فهرست مطالب
چرخه حیات علم داده مجموعه مراحلی است که یک پروژه دادهمحور از ایده تا اجرای نهایی طی میکند. این چرخه مانند نقشه راهی است که نشان میدهد از کجا باید شروع کرد، چگونه دادهها را آماده کرد و در نهایت چگونه نتیجه را به تصمیمی تجاری تبدیل کرد.
بسیاری از سازمانها برای مدیریت این مسیر از مدل معروف CRISP-DM استفاده میکنند که مخفف Cross Industry Standard Process for Data Mining است. این مدل شامل مراحلی چون فهم مسئله، جمعآوری داده، پاکسازی، تحلیل، مدلسازی، ارزیابی، ارائه و استقرار است. درک درست هر گام باعث میشود پروژه با خطا و دوبارهکاری کمتر پیش برود و نتیجه نهایی دقیقتر باشد.
در ادامه این مقاله از تکناک گامبهگام این فرآیند را بررسی میکنیم تا بدانیم چرخه حیات علم داده چگونه از پرسش اولیه تا راهحل عملیاتی پیش میرود.
01
از 09گام ۱: فهم مسئله (Business Understanding)

هر پروژه علم داده با درک درست مسئله آغاز میشود. هیچ مدلی نمیتواند بدون شناخت هدف کسبوکار پاسخ درستی بدهد. در این مرحله متخصصان داده با مدیران و ذینفعان گفتگو میکنند تا بفهمند چه تصمیمی قرار است بر اساس نتایج پروژه گرفته شود.
برای مثال شرکت خردهفروشی ممکن است بخواهد بداند چرا فروش کاهش یافته یا کدام محصولات در فصل بعد پرفروش خواهند بود. این اطلاعات به یک سوال قابل اندازهگیری تبدیل میشود؛ مثلاً پیشبینی فروش ماه آینده براساس دادههای گذشته. هدف این گام ایجاد همزبانی میان تیم فنی و تجاری است تا همه بدانند خروجی نهایی چه مشکلی را حل میکند و معیار موفقیت پروژه چیست.
ترجمه نیاز کسبوکار به یک سوال قابل اندازهگیری

ترجمه نیاز به زبان دادهمحور، نقطه اتصال بین تفکر مدیریتی و علم داده است. تحلیلگر باید خواستههای مبهم را به سوالی دقیق تبدیل کند. بهجای چرا مشتریان ریزش دارند؟ باید پرسید کدام مشتریان در سه ماه آینده احتمال خروج بیشتری دارند؟ این تبدیل به مدلسازی آماری و یادگیری ماشین جهت مشخصی میدهد. گاهی در همین مرحله مشخص میشود که دادههای کافی در دسترس نیست یا باید دادههای جدید جمعآوری شوند. وضوح در تعریف مسئله از اتلاف زمان جلوگیری کرده و پایه تصمیمگیریهای آینده را میسازد.
02
از 09گام ۲: جمعآوری و اکتساب داده (Data Acquisition)

پس از تعریف مسئله، زمان آن است که دادههای لازم جمعآوری شوند. دادهها از منابع مختلفی مانند پایگاههای داخلی سازمان، APIها، فایلهای متنی یا حتی حسگرها به دست میآیند. انتخاب منبع داده بستگی به نوع پروژه دارد؛ در برخی موارد دادههای عمومی نیز مفید واقع میشوند. دقت در این مرحله اهمیت زیادی دارد، چون کیفیت دادههای اولیه تعیینکننده کیفیت مدل نهایی است. معمولاً دادهها در این مرحله خام و نامنظماند و باید برای تحلیل آماده شوند. در حقیقت، موفقیت بیشتر پروژهها به توانایی جمعآوری دادههای درست و مرتبط بستگی دارد.
کار با دادههای ساختاریافته (SQL) و بدون ساختار (متن، تصویر)

دادهها به دو نوع کلی تقسیم میشوند: ساختاریافته و بدون ساختار. دادههای ساختاریافته در قالب جدولهایی با سطر و ستون ذخیره میشوند و معمولاً با زبانهایی مانند SQL مدیریت میگردند. در مقابل، دادههای بدون ساختار شامل متن، تصویر، صدا یا ویدئو هستند که شکل مشخصی ندارند. تحلیل این نوع دادهها نیازمند ابزارها و روشهای خاص مانند پردازش زبان طبیعی یا بینایی رایانهای است. ترکیب هر دو نوع داده به درک عمیقتری از مسئله منجر میشود و دیدگاه جامعتری به تصمیمگیرندگان میدهد.
03
از 09گام ۳: پاکسازی و پیشپردازش داده (Data Cleaning)

در هر پروژه از چرخه حیات علم داده، مرحله پاکسازی یکی از وقتگیرترین و مهمترین بخشها به شمار میآید. دادهها معمولاً دارای مقادیر ناقص، تکراری یا اشتباه هستند. حذف یا اصلاح این موارد، دقت تحلیل را بهطور چشمگیری افزایش میدهد. گاهی لازم است مقادیر گمشده جایگزین شوند یا دادههای پرت شناسایی و مدیریت گردند. پاکسازی داده در واقع تضمینی است برای اینکه مدل بر پایه اطلاعات درست آموزش ببیند. این مرحله زیرساختی محکم برای تحلیل و مدلسازی فراهم میکند و از بروز خطاهای آماری جلوگیری مینماید.
مدیریت مقادیر گمشده (Missing Values) و دادههای پرت (Outliers)

دادههای گمشده معمولاً به دلایل مختلفی ایجاد میشوند؛ مانند خطای ثبت، قطع ارتباط سنسور یا اشتباه انسانی. در این حالت، تحلیلگر باید تصمیم بگیرد که آیا ردیفهای ناقص حذف شوند یا مقدار جایگزین قرار گیرد. از سوی دیگر، دادههای پرت نقاطی هستند که با الگوی کلی تفاوت زیادی دارند. تشخیص و رسیدگی به این مقادیر از تحریف نتایج جلوگیری میکند. روشهای آماری و الگوریتمی برای شناسایی این موارد وجود دارد که بسته به نوع داده انتخاب میشوند.
هنر مهندسی ویژگی (Feature Engineering)
مهندسی ویژگی فرآیند ایجاد یا انتخاب متغیرهای مؤثر بر نتیجه نهایی است. این مرحله خلاقانهترین بخش علم داده محسوب میشود زیرا در آن تحلیلگر با ترکیب دادههای خام، ویژگیهای جدیدی میسازد که مدل بهتر یاد بگیرد. برای مثال، در تحلیل رفتار مشتری، زمان آخرین خرید یا تعداد بازدید از سایت ویژگی ارزشمندی است. انتخاب ویژگیهای مناسب دقت مدل را بالا میبرد و از پیچیدگی غیرضروری جلوگیری میکند. در واقع، مهندسی ویژگی پلی است میان داده خام و مدل هوشمند.
04
از 09گام ۴: تحلیل اکتشافی داده (EDA)
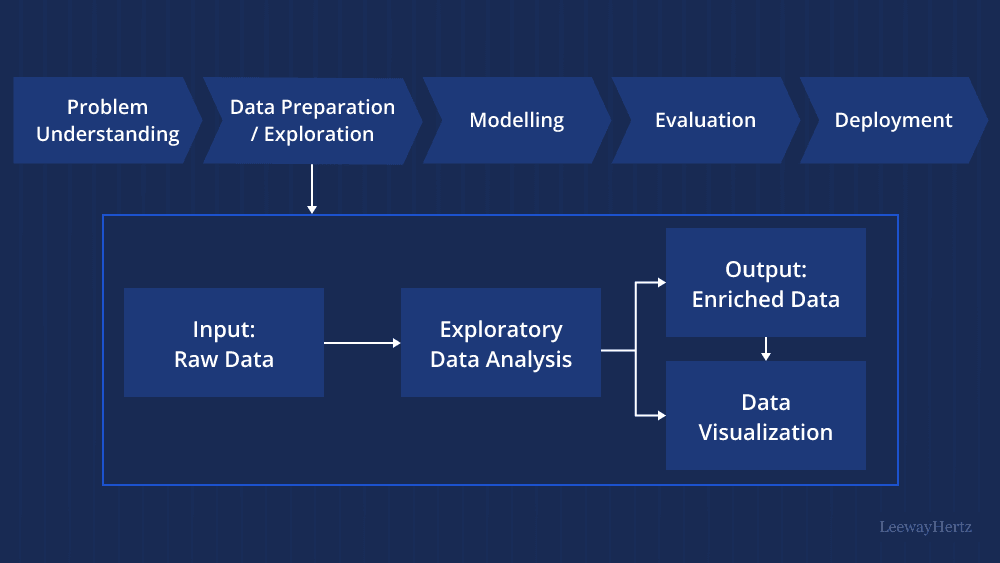
در این گام، تحلیلگر با بررسی آماری و مصورسازی، شناخت اولیه از داده به دست میآورد. تحلیل اکتشافی کمک میکند الگوها، روندها و ارتباطهای پنهان آشکار شوند. هدف این مرحله، درک عمیقتر از ماهیت داده پیش از مدلسازی است. با اجرای آزمونهای ساده و نمودارهای مختلف، میتوان فرضیههایی ساخت که در مراحل بعدی آزموده میشوند. این بخش، بینش اولیهای ایجاد میکند که گاه جهت کل پروژه را تغییر میدهد.
کشف الگوهای پنهان با مصورسازی داده (Data Visualization)

مصورسازی داده ابزاری برای تبدیل اعداد خشک به تصویری قابل درک است. با استفاده از نمودارهایی چون هیستوگرام، جعبهای یا پراکندگی، الگوهای پنهان آشکار میشوند. مصورسازی نهتنها برای تحلیلگر، بلکه برای مدیران نیز اهمیت دارد، زیرا تصمیمگیری بر اساس تصویر و نمودار آسانتر است. گاهی یک نمودار ساده، مسئلهای را نشان میدهد که ساعتها تحلیل عددی موفق به کشف آن نشدهاند.
05
از 09گام ۵: مدلسازی (Modeling)

در مرحله مدلسازی، دادههای آماده به الگوریتمهای یادگیری ماشین سپرده میشوند تا الگوهای آماری استخراج شوند. انتخاب مدل مناسب به نوع مسئله بستگی دارد؛ برای پیشبینی عدد از رگرسیون استفاده میشود و برای دستهبندی از مدلهای طبقهبندی. گاهی نیز هدف گروهبندی دادههای مشابه است که با روش خوشهبندی انجام میشود. در این گام، دادهها معمولاً به دو بخش آموزش و آزمون تقسیم میشوند تا عملکرد مدل سنجیده شود. خروجی مدل، همان پاسخ قابل استفاده در تصمیمگیری است.
انتخاب الگوریتم مناسب (رگرسیون، طبقهبندی، خوشهبندی)

هر الگوریتم برای نوع خاصی از داده و هدف کاربرد دارد. رگرسیون روابط بین متغیرهای عددی را بررسی میکند، طبقهبندی برای پیشبینی گروهها به کار میرود و خوشهبندی برای کشف ساختارهای پنهان در دادههای بدون برچسب مناسب است. شناخت درست از داده و هدف باعث انتخاب صحیح الگوریتم میشود. گاهی آزمایش چند مدل مختلف بهترین راه برای یافتن گزینه دقیقتر است.
اهمیت Train/Test Split در ارزیابی مدل
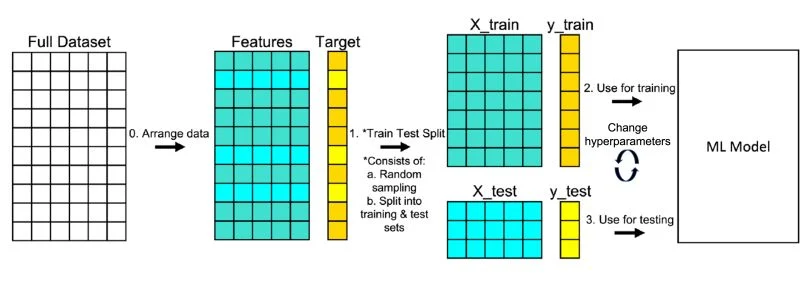
تقسیم داده به مجموعه آموزش و آزمون روشی است برای بررسی اینکه مدل تا چه حد اطلاعات جدید را پیشبینی میکند. اگر مدل فقط بر اساس دادههای آموزشی ارزیابی شود، خطر بیشبرازش وجود دارد. با جدا کردن بخشی از داده برای آزمون، اطمینان حاصل میشود که مدل توانایی تعمیم دارد. این کار شبیه امتحان گرفتن از دانشآموز پس از یادگیری درس است تا میزان درک واقعی سنجیده شود.
06
از 09گام ۶: ارزیابی و تنظیم مدل (Evaluation)
پس از آموزش مدل، زمان ارزیابی عملکرد فرا میرسد. در این مرحله از چرخه حیات علم داده با استفاده از معیارهای مختلف مانند دقت، بازخوانی یا میانگین خطا، میزان صحت پیشبینیها بررسی میشود. ارزیابی کمک میکند بدانیم مدل در دنیای واقعی چقدر قابل اعتماد است. گاهی نتایج نشان میدهد باید دادهها یا پارامترهای مدل اصلاح شوند تا عملکرد بهتر شود. هدف اصلی این گام دستیابی به توازنی میان دقت و سادگی مدل است.
معیارهای ارزیابی: ماتریس درهمریختگی (Confusion Matrix)

ماتریس درهمریختگی یکی از ابزارهای مهم برای بررسی مدلهای طبقهبندی است. این ماتریس نشان میدهد مدل چه تعداد از نمونهها را درست یا اشتباه پیشبینی کرده است. با کمک آن میتوان معیارهایی چون دقت، بازخوانی و امتیاز F1 را محاسبه کرد. تفسیر درست این اعداد مشخص میکند که مدل در تشخیص موارد مثبت و منفی چه عملکردی دارد. چنین تحلیلی برای بهبود عملکرد مدل حیاتی است.
تنظیم هایپرپارامترها (Hyperparameter Tuning)
هر الگوریتم مجموعهای از پارامترها دارد که باید پیش از آموزش تنظیم شوند. این پارامترها نقش کلیدی در کارایی مدل دارند. برای مثال، در جنگل تصادفی تعداد درختها یا در شبکه عصبی تعداد لایهها از این دستهاند. تنظیم دقیق این مقادیر با استفاده از روشهایی چون جستوجوی شبکهای یا تصادفی انجام میشود. هدف رسیدن به بهترین ترکیب برای افزایش دقت و پایداری مدل است.
07
از 09گام ۷: داستانسرایی و ارائه نتایج (Data Storytelling)

داستانسرایی با داده به معنای تبدیل نتایج فنی به پیامی روشن برای تصمیمگیرندگان است. مدیران معمولاً علاقهمند به جزئیات الگوریتم نیستند؛ آنها میخواهند بدانند نتیجه چه تأثیری بر کسبوکار دارد. بنابراین تحلیلگر باید یافتهها را در قالب روایت، نمودار و مثالهای قابل لمس ارائه دهد. این مرحله تعیین میکند تلاشهای فنی چگونه در تصمیمات واقعی تأثیر میگذارند. داستانسرایی مؤثر مسیر یک پروژه یا حتی استراتژی شرکت را تغییر میدهد.
تبدیل یافتههای فنی به یک داستان قانعکننده برای مدیران

یک تحلیلگر موفق کسی است که بتواند اعداد خشک را به زبان ساده برای مدیران ترجمه کند. مثلاً به جای بیان مدل دقت ۹۵ درصدی دارد، باید گفت این مدل به شما کمک میکند مشتریان وفادار را دقیقتر شناسایی کنید. استفاده از نمودارهای واضح، مثالهای واقعی و پیام نهایی شفاف باعث میشود تصمیمگیرندگان با اعتماد بیشتری از نتایج استفاده کنند. این مهارت کلید تأثیرگذاری علم داده بر دنیای کسبوکار است.
08
از 09گام ۸: استقرار و نظارت (Deployment & Monitoring)

پس از تکمیل مدل و تأیید آن، زمان استفاده در محیط واقعی است. استقرار یعنی مدل به بخشی از سیستم عملیاتی سازمان تبدیل شود. اما کار در اینجا تمام نمیشود؛ دادههای ورودی ممکن است در آینده تغییر کنند و عملکرد مدل کاهش یابد. برای جلوگیری از این مسئله باید بر رفتار مدل نظارت مداوم انجام شود. ترکیب فرایندهای توسعه، استقرار و پایش در مفهومی به نام MLOps خلاصه میشود که نقش مهمی در پایداری پروژههای داده دارد.
مفهوم MLOps و نظارت بر Model Drift
MLOps به معنای مدیریت چرخه عمر مدلهای یادگیری ماشین است؛ از ساخت و آزمایش گرفته تا استقرار و نگهداری. یکی از چالشهای اصلی در این حوزه، پدیده Model Drift است؛ یعنی تغییر تدریجی الگوی دادهها در طول زمان که باعث افت عملکرد مدل میشود. پایش مستمر شاخصها و بهروزرسانی دورهای مدل از بروز این مشکل جلوگیری میکند و اطمینان میدهد سیستم همچنان دقیق عمل میکند.
09
از 09سوالات متداول (FAQ)
بیشتر متخصصان داده معتقدند پاکسازی و آمادهسازی داده دشوارترین بخش است، زیرا خطاهای کوچک در این مرحله اثر بزرگی بر نتیجه دارند. حجم زیاد داده و ناهمگونی منابع نیز بر پیچیدگی کار میافزاید.
EDA یا تحلیل اکتشافی داده یعنی شناخت اولیه از داده از طریق آمار و نمودار. در این مرحله تحلیلگر ساختار کلی داده را درک کرده و فرضیههایی برای مدلسازی بعدی میسازد.
مهندسی ویژگی فرآیندی است که طی آن از داده خام، متغیرهای معنادار و تأثیرگذار ساخته میشود. این کار به مدل کمک میکند تا الگوها را بهتر یاد بگیرد و دقت پیشبینی افزایش یابد.
مدل CRISP-DM ساختاری استاندارد و جامع دارد که تقریباً در تمام صنایع کاربرد دارد. مزیت آن در سادگی و انعطافپذیری است؛ بهگونهای طراحی شده که در پروژههای کوچک و بزرگ قابل استفاده باشد.