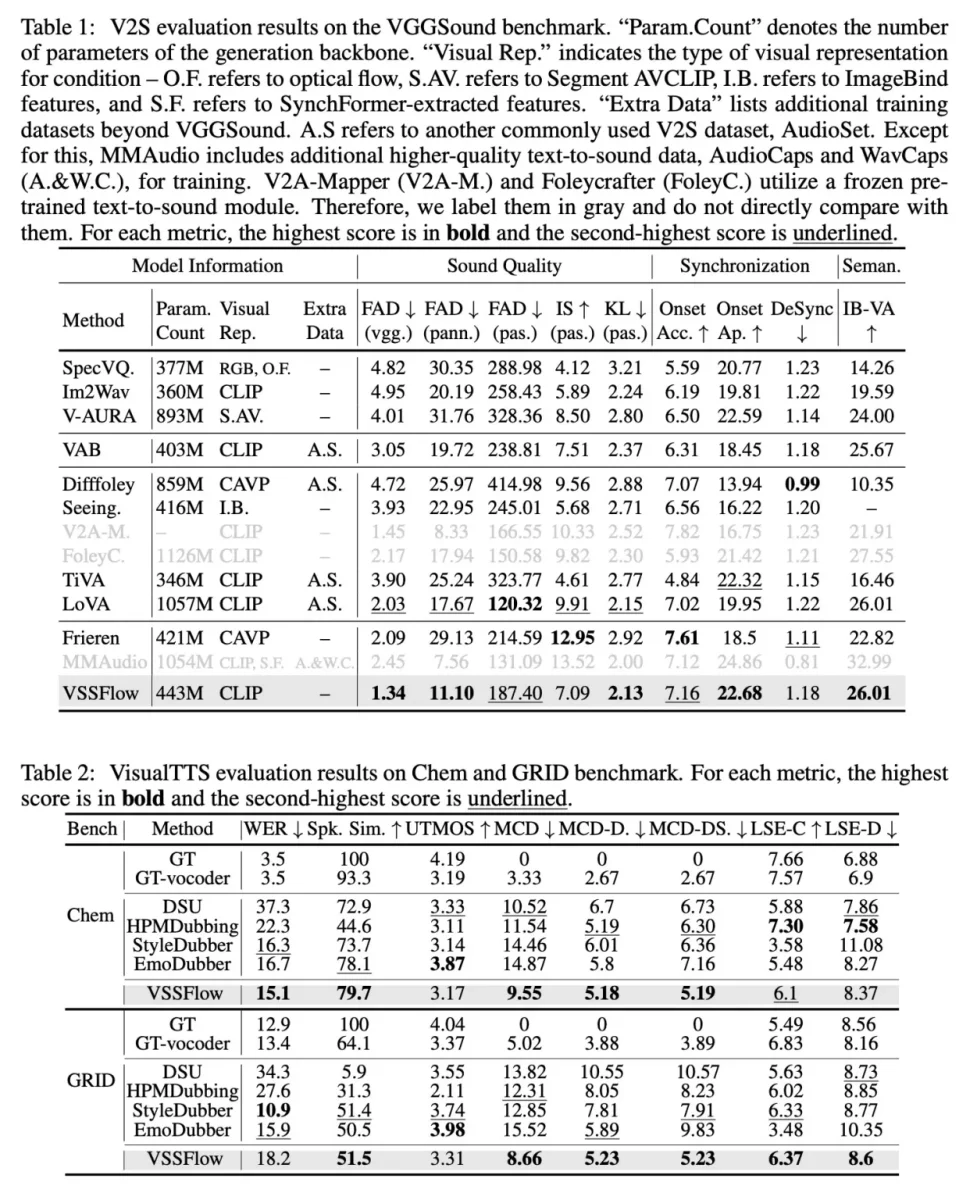
بهطور خلاصه، VSSFlow از چندین مفهوم پیشرفته در هوش مصنوعی مولد بهره میبرد:
- تبدیل رونویسیها به توالیهای آوایی (فونم) از توکنها: این امر به مدل اجازه میدهد تا گفتار را با دقت فراوانی تولید کند.
- یادگیری بازسازی صدا از نویز با استفاده از تطبیق جریان (Flow-Matching): درباره این شیوه پیشتر نیز در حوزه هوش مصنوعی بحث شده است و به مدل آموزش میدهد که بهطور مؤثری از نویز تصادفی شروع کند و به سیگنال صوتی مدنظر دست یابد.
تمام این مفاهیم در معماری ۱۰ لایهای گنجانده شدهاند که سیگنالهای ویدئویی و رونویسی متنی را بهطور مستقیم در فرایند تولید صدا ادغام میکند. این ادغام امکان مدیریت همزمان جلوههای صوتی و گفتار را در سیستمی واحد فراهم میآورد. جالبتر اینکه محققان خاطرنشان کردهاند که آموزش مشترک روی گفتار و صدا، درواقع عملکرد را در هر دو وظیفه بهبود بخشیده است و نهتنها باعث رقابت بین این دو یا کاهش عملکرد کلی هر یک از وظایف نمیشود.
برای آموزش مدل هوش مصنوعی VSSFlow، محققان از ترکیبی از دادهها شامل ویدئوهای صامت با صداهای محیطی (V2S) و ویدئوهای گفتاری صامت همراه با رونویسی (VisualTTS) و دادههای تبدیل متن به گفتار (TTS) استفاده کردند. این رویکرد به مدل اجازه داد تا هم جلوههای صوتی و هم گفتوگوی گفتاری را همزمان در فرایند آموزش سرتاسری (End-to-End) یاد بگیرد.
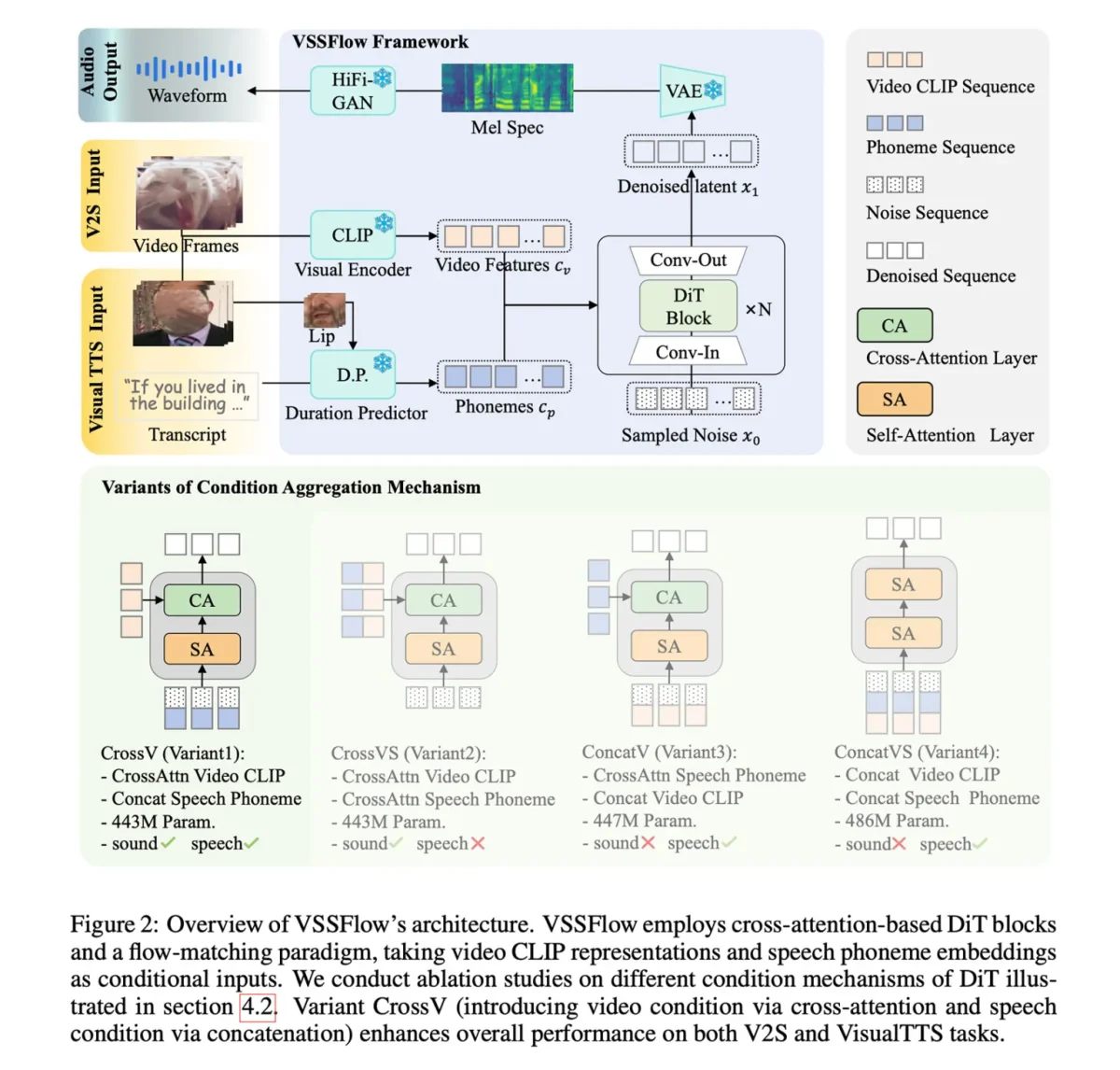
در ابتدا، VSSFlow بهتنهایی نمیتوانست بهطور خودکار صدای پسزمینه و گفتوگوی گفتاری را همزمان در خروجی واحد تولید کند. برای غلبه بر این محدودیت، محققان مدل ازپیشآموزشدیده خود را روی مجموعهای بزرگ از نمونههای مصنوعی که در آنها گفتار و صداهای محیطی باهم ترکیب شده بودند، بهینهسازی (fine-tuned) کردند تا مدل چگونگی همزمانی این دو را بیاموزد.
به نقل از 9to5mac، برای به کارگیری VSSFlow، مدل از نویز تصادفی آغاز میکند و از نشانههای بصری نمونهبرداریشده از ویدئو با نرخ ۱۰ فریمبرثانیه برای شکلدهی به صداهای محیطی بهره میبرد. همزمان رونویسی آنچه گفته میشود، راهنمایی دقیقی برای تولید گفتار فراهم میآورد.
در آزمایشهای مقایسهای با مدلهای خاص منظوره که فقط برای جلوههای صوتی یا فقط برای گفتار طراحی شده بودند، مدل هوش مصنوعی VSSFlow در هر دو وظیفه نتایج کاملاً رقابتی ارائه داد و با وجود استفاده از سیستم واحد و یکپارچه، در چندین معیار مهم پیشتاز بود. محققان دموهای متعددی از نتایج تولید صدا و گفتار و تولید مشترک از ویدئوهای Veo3 و مقایسههایی بین VSSFlow و چندین مدل جایگزین را منتشر کردهاند.
در اقدامی مهم برای جامعه هوش مصنوعی، محققان کد VSSFlow را در گیتهاب متنباز (open-source) کردهاند و درحال کار روی متنبازکردن وزنهای مدل و ارائه دمو استنتاج (Inference) برای کاربران هستند.