
پژوهشگران شرکت DeepSeek روز دوشنبه از یک مدل آزمایشی جدید با نام V3.2-exp رونمایی کردند که هدف اصلی آن کاهش چشمگیر هزینه استنتاج در عملیاتهای متنی طولانی است.
به گزارش تکناک، این مدل از طریق پلتفرم Hugging Face معرفی شد و مقاله علمی مرتبط با آن نیز در GitHub منتشر شده است.
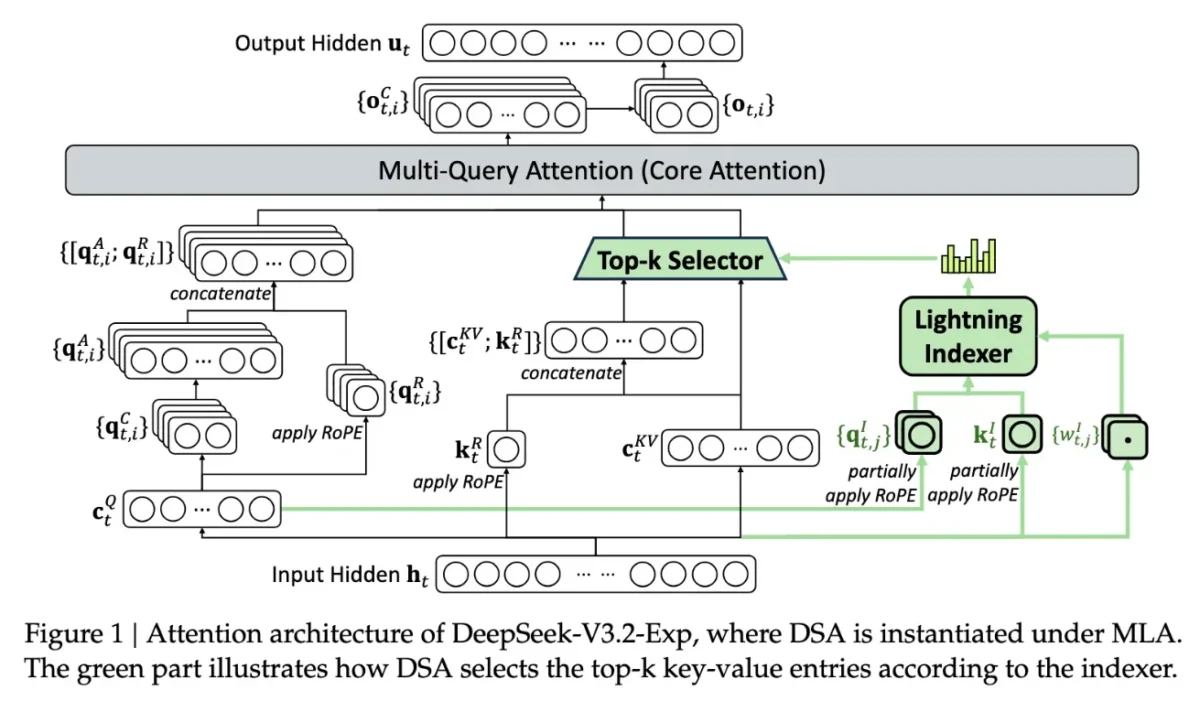
مهمترین ویژگی این مدل، فناوری جدیدی به نام DeepSeek Sparse Attention است. در این سیستم، یک ماژول موسوم به lightning indexer بخشهای کلیدی از پنجره متنی را اولویتبندی میکند. سپس سامانه دیگری با عنوان fine-grained token selection system توکنهای دقیقتری را از میان آن بخشها انتخاب و وارد پنجره توجه محدود مدل میکند. ترکیب این دو فرایند باعث میشود که مدل بتواند بخشهای وسیعی از متن را با بار محاسباتی و هزینه سرور بسیار کمتر پردازش کند.
طبق آزمایشهای اولیه DeepSeek، استفاده از این روش میتواند هزینه یک فراخوانی ساده API را در سناریوهای متنی طولانی تا نصف کاهش دهد. البته این نتایج هنوز نیازمند بررسیهای مستقل و دقیقتر هستند، اما به دلیل انتشار آزاد و در دسترس بودن وزنهای مدل در Hugging Face، انتظار میرود که بهزودی آزمایشهای شخص ثالث، صحت این ادعاها را بررسی کنند.
مدل جدید DeepSeek بخشی از روند کلی تلاشهای اخیر برای کاهش هزینههای استنتاج است؛ هزینههایی که مربوط به اجرای مدلهای از پیش آموزشدیده روی سرورها است و با هزینههای آموزش اولیه تفاوت دارد. پژوهشگران DeepSeek با تمرکز بر بهینهسازی معماری ترانسفورمر نشان دادهاند که همچنان ظرفیتهای زیادی برای بهبود عملکرد و کاهش هزینه وجود دارد.
شرکت DeepSeek که مقر آن در چین است، در سالهای اخیر حضوری متفاوت در رقابت جهانی هوش مصنوعی داشته است. این شرکت در ابتدای سال با مدل R1 خبرساز شد؛ مدلی که با استفاده گسترده از یادگیری تقویتی و با هزینهای بسیار کمتر از رقبای آمریکایی آموزش داده شد. با وجود این، برخلاف پیشبینیها، R1 باعث انقلابی گسترده در روند آموزش مدلها نشد و نام این شرکت مدتی در حاشیه قرار گرفت.
اکنون فناوری “Sparse Attention” به احتمال زیاد هیاهوی مدل R1 را تکرار نخواهد کرد، اما میتواند برای ارائهدهندگان آمریکایی الگویی کاربردی باشد تا هزینههای بالای استنتاج را کاهش دهند و راهکارهای جدیدی برای کارایی بیشتر در اختیار صنعت قرار دهد.




















