
استفاده فزاینده از تکنیک Distillation در مدلهای هوش مصنوعی، زنگ خطر جدیدی را برای امنیت دادهها و حقوق مالکیت فکری در صنعت AI به صدا درآورده است.
به گزارش تکناک، در هفته گذشته، شرکت چینی دیپسیک نسخه جدیدی از مدل هوش مصنوعی استدلالی خود با نام R1 را منتشر کرد که عملکرد قدرتمندی در آزمونهای مرتبط با ریاضیات و برنامهنویسی از خود نشان داده است. بااینحال، این شرکت منبع دادههایی که برای آموزش این مدل به کار برده، فاش نکرده و همین موضوع گمانهزنیهایی در میان پژوهشگران حوزه هوش مصنوعی ایجاد کرده است. برخی از آنان احتمال میدهند که بخشی از دادههای آموزشی مدل جدید دیپسیک از خانواده مدلهای هوش مصنوعی جمنای شرکت گوگل استخراج شده باشد.
سام پیچ، توسعهدهندهای مستقر در ملبورن که ارزیابیهایی برای سنجش «هوش هیجانی» در مدلهای هوش مصنوعی طراحی میکند، با انتشار پستی در شبکه اجتماعی X مدعی شد که مدل R1-0528 دیپسیک از واژگان و الگوهای زبانی مشابه با Gemini 2.5 Pro استفاده میکند. او شواهدی منتشر کرد که به گفته خودش نشان میدهد مدل دیپسیک با خروجیهای جمنای آموزش دیده است.
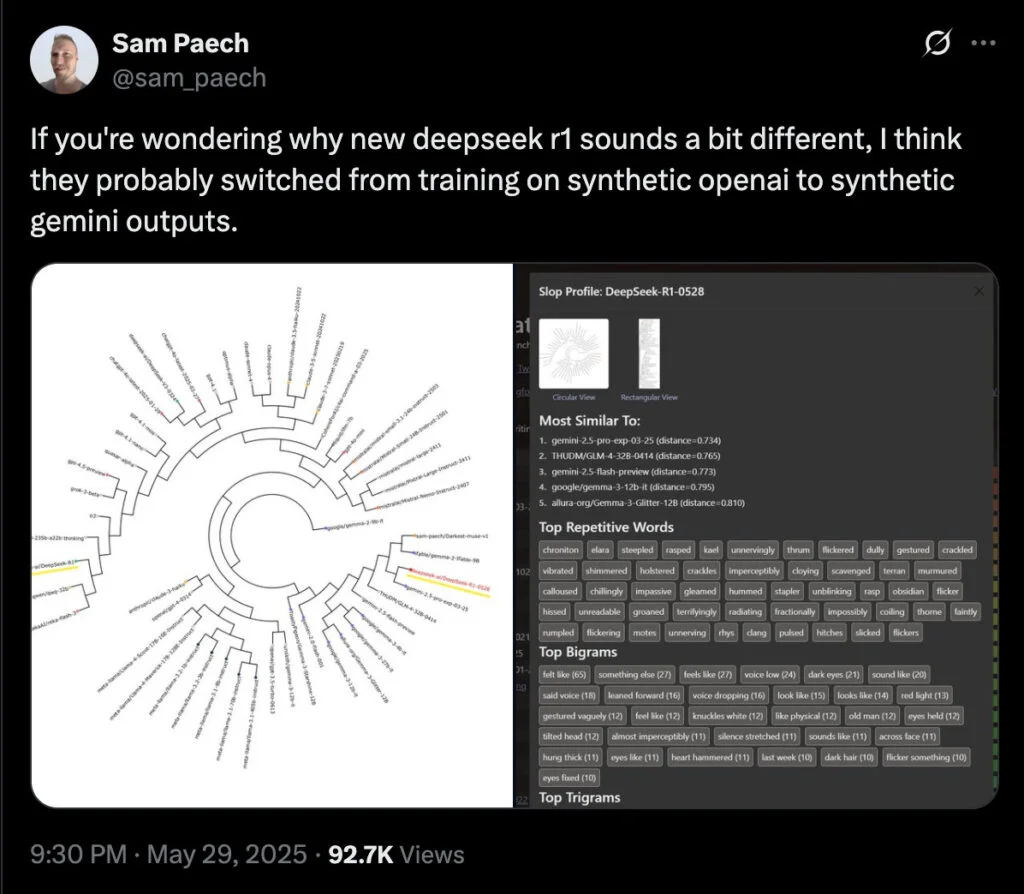
به نقل از تککرانچ، اگرچه این شباهتها بهتنهایی نمیتوانند بهعنوان مدرکی قطعی در نظر گرفته شوند، توسعهدهندهای دیگر که با نام مستعار فعالیت میکند و ابزار ارزیابی «آزادی بیان» با نام SpeechMap را برای مدلهای هوش مصنوعی توسعه داده، اشاره کرده است که ردپاهای تولیدشده با مدل دیپسیک شباهت زیادی به ردپاهای مدل Gemini دارند. این ردپاها بهعنوان «افکار میانی» مدل در مسیر رسیدن به پاسخ شناخته میشوند.
این نخستین بار نیست که دیپسیک به استفاده از دادههای مدلهای رقیب متهم میشود. در دسامبر سال گذشته، برخی توسعهدهندگان گزارش دادند که مدل V3 دیپسیک در برخی مواقع خود را بهعنوان ChatGPT معرفی میکرد که نشان میدهد این مدل ممکن است با گفتوگوهای واقعی کاربران با ChatGPT آموزش دیده باشد.
در ابتدای سال جاری، شرکت OpenAI در گفتوگویی با فایننشال تایمز اعلام کرد که شواهدی دال بر استفاده دیپسیک از روش Distillation (استخراج داده از مدلهای بزرگتر و آموزش مدل جدید براساس آن) پیدا کرده است. براساس گزارش بلومبرگ، مایکروسافت، از شرکای اصلی و سرمایهگذاران OpenAI، متوجه شد که در اواخر سال ۲۰۲۴ حجم زیادی ازدادهها ازطریق حسابهای توسعهدهنده OpenAI به بیرون منتقل شده است؛ حسابهایی که OpenAI آنها را به دیپسیک مرتبط میداند.
هرچند استفاده از روش Distillation در صنعت هوش مصنوعی رایج است، قوانین OpenAI استفاده از خروجیهای مدلهای خود برای توسعه مدلهای رقیب را صراحتاً ممنوع کرده است. در این بین، برخی تحلیلگران معتقدند که مشابهت میان مدلهای مختلف ممکن است ناشی از آلودگی روزافزون دادهها در اینترنت باشد. بسیاری از محتواهای آنلاین اکنون با مدلهای هوش مصنوعی تولید میشوند و باتها نیز در پلتفرمهایی مانند ردیت و شبکه اجتماعی ایکس فعالیت میکنند. این وضعیت باعث شده است تا شناسایی و پالایش دقیق دادههای تولیدشده با هوش مصنوعی در مجموعه دادههای آموزشی بسیار دشوار شود.
بااینحال، ناتان لمبرت، پژوهشگر مؤسسه غیردولتی AI2، میگوید که بعید نیست دیپسیک برای جبران کمبود منابع پردازشی خود، از خروجیهای باکیفیت مدلهایی مانند جمنای استفاده کرده باشد. او با انتشار پستی در شبکه اجتماعی X نوشت:
اگر جای دیپسیک بودم، قطعاً حجم زیادی داده مصنوعی از بهترین مدلهای موجود تولید میکردم. آنها منابع مالی دارند؛ اما با کمبود GPU مواجهاند. این روش عملاً قدرت محاسباتی بیشتری برایشان به ارمغان میآورد.
در همین زمینه و با هدف مقابله با پدیده Distillation، شرکتهای بزرگ فعال در حوزه هوش مصنوعی اقدامات امنیتی جدیدی اتخاذ کردهاند. OpenAI در آوریل ۲۰۲۵ اعلام کرد که برای دسترسی به برخی مدلهای پیشرفته، سازمانها باید فرایند احراز هویت را با استفاده از کارت شناسایی دولتی طی کنند. در این میان، کشور چین جزو فهرست کشورهای پشتیبانیشده نیست.
همزمان، گوگل نیز خلاصهسازی خودکار ردپای مدلهای موجود در پلتفرم AI Studio را آغاز کرده است تا استفاده از این ردپاها برای آموزش مدلهای رقیب دشوارتر شود. شرکت آنتروپیک نیز در ماه می اعلام کرد با هدف حفظ مزیت رقابتی خود، خلاصهسازی ردپاهای مدلهایش را آغاز خواهد کرد. تا زمان انتشار این گزارش، شرکت گوگل به درخواست رسانهها برای اظهارنظر دراینباره پاسخی نداده است.




















