
شاید خیلی ها این سوال را بپرسند که یادگیری عمیق چیست و نحوه عملکرد آن چگونه است. در این مقاله مروری بر توسعه هوش مصنوعی و سیر تحولات یادگیری عمیق و موانع پیش روی آنها خواهیم داشت.
به گزارش تک ناک، یادگیری عمیق برای نخستین بار در عصر رایانه های لامپی شکل گرفت.
در سال 1958، فرانک روزنبلات از دانشگاه کرنل اولین شبکه عصبی مصنوعی را طراحی کرد و این شبکه عصبی بعدها “یادگیری عمیق” نام گرفت. روزنبلات می دانست که این فناوری از قدرت محاسباتی در آن زمان پیشی گرفته است. او معتقد بود با افزایش گره های اتصال شبکه عصبی کامپیوترهای دیجیتال سنتی به زودی نمی توانند بار محاسباتی را تحمل کنند.

خوشبختانه، سخت افزار کامپیوتر در طول دهه ها به سرعت پیشرفت کرده است. این پیشرفت ها حتی باعث می شود محاسبات حدود 10 میلیون بار سریعتر انجام شود. در نتیجه، محققان در قرن بیست و یکم قادر به پیاده سازی شبکه های عصبی هستند.
اکنون ارتباطات بیشتری برای شبیه سازی پدیده های پیچیده تر وجود دارد. امروزه یادگیری عمیق به طور گسترده در زمینه های مختلف مورد استفاده قرار گرفته است. در بازی، ترجمه زبان، تجزیه و تحلیل تصاویر پزشکی و غیره استفاده شده است.
رشد یادگیری عمیق بسیار قوی است، اما آینده آن احتمالاً پر از دست انداز خواهد بود. محدودیتهای محاسباتی که روزنبلات نگران آن است، ابری است که بر فراز حوزه یادگیری عمیق سایه انداخته است.
یادگیری عمیق نتیجه توسعه طولانی مدت سیستمهای هوش مصنوعی است. سیستم های اولیه هوش مصنوعی بر اساس منطق و قوانینی بود که توسط متخصصان انسانی ارائه شده بود. به صورت تدریجی، اکنون پارامترهایی به وجود آمده است که می توان آنها را برای یادگیری توسط هوش مصنوعی تنظیم کرد. امروزه، شبکههای عصبی میتوانند ساخت مدلهای رایانهای بسیار انعطافپذیر را بیاموزند. خروجی شبکه عصبی دیگر نتیجه یک فرمول واحد نیست و اکنون از عملیات بسیار پیچیده استفاده می کند. یک مدل شبکه عصبی به اندازه کافی بزرگ می تواند هر نوع داده ای را تجزیه و تحلیل کند.
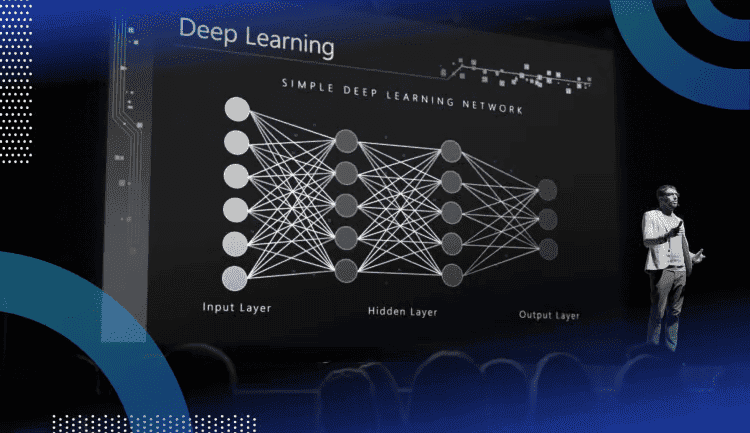
بین “رویکرد سیستم متخصص” و “رویکرد سیستم انعطاف پذیر” تفاوت وجود دارد. اجازه دهید وضعیتی را در نظر بگیریم که در آن از عکس اشعه ایکس برای تعیین اینکه آیا بیمار سرطان دارد یا خیر استفاده می شود. عکس رادیوگرافی با چندین جزء و ویژگی ارائه خواهد شد. با این حال، ما نمی دانیم که کدام یک از آن اجزا یا ویژگی ها مهم هستند.سیستم های متخصص با استفاده از افراد متخصص مشکلات و مسائل را حل میکنند. آنها متغیرهای مهم را مشخص می کنند و به سیستم اجازه می دهند فقط آن متغیرها را بررسی کند. این روش به مقدار کمی محاسبه نیاز دارد. بنابراین، به طور گسترده مورد استفاده قرار گرفته است. اما اگر کارشناسان نتوانند متغیرهای کلیدی را مشخص کنند، گزارش سیستم با شکست مواجه خواهد شد.
روشی که سیستمهای منعطف برای حل مسائل مورد نظر قرار میدهند، بررسی هر چه بیشتر متغیرهاست. سپس سیستم خودش تصمیم می گیرد که کدام یک از متغیرها مهم هستند. این روش نیاز به داده های بیشتر و هزینه های محاسباتی بالاتری دارد. همچنین کارایی کمتری نسبت به سیستم های متخصص دارد. با این حال، با توجه به داده ها و محاسبات کافی، سیستم های انعطاف پذیر می توانند از سیستم های خبره بهتر عمل کنند.
مدل های یادگیری عمیق پارامترهای بزرگی دارند
مدل های یادگیری عمیق بیش از حد پارامتر دارند. این بدان معنی است که پارامترهای بیشتری نسبت به نقاط داده در دسترس برای آموزش وجود دارد. به عنوان مثال، یک شبکه عصبی سیستم تشخیص تصویر ممکن است دارای 480 میلیون پارامتر باشد. با این حال، تنها با استفاده از 1.2 میلیون تصویر آموزش داده می شود. وجود پارامترهای عظیم اغلب منجر به “تناسب بیش از حد” می شود. این بدان معناست که مدل به خوبی با مجموعه داده های آموزشی مطابقت دارد. بنابراین، سیستم ممکن است ترند کلی را درک نکند اما جزئیات را به خوبی درک کند.
یادگیری عمیق قبلاً استعدادهای خود را در زمینه ترجمه ماشینی نشان داده است. در روزهای اولیه، نرم افزار ترجمه بر اساس قوانینی که توسط متخصصان دستور زبان تدوین شده بود ترجمه می شد. در ترجمه زبانهایی مانند اردو، عربی و مالایی، روشهای مبتنی بر قانون در ابتدا از روشهای یادگیری عمیق مبتنی بر آمار بهتر عمل کردند. اما با افزایش دادههای متنی، یادگیری عمیق اکنون بر سایر روشها برتری دارد. به نظر می رسد که یادگیری عمیق تقریباً در همه حوزه های کاربردی برتر است.
هزینه محاسباتی هنگفت
قاعده ای که برای همه مدل های آماری اعمال می شود این است که برای بهبود عملکرد به اندازه K، به2K داده برای آموزش مدل نیاز دارید. همچنین، مسئله پارامترسازی بیش از حد مدل یادگیری عمیق وجود دارد. بنابراین، برای افزایش عملکرد با ضریب
K، حداقل به 4K از مقدار داده نیاز دارید. به زبان ساده، برای اینکه دانشمندان عملکرد مدلهای یادگیری عمیق را بهبود بخشند، باید مدلهای بزرگتری بسازند. این مدل های بزرگتر برای آموزش استفاده خواهند شد. با این حال، ساخت مدل های بزرگتر برای آموزش چقدر گران خواهد بود؟
برای بررسی این سوال، دانشمندان موسسه فناوری ماساچوست، دادههای بیش از 1000 مقاله تحقیقاتی یادگیری عمیق را جمعآوری کردند. نتیجه تحقیقات آنها هشدار می دهد که یادگیری عمیق با چالش های جدی مواجه است.
به عنوان مثال طبقه بندی تصاویر را در نظر بگیرید. کاهش خطاهای طبقه بندی تصاویر با بار محاسباتی زیادی همراه است. به عنوان مثال، توانایی آموزش یک سیستم یادگیری عمیق بر روی یک واحد پردازش گرافیکی (GPU) برای اولین بار در سال 2012 نشان داده شد. این کار با مدل AlexNet انجام شد. با این حال، 5 تا 6 روز آموزش با استفاده از دو GPU طول کشید. تا سال 2018، مدل دیگری به نام NASNet-A نصف میزان خطای AlexNet را داشت. با این وجود، بیش از 1000 برابر بیشتر از محاسبات استفاده می کرد.
داده های عملی بسیار بیشتر از محاسبات آنها هستند
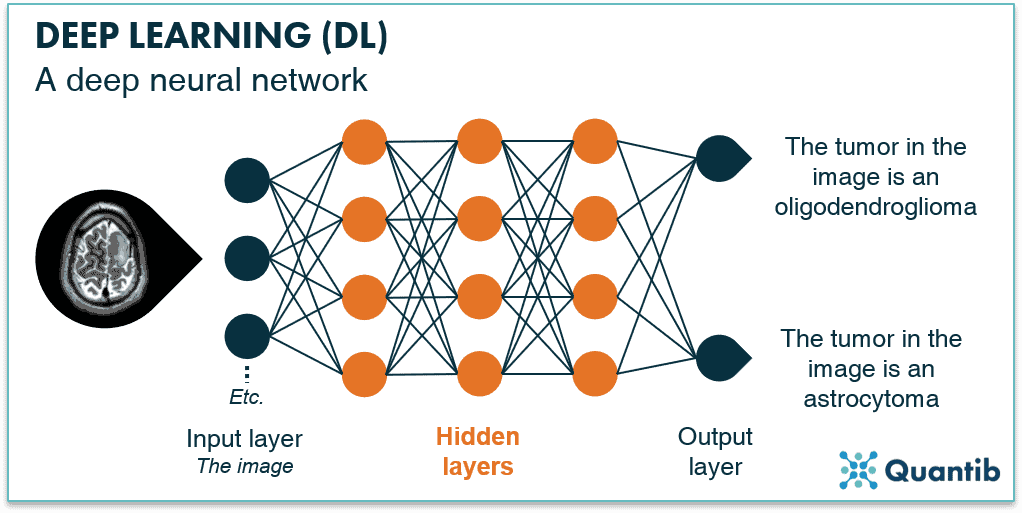
در تئوری، برای بهبود عملکرد با ضریب K، به 4K داده بیشتر نیاز داریم. با این حال، در عمل، محاسبات به ضریب حداقل 9K نیاز دارد. این بدان معناست که برای نصف کردن میزان خطا، بیش از 500 برابر منابع محاسباتی بیشتری مورد نیاز است. آموزش یک مدل تشخیص تصویر با ضریب خطای کمتر از 5 درصد 100 میلیارد دلار هزینه خواهد داشت. الکتریسیته ای که مصرف می کند، انتشار کربنی معادل انتشار کربن یک ماه در شهر نیویورک ایجاد می کند. اگر یک مدل تشخیص تصویر با ضریب خطای کمتر از 1درصد آموزش دهید، هزینه آن حتی بیشتر است.
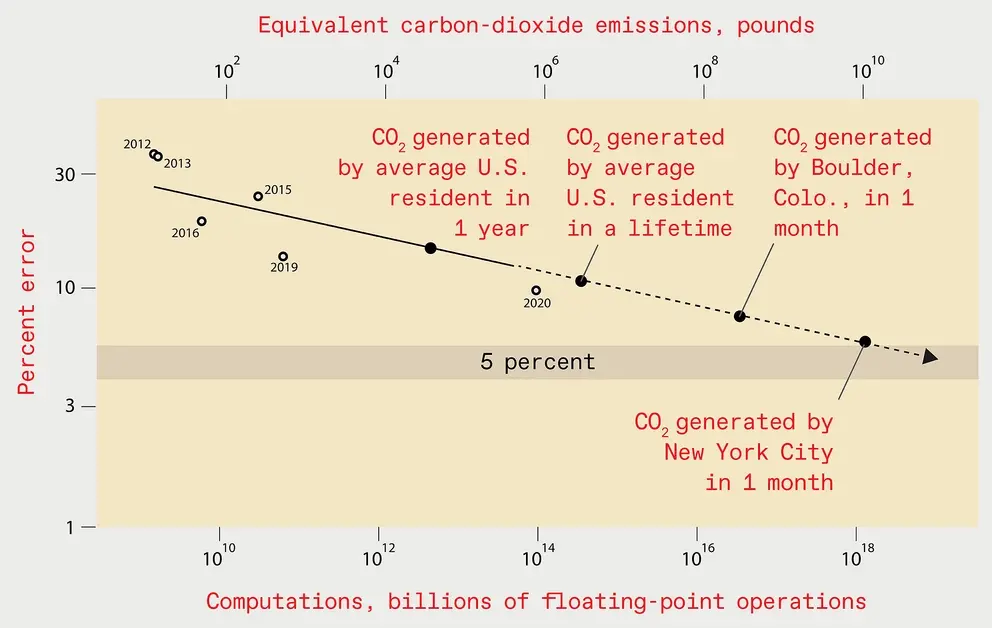
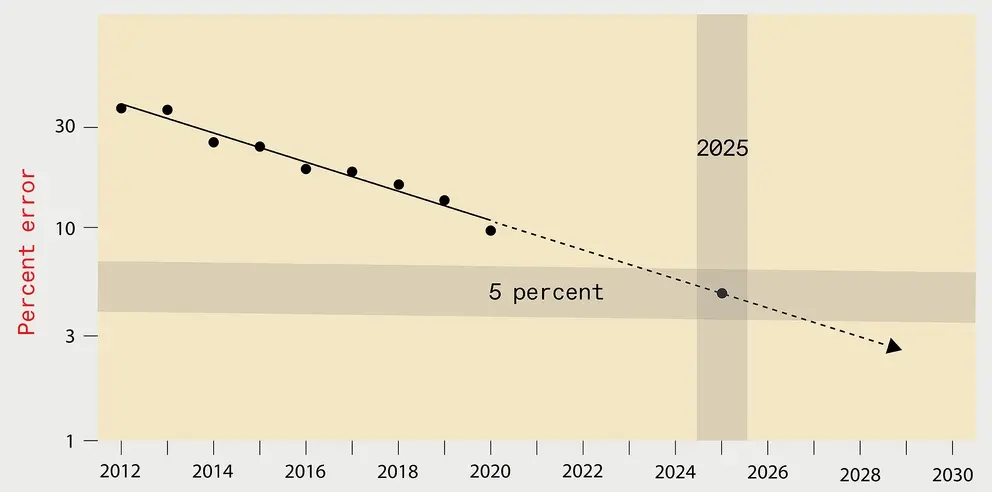
تا سال 2025، میزان خطای سیستم تشخیص تصویر بهینه به 5 درصد کاهش خواهد یافت. با این حال، انرژی مورد استفاده برای آموزش چنین سیستم یادگیری عمیقی معادل یک ماه انتشار دی اکسید کربن در شهر نیویورک است.
بار هزینه محاسباتی در سیستم های یادگیری عمیق بسیار پیشرفته آشکار شده است. OpenAI، یک اتاق فکر یادگیری ماشین، بیش از 4 میلیون دلار برای طراحی و آموزش هزینه داشته است. شرکت ها نیز شروع به دوری از هزینه محاسباتی یادگیری عمیق کرده اند. یک سوپرمارکت زنجیره ای بزرگ در اروپا اخیراً سیستم مبتنی بر یادگیری عمیق را کنار گذاشته است. این سیستم قرار بود پیشبینی کند که کدام محصولات بیشتر خریداری میشوند. مدیران شرکت به این نتیجه رسیدند که هزینه آموزش و اجرای این سیستم بسیار زیاد است.



















