در عصر هوش مصنوعی پیشرفته، شناساگرهای هوش مصنوعی برای مبارزه با تقلب، سرقت ادبی و اطلاعات نادرست نقش مهمی را ایفا میکنند.
به گزارش تکناک، در حالی که توسعهدهندگان و شرکتها برای ایجاد شناساگرهای هوش مصنوعی با قابلیت شناسایی محتوای نوشتهشده توسط هوش مصنوعی با یکدیگر رقابت میکنند، یک مطالعه جدید از محققان دانشگاه استنفورد حقیقتی دلسردکننده را نشان میدهد و می گوید این شناساگر ها چندان قابل اعتماد نیستند.
پس از راه اندازی تبلیغاتی ChatGPT، چندین توسعه دهنده و شرکت شناساگر هوش مصنوعی، خود را معرفی کردند. این الگوریتمها بهعنوان ابزاری برای کمک به مربیان، روزنامهنگاران و دیگران در شناسایی موارد تقلب، سرقت ادبی و انتشار اطلاعات نادرست به کار میروند.
با این حال، مطالعه استنفورد همانطور که در Techxplore.com گزارش شده است یک نقص قابل توجه را نشان می دهد. شناساگرها قابلیت اطمینان نیستند، به خصوص زمانی که نویسندگان انسانی غیر انگلیسی زبان باشند.
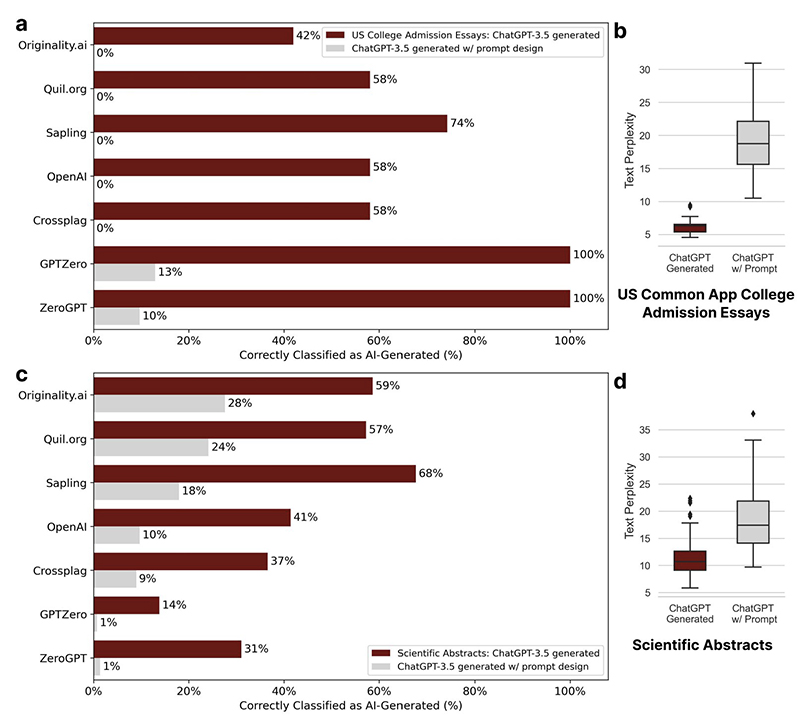
آمار تصویری تلخ را نشان می دهد. در حالی که شناساگرهای هوش مصنوعی در ارزیابی مقالههای نوشته شده توسط دانشآموزان کلاس هشتم متولد شده در آمریکا تقریباً بدون اشتباه بودند، آنها بیش از نیمی (61.22٪) از مقالات آزمون انگلیسی تافل که توسط دانشآموزان غیربومی نوشته شده بود را به عنوان هوش مصنوعی طبقهبندی کردند.
وقتی داده ها را کمی دقیق تر بررسی می کنیم، وضعیت بدتر می شود. این مطالعه نشان داد که هر هفت شناساگر هوش مصنوعی به اتفاق آرا 18 مقاله از 91 مقاله دانشآموزان تافل (19 درصد) را بهعنوان تولید شده توسط هوش مصنوعی شناسایی کردند. 89 مورد از 91 مقاله (97٪) توسط حداقل یکی شناساگرها علامت گذاری شده است.
چرا شناساگرها در دقت خود دچار تزلزل می شوند؟
پروفسور جیمز زو، کارشناس علوم داده های زیست پزشکی در دانشگاه استنفورد و نویسنده ارشد این مطالعه، دلیل غیرقابل اعتماد بودن شناساگرهای هوش مصنوعی را توضیح می دهد. زو میگوید: شناساگرها معمولاً محتوا را بر اساس پیچیدگی ارزیابی میکنند، معیاری که با پختگی در محتوای نوشتاری مرتبط است.
به طور طبیعی، انگلیسی زبانان غیر بومی تمایل دارند از نظر پیچیدگی زبانی از همتایان متولد ایالات متحده خود عقب باشند و در نتیجه نمرات کمتری در بخش پختگی نوشتاری به دست آورند.
زو و نویسندگان همکارش تاکید میکنند که نویسندگان غیربومی اغلب در معیارهای پیچیدگی مانند غنای واژگانی، تنوع واژگانی، پیچیدگی نحوی و پیچیدگی دستوری امتیاز کمتری دارند.
این آمار نگران کننده سوالات مهمی را در مورد کارایی شناساگرهای هوش مصنوعی ایجاد می کند. آنها در مواردی ممکن است دانشجویان و کارمندان خارجی را با اتهامات ناعادلانه یا حتی مجازات هایی به دلیل ادعاهای تقلب مواجه کنند. پیامدهای اخلاقی چنین سناریوهایی باعث نگرانی است.
علاوه بر این، زو اشاره می کند که شناساگرها را می توان به راحتی از طریق تکنیکی به نام “مهندسی سریع” تضعیف کرد.
با درخواست سیستم های هوش مصنوعی مولد برای بازنویسی مقالات با زبان پیچیده تر، دانش آموزانی که سعی در تقلب دارند می توانند به راحتی آشکارسازها را دور بزنند. زو یک مثال ساده ارائه می دهد، جایی که دانش آموزی که از ChatGPT استفاده می کند ممکن است متن تولید شده توسط هوش مصنوعی را با این دستور بازنویسی کند: متن ارائه شده را با استفاده از زبان ادبی بازنویسی کنید.
زو هشدار می دهد: آشکارا شناساگرهای فعلی غیرقابل اعتماد هستند و به راحتی قابل دستکاری هستند که آنها را به یک راه حل غیرقابل اعتماد برای مشکل تقلب هوش مصنوعی تبدیل می کند.
بنابراین، راه پیش رو چیست؟ زو چند رویکرد ممکن را پیشنهاد می کند. در کوتاهمدت، او توصیه میکند از اتکا به شناساگرها در محیطهای آموزشی، بهویژه جایی که تعداد قابلتوجهی از انگلیسیزبان غیربومی وجود دارد، اجتناب کنید.
توسعه دهندگان همچنین باید به عنوان معیار اصلی از پیچیدگی فراتر رفته و تکنیک های جدیدتری را کشف کنند. آنها همچنین باید سرنخهای ظریفی درباره هویت هوش مصنوعی، مانند واترمارک، در محتوای تولیدی درج کنند. در نهایت، مدل ها باید در برابر دور زدن کمتر آسیب پذیر شوند.
زو در پایان میگوید: در این زمان، شناساگرها بسیار غیرقابل اعتماد هستند و عواقب آن برای دانشآموزان بسیار زیاد است که نمیتوانیم بدون ارزیابی دقیق و پیشرفتهای قابل توجه به این فناوریها ایمان داشته باشیم.