شرکت CoreWeave در تازهترین آزمایشهای خود نشان داده است که ابرچیپ هوش مصنوعی GB300 Blackwell انویدیا جهش عملکردی ۶ برابری نسبت به نسل قبلی خود یعنی H100 دارد.
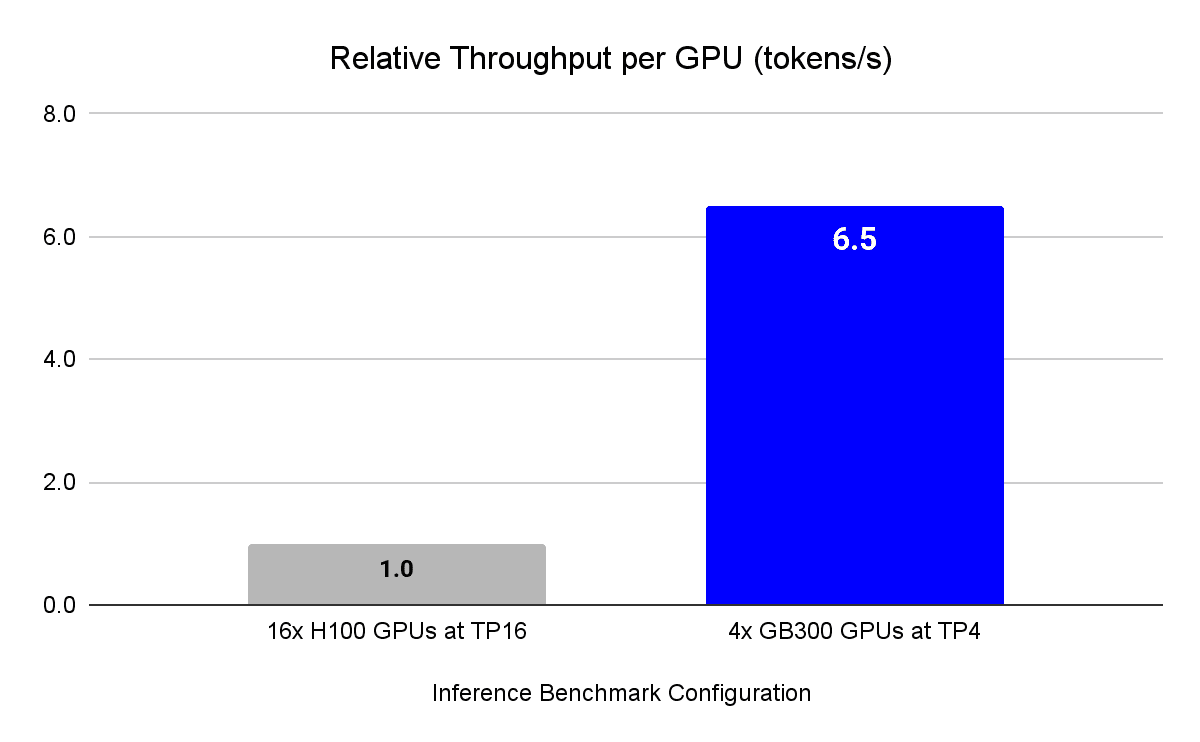
به گزارش تکناک، این بنچمارک که روی مدل پیچیده DeepSeek R1 اجرا شد، نشان میدهد که پلتفرم GB300 NVL72 با استفاده از چهار GPU، عملکردی معادل و حتی بسیار فراتر از خوشهای متشکل از شانزده GPU H100 ارائه کرده است.
یکی از مهمترین عوامل این جهش عملکردی، کاهش قابل توجه نیاز به Tensor Parallelism در GB300 انویدیا است. در حالی که اجرای مدل DeepSeek R1 روی H100 نیازمند تقسیم بار پردازشی در سطح ۱۶ GPU بود، اما معماری جدید GB300 توانست همین مدل را تنها با ۴ GPU و در سطح ۴-way tensor parallelism اجرا کند. این کاهش در تقسیمبندی باعث بهبود ارتباط میان GPUها و کاهش سربار پردازشی شده است.
نتیجه این معماری بهبودیافته، دستیابی به ۶ برابر توان پردازشی بیشتر در هر GPU و ثبت سرعتی معادل ۶.۵ برابر در تولید توکنها (tokens/s) نسبت به H100 بوده است.
معماری GB300 با بهرهگیری از ظرفیت حافظه بسیار بالاتر و پهنای باند فوقالعاده سریع توانسته است محدودیتهای ارتباطی در پردازشهای سنگین هوش مصنوعی را پشت سر بگذارد. سیستم GB300 NVL72 دارای ۳۷ ترابایت حافظه (با قابلیت ارتقا تا ۴۰ ترابایت) و پهنای باندی معادل ۱۳۰ ترابایت بر ثانیه است. این ویژگیها در کنار فناوریهای NVLink و NVSwitch پرسرعت، امکان تبادل داده میان GPUها را با کمترین تأخیر ممکن فراهم میکنند.

برای سازمانها و شرکتهایی که با مدلهای عظیم هوش مصنوعی سروکار دارند، مزایای GB300 تنها در افزایش توان خام خلاصه نمیشود. این پلتفرم با کاهش سربار پردازشی و بهبود بهرهوری، باعث کاهش هزینههای سختافزاری و انرژی میشود و در عین حال امکان مقیاسپذیری بهینهتر را برای آموزش و استنتاج مدلهای پیشرفته فراهم میآورد. همچنین سرعت بالاتر در تولید توکنها و کاهش تأخیر در پردازش، تجربهای سریعتر و کارآمدتر را برای کاربران نهایی به همراه خواهد داشت.
آزمایشهای CoreWeave نشان میدهد که انویدیا با معرفی GB300 Blackwell و پلتفرم NVL72 نه تنها توانسته است رکوردهای جدیدی در توان پردازشی ثبت کند، بلکه راه را برای بهرهوری بالاتر و کاهش هزینهها در پروژههای کلان هوش مصنوعی هموار کرده است. این جهش عملکردی GB300 میتواند نقطه عطفی برای نسل بعدی زیرساختهای هوش مصنوعی و استفاده سازمانها از سختافزارهای پیشرفته انویدیا باشد.
جدول مقایسه مشخصات GB300 و H100
| ویژگیها | NVIDIA GB300 NVL72 | NVIDIA H100 |
| معماری | Blackwell | Hopper |
| تعداد GPU مورد نیاز برای اجرای DeepSeek R1 | ۴ | ۱۶ |
| توان پردازشی (در هر GPU) | ۶ برابر بیشتر نسبت به H100 | پایه مقایسه |
| سرعت پردازش توکن (tokens/s) | ۶.۵ برابر سریعتر | پایه مقایسه |
| حافظه کل سیستم | ۳۷ ترابایت (پشتیبانی تا ۴۰ ترابایت) | تا حدود ۸ ترابایت در پیکربندیهای مشابه |
| پهنای باند حافظه | ۱۳۰ ترابایت بر ثانیه | حدود ۳۲ ترابایت بر ثانیه |
| سطح Tensor Parallelism | ۴-way | ۱۶-way |
| فناوری اتصال | NVLink + NVSwitch نسل جدید | NVLink نسل قبلی |
| بهرهوری انرژی | بالاتر، به دلیل نیاز به GPU کمتر | پایینتر، به دلیل مصرف بیشتر در خوشههای بزرگ |
| کاربرد کلیدی | مدلهای بسیار بزرگ و پیچیده با سربار کمتر | مدلهای سنگین با نیاز به موازیسازی بیشتر |