شیائومی با عبور از تمرکز صرف بر بازار تلفنهای هوشمند، پلتفرم تحت وب هوش مصنوعی خود را که از جدیدترین و سریعترین مدل زبانی این شرکت قدرت میگیرد، برای آزمایش عمومی عرضه کرد.
به گزارش سرویس هوشمصنوعی تکناک، شرکت شیائومی در اقدامی که یکی از بزرگترین دستاوردهای این کمپانی در حوزه هوش مصنوعی محسوب میشود، دسترسی به پلتفرم جدید وبمبنای خود را که عملکردی مشابه ChatGPT دارد، برای عموم کاربران آزاد کرد. این پلتفرم بر پایه مدل هوش مصنوعی تازه نفس «MiMo-V2-Flash» بنا شده و به کاربران اجازه میدهد بدون نیاز به نصب هیچگونه نرمافزار اضافی، آخرین دستاوردهای شیائومی در مدلهای زبانی بزرگ را تجربه کنند.
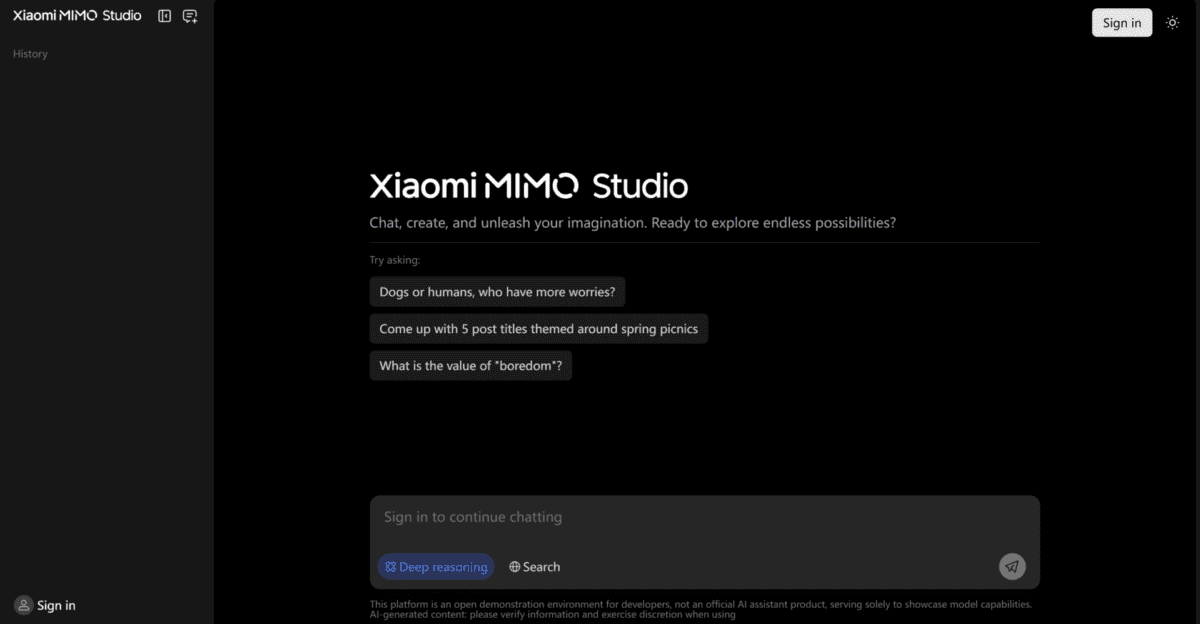
شیائومی اخیراً از «استودیو MiMO» رونمایی کرده است؛ یک پلتفرم ارتباطی تعاملی که دروازه ورود به دنیای مدل MiMo-V2-Flash محسوب میشود. این سامانه با ارائه گزینههایی نظیر «مکالمات استدلالی عمیق» و «پاسخهای تقویتشده با جستجوی آنلاین»، ابزاری کارآمد برای کدنویسی، تحقیقات و ارتقای دانش عمومی است.
علاقهمندان میتوانند هماکنون با مراجعه به وبسایت aistudio.xiaomimimo.com این هوش مصنوعی را آزمایش کنند. شیائومی اعلام کرده است که استقبال اولیه از این سرویس فراتر از انتظارات بوده و به همین دلیل ممکن است کاربران با کندی سرور یا صفهای انتظار مواجه شوند. با این حال، در فاز اولیه هیچ محدودیت جغرافیایی برای دسترسی به این سرویس وجود ندارد.

قلب تپنده این پلتفرم، مدل MiMo-V2-Flash است. یک مدل زبانی بزرگ که به صورت اختصاصی توسط شیائومی و با معماری «ترکیب خبرگان» (MoE) طراحی شده است. این مدل دارای ۳۰۹ میلیارد پارامتر کلی است که ۱۵ میلیارد آن برای استنتاج فعال هستند.
از ویژگیهای بارز فنی این مدل میتوان به موارد زیر اشاره کرد:
- معماری توجه ترکیبی: استفاده همزمان از توجه جهانی (Global Attention) و توجه پنجره لغزان (SWA).
- ظرفیت پردازش: آموزش بومی بر روی ۳۲ هزار توکن با قابلیت مقیاسپذیری تا ۲۵۶ هزار توکن.
- تخصص: بهینهسازی شده برای استدلال، تولید کدهای پیچیده و مدیریت عاملهای چندمرحلهای.
بر اساس ادعاهای فنی شیائومی، MiMo-V2-Flash در معیارهای سنجش عمومی، در میان دو مدل برتر متنباز جهان قرار دارد. مهارتهای برنامهنویسی و منطقی این مدل نه تنها از سایر مدلهای متنباز پیشی گرفته، بلکه با مدلهای منبعبسته (Closed-Source) نیز برابری میکند.
نکته قابل تأمل برای توسعهدهندگان، کاهش چشمگیر هزینههاست. شیائومی مدعی است هزینه استنتاج در این مدل به حدود ۲.۵ درصد مدلهای بسته مشابه کاهش یافته، در حالی که سرعت تولید محتوا دو برابر شده است. این ویژگیها MiMo-V2-Flash را به گزینهای جذاب برای شرکتهایی تبدیل میکند که به هوش مصنوعی مقیاسپذیر با هزینه عملیاتی پایین نیاز دارند.
به نقل از شیائومیتایم، شیائومی با انتشار وزنهای مدل و کدهای استنتاج تحت مجوز MIT، تعهد خود را به جامعه متنباز نشان داده است. علاوه بر دسترسی عمومی، توسعهدهندگان میتوانند از طریق API با قیمتهای زیر از این مدل استفاده کنند:
- ۰.۱۰ دلار به ازای هر یک میلیون توکن ورودی
- ۰.۳۰ دلار به ازای هر یک میلیون توکن خروجی
گفتنی است شیائومی برای تسهیل آزمایش و ادغام این سرویس در اپلیکیشنهای شخص ثالث، استفاده از APIها را برای مدتی محدود به صورت رایگان ارائه میدهد.