بر اساس پست وبلاگی که شرکت متا منتشر کرد، هوش مصنوعی این شرکت برای اولین بار در جهان، ساختارهای دنیای متاژنومیک را در مقیاس صدها میلیون پروتئین تولید کرده است.
به گزارش تکناک، تیم تحقیقاتی متا همچنین در مقاله ای که پایگاه داده bioRxiv منتشر کرد در این مورد نوشت.
پروتئینها مولکولهای پیچیده و پویا هستند که توسط ژنهای ما کدگذاری شدهاند و مسئول بسیاری از فرآیندهای متنوع و اساسی زندگی هستند. آنها نقش های شگفت انگیزی در زیست شناسی دارند.
میلهها و مخروط های که در چشم ما که نور را حس میکنند و دیدن را برای ما ممکن میسازند، حسگرهای مولکولی که زیربنای شنوایی و حس لامسه ما هستند، ماشینهای مولکولی پیچیده که نور خورشید را به انرژی شیمیایی در گیاهان تبدیل میکنند، موتورهایی که حرکت را در میکروبها هدایت میکنند و ماهیچههای ما، آنزیمهایی که پلاستیک را تجزیه میکنند، آنتیبادیهایی که از ما در برابر بیماری محافظت میکنند، و مدارهای مولکولی که در صورت از کار افتادن باعث بیماری میشوند، همه پروتئین هستند.
پروتئین ها در سراسر سیاره و در بدن انسان ها حضور دارند
متاژنومیکس از توالی یابی ژن برای کشف پروتئین ها در نمونه هایی از محیط های سراسر سیاره و حتی بدن انسان استفاده می کند.
این دانش عمومی است که تعداد زیادی پروتئین فراتر از آنهایی که در ارگانیسمهای به خوبی مطالعه شده فهرستبندی و حاشیهنویسی شدهاند وجود دارند و اکنون این پروتئینها به سطح میآیند.
متاژنومیکس در حال آشکار کردن وسعت و تنوع باورنکردنی این پروتئینها است ومیلیاردها توالی پروتئین را کشف میکند که برای علم جدید هستند و برای اولین بار در پایگاههای داده گردآوری می شوند.
این مهم توسط سازمان های عمومی مانند NCBI، موسسه بیوانفورماتیک اروپایی و موسسه ژنوم مشترک فهرستبندی شدهاند که شامل نتایج مطالعات جامعه جهانی از محققان است که توسط تیم تحقیقاتی متا ادامه می یابد.
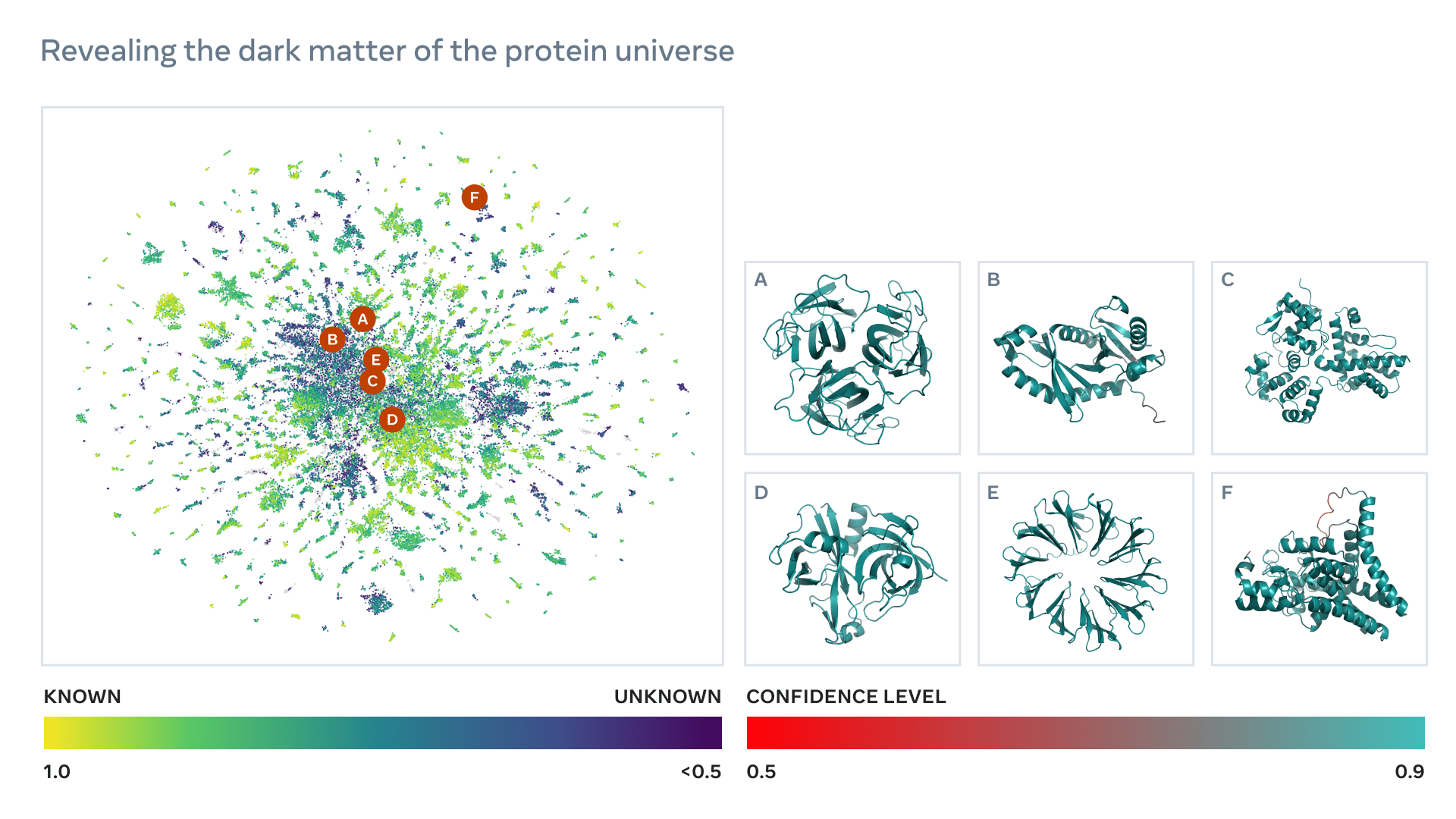
این کشف با استفاده از برنامه ای به نام ESMFold با مدلی که در ابتدا برای رمزگشایی زبان های انسانی طراحی شده بود، انجام شد. این یافتهها در اطلس متاژنومیک ESM که برای استفاده عموم آزاد است جمعآوری شده و میتوانند روزی در تولید داروهای جدید، توصیف عملکردهای میکروبی ناشناخته و کشف ارتباط های تکاملی بین گونههای که نسبت دور با یکدیگر دارند مورد استفاده قرار گیرند.
متا پایگاه داده ای از بیش از 600 میلیون ساختار متاژنومیک وهمچنین یک API را که به دانشمندان اجازه می دهد به راحتی ساختارهای پروتئینی خاص مرتبط با کار خود را بازیابی کنند به اشتراک گذاشت.
پیش بینی پروتئین
ESMFold اولین برنامه ای نیست که پروتئین را پیش بینی می کند. شرکت متعلق به گوگل به نام DeepMind همچنین یک برنامه پیش بینی پروتئین به نام AlphaFold که امسال نیز به دنبال شناسایی پروتئین ها بود در این حوزه فعالیت دارند. با این حال، محققان متا ادعا میکنند که ESMFold 60 برابر سریعتر از AlphaFlod است، اگرچه نتایج آن هنوز به دقت بازنگری نشده است.
دانشمندان همچنین اظهار داشتند که اطلس جدید آنها بزرگترین پایگاه داده ساختارهای پیش بینی شده با وضوح بالا است، که 3 برابر بزرگتر از هر پایگاه داده ساختار پروتئین موجود، و اولین پایگاهی است که پروتئین های متاژنومی را به طور جامع و در مقیاس وسیع پوشش می دهد.
تیم تحقیقاتی متا پیش بینی کرد این ساختارها دید بیسابقهای به وسعت و تنوع طبیعت ارائه میکنند و پتانسیل زیادی را برای فهم پدیده های علمی جدید و تسریع در کشف پروتئینها برای کاربردهای خاص مانند زمینههایی مانند پزشکی، شیمی سبز، کاربردهای زیستمحیطی و انرژیهای تجدیدپذیر ایجاد می کند.