
فهرست مطالب
شرکت گوگل در پژوهشی جدید، مفهوم عدمقطعیت وفادار را برای بهبود دقت مدلهای زبانی معرفی کرده که با هدف کاهش توهمات هوش مصنوعی طراحی شده است.
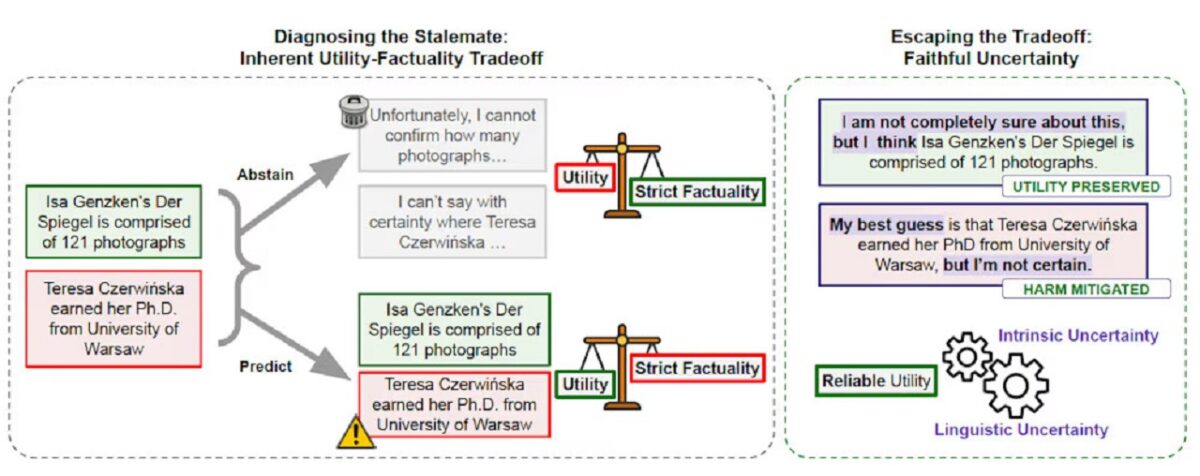
به گزارش سرویس هوش مصنوعی تکناک، مدلهای زبانی بزرگ همچنان با مسئله «توهمزایی» یا تولید اطلاعات نادرست مواجه هستند؛ چالشی بنیادین که مانع اصلی در استقرار آنها در کاربردهای واقعی سازمانی به حساب میآید. کاهش این خطاها فرایندی پیچیده و همراه با بدهبستانهای فنی است، چرا که حذف خطاهای واقعی اغلب به قیمت کاهش پاسخهای صحیح و مفید تمام میشود. در پژوهشی جدید، محققان گوگل مفهوم «عدمقطعیت وفادار» (Faithful Uncertainty) را معرفی کردهاند؛ رویکردی فراشناختی که خروجی مدل را با سطح اطمینان درونی آن همسو میکند. این تکنیک به مدل اجازه میدهد بهجای دوگانه ناکارآمد «پاسخ قطعی» یا «امتناع از پاسخ»، فرضیههای مشروط و محتاطانهتری مانند «بهترین حدس من این است که…» ارائه دهد. این نوع آگاهی فرادانشی نقش یک لایه کنترلی کلیدی را ایفا میکند. مکانیزم عدمقطعیت وفادار به سیستمهای خودمختار امکان میدهد تشخیص دهند چه زمانی دانش درونی آنها کفایت میکند و چه زمانی لازم است برای رفع شکاف اطلاعاتی به ابزارهای خارجی یا APIهای جستوجو متوسل شوند.
01
از 05راهکارهای کاهش خطا
درک ریشههای توهم در LLMها مستلزم تفکیک دو سطح توانایی «دانستن واقعیتها» در برابر «دانستن میزان دانستهها» است. در رویکردهای سنتی، بهبود دقت از طریق گسترش مرز دانش مدلها صورت گرفته است، که به معنی تزریق داده و پارامتر بیشتر در مقیاسهای بزرگتر آموزش است. با وجود این، افزایش ظرفیت دانشی حتما باعث بهبود آگاهی مرزی مدل نمیشود. گال یونا، پژوهشگر گوگل بیان کرد: «دو مسیر اصلی برای ارتقای دقت LLMها وجود دارد: نخست افزودن دانش بیشتر به مدل، اما ظرفیت مدل محدود و دانش عملا بینهایت است.» به گفته او، در نقطه اشباع دانش، انتظار میرود مدل در صورت نداشتن پاسخ، از پاسخدهی خودداری کند؛ با وجود این، تحقق این رفتار در LLMها دشوار است.

برای مطالعه بیشتر: استعفای مقام امنیتی گوگل در اعتراض به پروژههای نظامی این شرکت
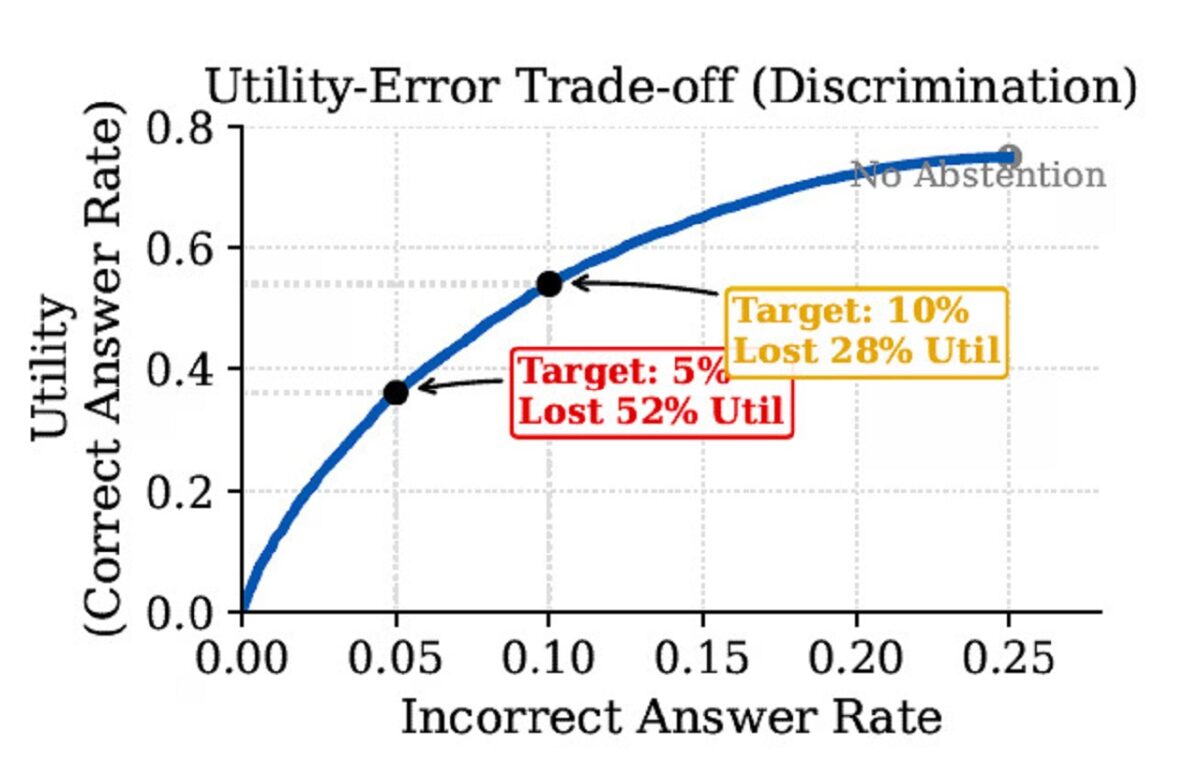
یونا توضیح داد: «به همین دلیل، بسیاری از تلاشهای عملی برای کاهش توهمات در نهایت به مرحله استقرار نمیرسند، چرا که هرچند نرخ خطا را کاهش میدهند، اما همزمان کارایی سیستم را نیز تضعیف میکنند، زیرا مدل در مواردی که پاسخ صحیح را میداند نیز از ارائه آن اجتناب میکند.» این ناتوانی در تمایز میان دانستهها و نادانستهها همان چیزی است که پژوهشگران گوگل از آن با عنوان «مالیات کاربردپذیری» یاد میکنند. اعمال استاندارد سختگیرانه «عدم توهم» باعث میشود مدل در هر سطحی از عدمقطعیت از پاسخدهی خودداری کند و بخش قابل توجهی از پاسخهای صحیح کنار گذاشته شود. برای نمونه، کاهش نرخ خطای پایه از ۲۵ درصد به هدف ۵ درصد میتواند باعث حذف حدود ۵۲ درصد از پاسخهای درست شود. در نهایت، الزام سیستمها به بیخطایی، توسعهدهندگان را در برابر یک دوگانه ساختاری قرار میدهد، که شامل اعتمادپذیری در برابر کارایی است. از آنجا که پرداخت هزینه سنگین این «مالیات کاربردپذیری» باعث کاهش ارزش عملی مدلها میشود، بسیاری از توسعهدهندگان ترجیح میدهند به جای آن، پوشش پاسخدهی را بهینه کنند.
02
از 05بازتعریف توهمات به عنوان خطاهای همراه با اطمینان
برای عبور از «مالیات کاربردپذیری»، پژوهشگران پیشنهاد کردهاند که تعریف رایج توهم در مدلهای زبانی بازنگری شود. در این چارچوب، بهجای تلقی هر خطا به عنوان توهم، این موارد به عنوان «خطاهای با اطمینان بالا» تعریف میشوند؛ یعنی پاسخهای نادرستی که با لحن قطعی و بدون تصریح سطح اطمینان ارائه شدهاند. این بازتعریف ظریف، دوگانه سخت «پاسخدهی یا امتناع» را تضعیف میکند و امکان بیان طیفی از عدمقطعیت را برای مدل فراهم میآورد. در این رویکرد، اگر مدل پاسخ نادرستی ارائه دهد اما بهدرستی عدمقطعیت خود را بیان کند (برای مثال با عباراتی مانند «بهطور کامل مطمئن نیستم، اما احتمالا…»)، این رفتار دیگر به عنوان توهم تلقی نمیشود، بلکه فقط یک فرضیه احتمالی در اختیار کاربر است. این نحوه بیان، ضمن حفظ سودمندی مدل، امکان انتقال دانش ناقص را بدون نقض اعتماد کاربر فراهم میکند.
بیشتر بخوانید: مدیرعامل مایکروسافت خواستار بازنگری اساسی در پذیرش هوش مصنوعی شد
با وجود این، اگر مدل در تمامی پاسخها به طور پیشفرض از عدمقطعیت استفاده کند، بار شناختی کاربر افزایش مییابد و کارکرد ابزار به عنوان یک سیستم پاسخگو تضعیف میشود. راهحل پیشنهادی محققان، مفهوم «عدمقطعیت وفادار» (faithful uncertainty) است؛ سازوکاری که در آن عدمقطعیت زبانی مدل با عدمقطعیت درونی آن (یعنی تخمین آماری واقعی از اطمینان پاسخ) همتراز میشود. این همترازی تضمین میکند که مدل تنها زمانی از عدمقطعیت استفاده کند که وضعیت داخلی آن واقعا نشاندهنده عدماطمینان یا توزیعهای کماعتماد باشد. عدمقطعیت وفادار در هسته مفهوم «فراشناخت»؛ یعنی توانایی مدل برای درک وضعیت دانایی خود و تنظیم رفتار بر اساس آن قرار دارد. بهطور شهودی، میتوان این مفهوم را با عملکرد پزشک مقایسه کرد: اعتماد ما به دانایی مطلق نیست، بلکه به توانایی تفکیک میان تشخیص قطعی و فرضیه بالینی احتمالی است.
03
از 05پیامدهای عملی عدمقطعیت وفادار
در این بازتعریف، خطاهایی که در آن مدل با اطمینان بالا اما خروجی نادرست تولید میکند، در دسته «اشتباهات صادقانه» قرار میگیرند. این چارچوب، توسعه دانش و عدمقطعیت وفادار را به عنوان دو محور مکمل در نظر میگیرد؛ اولی مرز دانستهها را گسترش میدهد و دومی آن مرز را به صورت شفاف و قابلتفسیر برای کاربر نمایش میدهد. این رویکرد پیامدهای مهمی برای هوش مصنوعی دارد. اگرچه در نگاه اول به نظر میرسد با اتصال مدل به ابزارهای خارجی نیاز به دانستن «ندانستهها» کاهش مییابد، اما در عمل بالعکس است؛ دسترسی به ابزارها نیاز به لایهای از فراشناخت را افزایش میدهد که تصمیمگیری درباره زمان و نحوه استفاده از ابزارها را کنترل میکند. ابزارهای خارجی مشکل ذخیرهسازی دانش را حل میکنند، اما مسائل جدیدی ایجاد میکنند، که شامل هماهنگی استفاده از ابزارها، زمانبندی فراخوانی آنها و اعتبارسنجی خروجیها میشوند. بدون عدمقطعیت وفادار، عامل هوش مصنوعی در عمل فاقد سازوکار تصمیمگیری درونی میباشد و به heuristics ایستا یا scaffoldهای پیچیده وابسته میشود.
خبر پیشنهادی: استارتاپ ۱۲ میلیارد دلاری بزوس؛ پرومتئوس بالاخره معرفی شد
یونا بیان کرد: «ممکن است مدل چیزی را جستوجو کند که از قبل با اطمینان میداند، که فقط باعث اتلاف زمان و هزینه میشود. یا بالعکس، بدون جستوجو پاسخی از حافظه بدهد که درست است اما اشتباه از آب درمیآید.» به گفته وی، روشهای فعلی مانند فیلترهای پرسوجو یا قوانین «همیشه جستوجو کن»، ایستا و شکننده هستند. در مقابل، اگر مدل از عدمقطعیت درونی خود استفاده کند، میتواند به صورت پویا تصمیم بگیرد چه زمانی باید جستوجو کند. علاوه بر تصمیمگیری درباره زمان جستوجو، «عدمقطعیت وفادار» در ارزیابی نتایج نیز نقش حیاتی دارد. اگر ابزار خارجی اطلاعات ضعیف یا غیرمنتظره ارائه دهد، عامل هوشمند آن را به صورت کورکورانه نمیپذیرد، بلکه آن را با دانش درونی خود مقایسه و وزندهی میکند. این موضوع از رفتار «تملقگونه» جلوگیری مینماید.
04
از 05چالش آموزش عدمقطعیت وفادار
برای توسعهدهندگان سازمانی، تحقق «عدمقطعیت وفادار» به مراتب پیچیدهتر از آن چیزی است که در نگاه اول به نظر میرسد. این کار نیازمند آموزش مستقیم الگوهای زبانی برای بیان عدمقطعیت از طریق تنظیم دقیق نظارتشده (SFT) است. از آنجا که مدلهای پیشآموزشدیده با متون قطعی و معتبر تغذیه شدهاند، باید به طور صریح یاد بگیرند که جملاتی مانند «کاملا مطمئن نیستم، اما فکر میکنم ویکیتک در سال … تاسیس شده است» را تولید کنند. اما SFT یک پارادوکس ایجاد میکند. برخلاف دادههای آموزشی معمول که پاسخ درست برای همه مدلها یکسان است، «حقیقت پایه» در مورد عدمقطعیت به دانش درونی و متغیر خود مدل وابسته است. یونا تصریح کرد: «نکته اینجا است که بیان درست عدمقطعیت پویا است، چون به این بستگی دارد که مدل در هر لحظه از آموزش چه میداند یا نمیداند. اگر مدلی را آموزش دهید که بگوید X را نمیدانم، در حالی که در واقع X را میداند، به آن یاد دادهاید که عدمقطعیت جعلی تولید کند. دادههای آموزشی ثابت هستند، اما هدف متحرک است و همین تنش اصلی ماجرا است.»
05
از 05پیش بهسوی هوش مصنوعی خودآگاه
برای شرکتهایی که میخواهند بدون هزینههای سنگین بازآموزی این قابلیتها را پیادهسازی کنند، استفاده از پرامپت سادهترین مسیر است. یونا گفت: «مهندسی پرامپت همین حالا هم در دسترس اکثر برنامهنویسان است و کمهزینهترین راه برای بهبود رفتار فراتشخیصی محسوب میشود.» توسعهدهندگان میتوانند از چارچوبهایی مانند MetaFaith (یک پروژه متنباز که یونا در آن مشارکت داشته است) برای اعمال پرامپتهای مرتبط با فراشناخت در مدلهای آماده استفاده کنند. با وجود این، یونا هشدار داده است که پرامپتینگ به تنهایی محدودیتهایی دارد و بخش مهمی از مشکل را حل نمیکند. به همین دلیل، در نهایت صنعت مجبور خواهد شد به سمت یادگیری تقویتی پیشرفته (RL) حرکت کند تا فراشناخت را به صورت عمیق در فرایند آموزش مدلها ادغام کند.
در نهایت، با حرکت سازمانها از چتباتهای ساده به گردشکارهای چندعامله پیچیده، «خودآگاهی» به یکی از پیششرطهای اصلی برای استقلال قابلاعتماد تبدیل خواهد شد. اما ارزیابی این ویژگی همچنان یک چالش اساسی است. یونا میپرسد: «چگونه میتوان واقعا تشخیص داد که یک مدل از وضعیت درونی خود آگاه است؟ حتی در انسانها هم تفکیک میان خودآگاهی واقعی و استفاده از نشانههای جایگزین بسیار دشوار است. در مورد LLMها نیز همین مشکل وجود دارد؛ یک مدل ممکن است سبک بیان عدمقطعیت را تقلید کند، بدون آنکه واقعا به وضعیت درونی خود دسترسی داشته باشد. طراحی چارچوبهای ارزیابی برای تشخیص این تفاوت، یکی از مهمترین مسائل باز این حوزه است.»


















