اخیرا دانشمندان یک سری ربات اسلایمی بدون شکل ساختهاند که برای انجام کارهای پیچیده تغییر شکل میدهند. اما محققان MIT یک تکنیک یادگیری ماشینی را توسعه دادهاند که این رباتهای نرم تغییر شکلداده را یک قدم به واقعیت نزدیکتر میکند.
به گزارش تکناک، جهان در سال 1991 با ربات T-1000 که در فیلم ترمیناتور 2 بود، با مفهوم رباتهای تغییر شکل دهنده آشنا شد. از آن زمان بسیاری از دانشمندان رویای ایجاد رباتی با توانایی تغییر شکل برای انجام وظایف مختلف را در سر میپرورانند.
میتوان گفت اخیرا به ساخت چنین رباتهایی نزدیک شدهایم، مثلاً تور مغناطیسی از دانشگاه هنگ کنگ، یا مرد لگو فلزی مایع که میتواند ذوب شود و دوباره شکل بگیرد. با این حال، هر دوی اینها به کنترلهای مغناطیسی خارجی نیاز دارند. آنها نمیتوانند مستقل حرکت کنند.
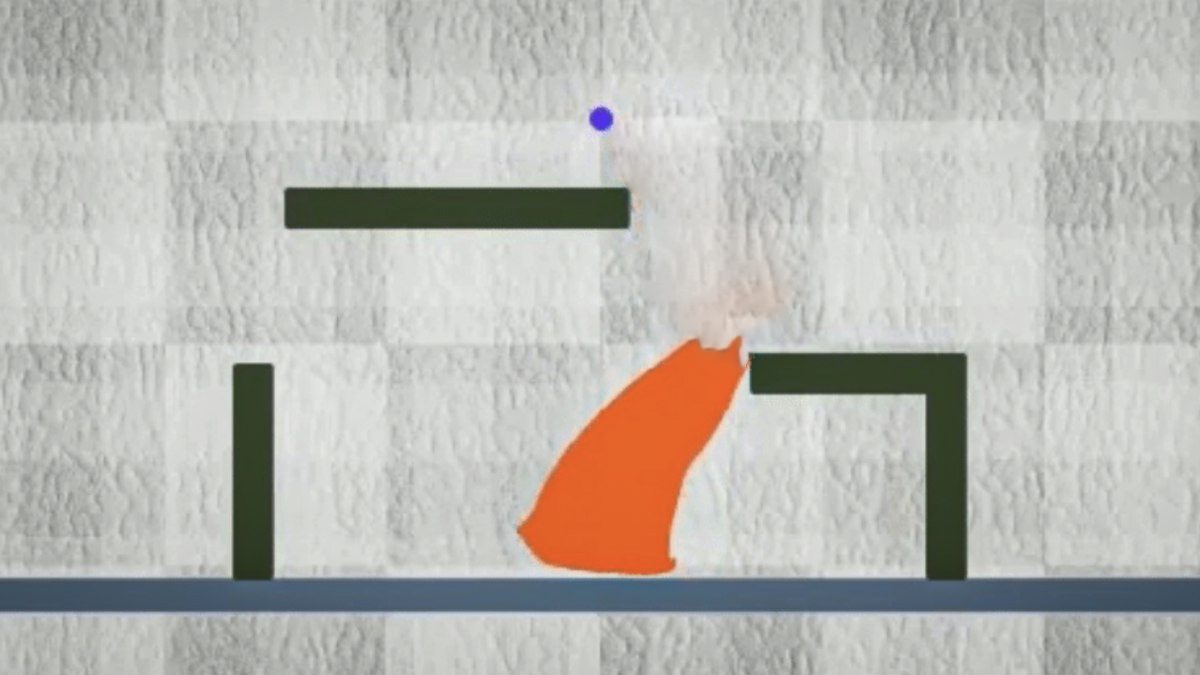
اما بهتازگی یک گروه تحقیقاتی در MIT در حال توسعه مواردی هستند که میتوانند مستقل حرکت کنند. آنها یک تکنیک یادگیری ماشینی را توسعه دادهاند که یک ربات اسلایمی قابل تنظیم مجدد را آموزش میدهد و کنترل میکند که میچرخد، خم و دراز میشود تا با محیط و اشیاء خارجی خود تعامل داشته باشد. نکته جانبی ناامید کننده این است که این ربات از فلز مایع ساخته نشده است.
بویوان چن، از نویسندگان این مطالعه که به تشریح این موضوع میپردازد، میگوید: وقتی مردم به رباتهای نرم فکر میکنند، بیشتر به رباتهایی فکر کنند که انعطافپذیر هستند، اما به شکل اولیه خود باز میگردند. این ربات مانند لجن است و در واقع میتواند مورفولوژی خود را تغییر دهد.
محققان مجبور شدند راهی برای کنترل یک ربات اسلایمی ابداع کنند که دست، پا یا انگشت ندارد یا در واقع هیچ نوع اسکلتی برای فشار دادن و کشیدن ماهیچههایش ندارد و در واقع میتوان گفت هیچ مکان مشخصی برای هیچ یک از عضلاتش ندارد. چگونه قرار است حرکات چنین روباتی را برنامهریزی کنیم؟
واضح است که هر نوع طرح کنترل استاندارد در این حالت بیفایده خواهد بود، بنابراین محققان به هوش مصنوعی روی آوردند و از توانایی عظیم آن برای مقابله با دادههای پیچیده استفاده کردند. آنها یک الگوریتم کنترلی توسعه دادند که یاد میگیرد چگونه ربات اسلایمی را گاهی اوقات چندین بار برای انجام یک کار خاص حرکت، کشش و شکل دهد.

یادگیری تقویت یک تکنیک یادگیری ماشینی است که نرم افزار را برای تصمیمگیری با استفاده از آزمون و خطا آموزش میدهد. برای آموزش رباتهایی با قطعات متحرک کاملاً مشخص مانند گیرهای با انگشتان، میتواند برای اقداماتی که آن را به هدف نزدیکتر میکند، پاداش داده شود مثلاً برداشتن تخم مرغ. اما در مورد یک ربات نرم بدون شکل که توسط میدانهای مغناطیسی کنترل میشود چه میتوان گفت؟
چن گفت: چنین رباتی میتواند هزاران قطعه کوچک عضلانی برای کنترل داشته باشد. بنابراین یادگیری به روش سنتی بسیار سخت است.
یک ربات اسلایمی نیاز به تکههای بزرگی از آن دارد که در یک زمان جابجا شوند تا به یک تغییر شکل عملکردی و موثر دست پیدا کنند. دستکاری ذرات منفرد منجر به تغییر اساسی مورد نیاز نخواهد شد. بنابراین،محققان از یادگیری تقویتی به روشی غیر سنتی استفاده کردند.
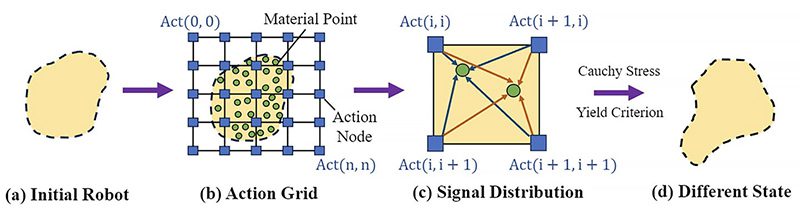
در یادگیری تقویتی، مجموعهای از اقدامات یا انتخابهای معتبر در دسترس یک عامل در اثر تعامل با یک محیط، فضای عمل نامیده میشود. در اینجا، فضای عمل ربات مانند تصویری متشکل از پیکسلها در نظر گرفته میشود. مدل محققان از تصاویر محیط ربات برای ایجاد یک فضای عمل دوبعدی پوشیده شده توسط نقاطی که با یک شبکه پوشانده شده بودند، استفاده کرد.
به همان شکلی که پیکسلهای نزدیک در یک تصویر به هم مرتبط هستند، الگوریتم محققان متوجه شد که نقاط عمل نزدیک، همبستگی قویتری دارند. بنابراین، نقاط عمل در اطراف بازوی ربات با تغییر شکل با هم حرکت میکنند. نقاط عمل روی پا”نیز با هم حرکت میکنند، اما متفاوت از حرکت بازو.
همچنین محققان الگوریتمی با یادگیری خط مشی درشت به ریز توسعه دادند. ابتدا، الگوریتم با استفاده از یک خط مشی درشت با وضوح پایین -یعنی حرکت تکههای بزرگ برای کشف فضای عمل و شناسایی الگوهای عمل معنیدار آموزش داده میشود. سپس، یک خطمشی با وضوح بالاتر، دقیق و عمیقتر برای بهینهسازی اقدامات ربات و بهبود توانایی آن برای انجام وظایف پیچیده، کاوش میکند.
وینسنت سیتزمن، یکی از نویسندگان مطالعه گفت: خط مشی درشت به ریز به این معنی است که وقتی یک اقدام تصادفی انجام میدهید، آن عمل تصادفی احتمالاً تفاوت ایجاد میکند. تغییر در نتیجه به احتمال زیاد بسیار قابل توجه است، زیرا شما چندین ماهیچه را بهطور همزمان کنترل میکنید.
قدم بعدی آزمایش رویکرد آنها بود. آنها یک محیط شبیه سازی به نام DittoGym ایجاد کردند که دارای هشت وظیفه است که توانایی یک ربات قابل تنظیم مجدد را برای تغییر شکل ارزیابی میکند. به عنوان مثال، تطبیق ربات با یک حرف یا نماد و ایجاد رشد، حفاری، لگد زدن، گرفتن و دویدن.
سانینگ هوانگ، یکی از نویسندگان مطالعه گفت: انتخاب کار ما در DittoGym از اصول طراحی معیار یادگیری تقویتی عمومی و نیازهای خاص رباتهای قابل تنظیم مجدد پیروی میکند.
هوانگ افزود: هر کار به گونهای طراحی شده است که ویژگیهای خاصی را نشان دهد که ما مهم می دانیم، مانند قابلیت حرکت در کاوشهای افق طولانی، توانایی تجزیه و تحلیل محیط و تعامل با اشیاء خارجی. کاربران درک جامعی از انعطافپذیری رباتهای قابل تنظیم مجدد و اثربخشی طرح یادگیری تقویتی ما دارند.
محققان به این نتیجه رسیدند که از نظر کارایی، الگوریتم درشت به ریز آنها بهطور مداوم در تمام وظایف از گزینههای جایگزین (به عنوان مثال، سیاستهای فقط درشت یا ریز از ابتدا) بهتر عمل میکند.
مدتی طول میکشد تا رباتهای تغییر شکل دهنده را در خارج از آزمایشگاه ببینیم، اما این کار گامی در مسیر درست است. محققان امیدوارند که این ربات به دیگر دانشمندان الهام بخشد تا ربات نرم قابل تنظیم مجدد خود را توسعه دهند که روزی بتواند بدن انسان را طی کند یا در یک دستگاه پوشیدنی گنجانده شود.
این مطالعه در وب سایت arXiv منتشر شد.