شرکت انویدیا میگوید نرمافزار تازهای به نام TensorRT-LL که به صورت منبع باز عرضه شده است، قادر است به طور چشمگیری عملکرد مدلهای زبانی بزرگ (LLM) را بر روی GPUها افزایش دهد.
به گزارش تکناک، طبق ادعای این شرکت، قابلیتهای TensorRT-LL اجازه میدهد تا عملکرد GPU محاسباتی H100 را در مدل GPT-J LLM با شش میلیارد پارامتر به دو برابر افزایش دهد. مهمترین نکته این است که این نرمافزار قادر است این بهبود عملکرد را بدون نیاز به آموزش مجدد مدل فراهم کند.
شرکت انویدیا TensorRT-LLM را به طور خاص برای افزایش سرعت عملکرد استنتاج مدلهای زبانی بزرگ توسعه داده است و گرافیکهای عملکرد ارائه شده توسط NVIDIA در واقع نشان میدهند که بهبود سرعت H100 آن به دلیل بهینهسازیهای نرمافزاری مناسب دو برابر شده است.
یکی از ویژگی های برجسته TensorRT-LLM انویدیا، تکنیک نوآورانه دسته بندی در پرواز است. این روش به بارهای کاری پویا و متنوع مدلهای زبانی بزرگ پاسخ میدهد که میتوانند در درخواستهای محاسباتی خود با اختلاف زیادی مواجه شوند.
دستهبندی در حال پرواز (In-flight batching) بهینهسازی برنامهریزی این بارهای کاری را به حداکثر اندازه ممکن استفاده از منابع GPU تضمین میکند. به عبارتی دیگر، این روش باعث افزایش دو برابر در ظرفیت تولید درخواستهای واقعی مدلهای زبانی بزرگ بر روی GPU های Tensor Core H100 میشود و در نتیجه، فرآیندهای استنتاج هوش مصنوعی سریعتر و کارآمدتری را ارائه میدهد.
شرکت NVIDIA میگوید که TensorRT-LLM خود را با یک کامپایلر یادگیری عمیق همراه با هستههای بهینهسازی، مراحل پیشپردازش و پسپردازش و اجزای ارتباطی چند-GPU/چند-نود یکپارچه کرده است، تضمین میکند که این اجزا به طور مؤثرتری روی GPUهای خود اجرا شوند.
این یکپارچگی به وسیله یک API پایتون مدولار تکمیل شده است که رابطی مطلوب برای توسعهدهندگان فراهم میکند تا قابلیتهای نرمافزار و سختافزار را بدون نیاز به آشنایی عمیق با زبانهای برنامهنویسی پیچیده افزایش دهند. به عنوان مثال، MosaicML ویژگیهای خاصی را که نیاز داشت را به TensorRT-LLM اضافه کرده است و آنها را به صورت سازگار در سرویس استنتاج خود یکپارچه سازی کرده است.
“Naveen Rao، معاون رئیس دپارتمان مهندسی در Databricks، میگوید: ‘TensorRT-LLM در استفاده آسان است، دارای ویژگیهای فراوانی از جمله استریمینگ توکنها، دستهبندی در حال پرواز، paged-attention
، کوانتیزاسیون و غیره، و کارآمد است. این نرمافزار عملکرد برتری را برای سرویس دهی LLM با استفاده از GPUهای NVIDIA ارائه میدهد و به ما امکان میدهد تا صرفه جویی در هزینهها را برای مشتریان خود فراهم کنیم.'”
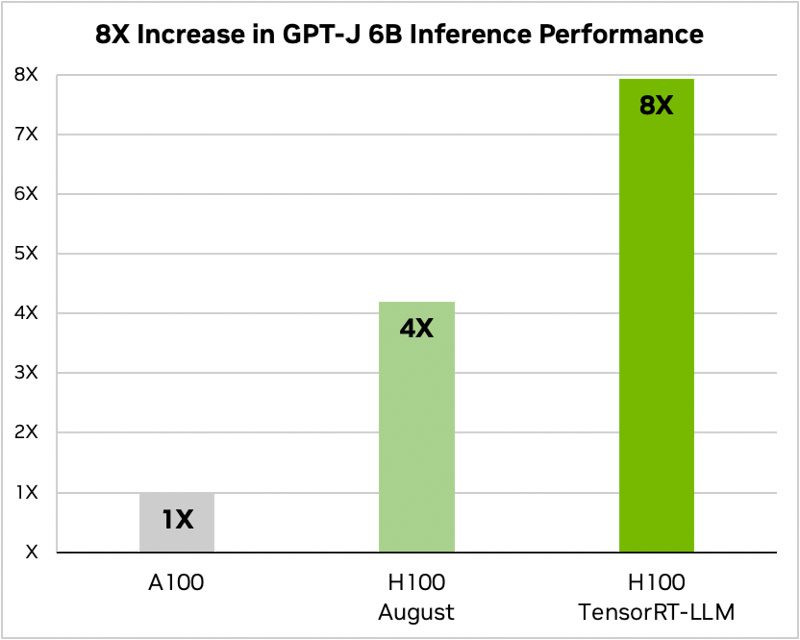
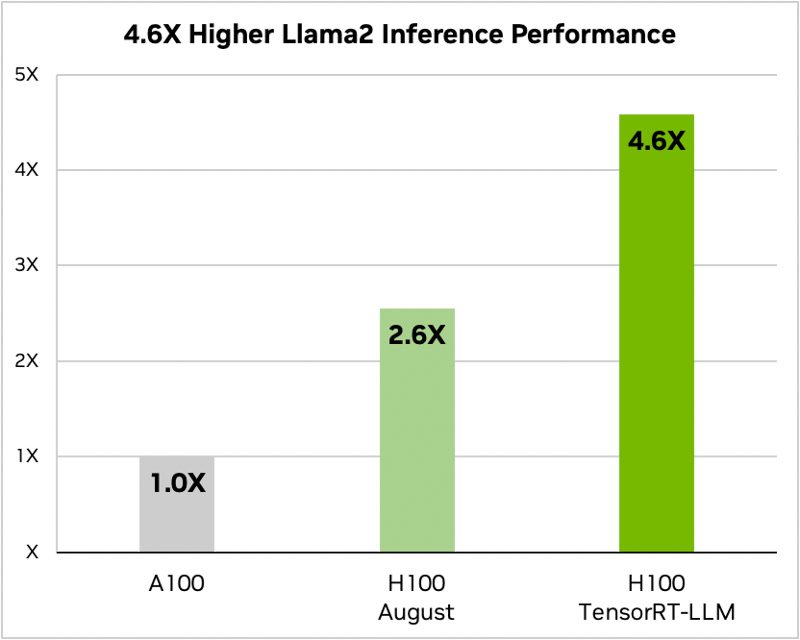
عملکرد GPU H100 از Nvidia هنگام استفاده از TensorRT-LLM بسیار تاثیرگذار است. در معماری Hopper از Nvidia، GPU H100 هنگام استفاده از TensorRT-LLM، عملکردی با ضریب هشت برابر نسبت به GPU A100 ارائه میدهد. علاوه بر این، در آزمایش مدل Llama 2 توسعه داده شده توسط متا، TensorRT-LLM نسبت به GPUهای A100، عملکرد استنتاج را با شتاب 4.6 برابر افزایش داد. این ارقام بر پتانسیل تحول آفرین نرم افزار در حوزه هوش مصنوعی و یادگیری ماشین تاکید می کند.
در نهایت، GPUهای H100 هنگام استفاده از TensorRT-LLM، فرمت FP8 را پشتیبانی میکنند. این قابلیت امکان کاهش مصرف حافظه را بدون کاهش دقت مدل فراهم می کند، که برای شرکتها و سازمانهایی که بودجه و/یا فضای دیتاسنتر محدود دارند و نمیتوانند تعداد سرور کافی را برای تنظیم LLMهای خود نصب کنند، مفید است.