
شرکت اپل در مطالعهای جدید نشان داد که استفاده از یک ترفند ساده، عملکرد مدلهای زبانی بزرگ (LLM) را به شکل قابل توجهی بهبود میدهد.
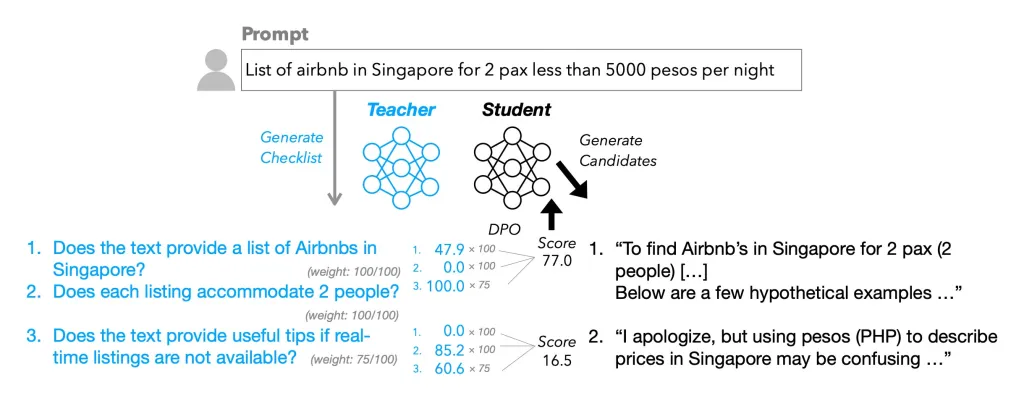
به گزارش تکناک، این روش بر پایه ایجاد فهرستهای بررسی به جای مدلهای پاداش طراحی شده است. در این مطالعه، به یک مدل متنباز LLM آموزش داده شد تا با بررسی خروجیهای خود بر اساس یک فهرست کنترل ساده، کیفیت پاسخها را ارتقا دهد.
پس از آموزش اولیه مدلهای زبانی، کیفیت آنها با مرحلهای تحت عنوان «یادگیری تقویتی با بازخورد انسانی» (RLHF) بهبود مییابد. در این فرایند، بر اساس تأیید یا رد پاسخها توسط برچسبگذاران انسانی، مدل برای ارائه خروجیهای بهتر آموزش داده میشود. این مرحله بخشی از فرایند گستردهتری به نام «همراستاسازی» است، که هدف آن اطمینان از رفتار ایمن و مفید مدلها میباشد.
شرکت اپل در این پژوهش با عنوان «چکلیستها بهتر از مدلهای پاداش برای همراستاسازی مدلهای زبانی هستند»، رویکردی جدید به نام «یادگیری تقویتی با بازخورد چکلیستی» (RLCF) را معرفی کرده است. در این روش، پاسخها بر اساس میزان انطباق با آیتمهای فهرست، در مقیاس ۰ تا ۱۰۰ امتیازدهی میشوند. نتایج اولیه نشاندهنده بهبود قابل توجه عملکرد مدلهای زبانی بزرگ بوده است.
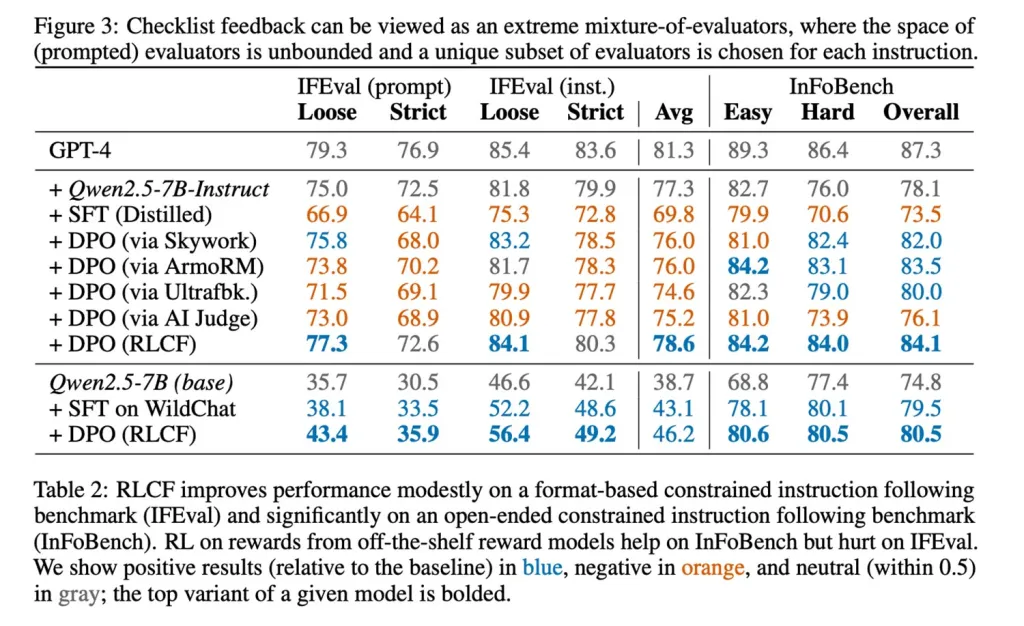
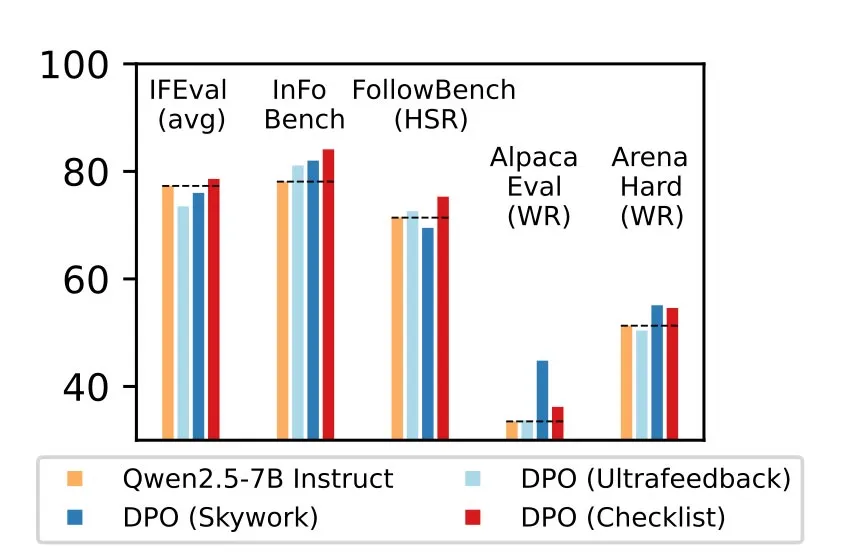
طبق گزارش محققان، این روش در پنج شاخص معتبر مورد ارزیابی قرار گرفته و تنها رویکردی بوده که در تمام آنها بهبود ایجاد کرده است، که از جمله آنها میتوان به افزایش چهار امتیازی در شاخص FollowBench، رشد شش امتیازی در InFoBench و سه امتیاز افزایش در نرخ پیروزی Arena-Hard اشاره کرد. این یافتهها اهمیت بازخورد چکلیستی را برای ارتقای توانایی مدلها در پاسخگویی به درخواستهای پیچیده اثبات میکند.
یکی از نکات برجسته این تحقیق، نحوه ایجاد چکلیستها و تعیین وزن اهمیت هر مورد است، که با کمک یک مدل زبانی بزرگ انجام شده است. اپل برای این منظور، مجموعهای به نام WildChecklists را با ۱۳۰ هزار دستورالعمل ایجاد کرده و از مدلهای مختلف سری Qwen2.5 برای تولید پاسخهای آزمایشی بهره برده است. در این فرایند، مدل بزرگتر نقش داور را ایفا میکند و پاسخها را بر اساس چکلیست ارزیابی مینماید.
نتایج نشان میدهد که این روش توانسته است تا ۸٫۲ درصد بهبود در یکی از شاخصهای آزمون مدلهای زبانی بزرگ ایجاد کند. با وجود این، پژوهشگران اذعان میکنند که این رویکرد برای «پیروی از دستورالعملهای پیچیده» طراحی شده است و لزوماً بهترین گزینه برای همه کاربردها نیست. همچنین استفاده از یک مدل قوی برای ارزیابی، از محدودیتهای این روش به حساب میآید.
با وجود این محدودیتها، این مطالعه راهکاری ساده و نوآورانه برای افزایش قابلیت اطمینان مدلهای زبانی ارائه میدهد؛ موضوعی که با گسترش استفاده از دستیارهای مبتنی بر هوش مصنوعی و قابلیتهای چندمرحلهای آنها اهمیت بیشتری پیدا میکند.




















