گوگل امروز خبر انتشار مدل جدید زبان بزرگ Gemini را اعلام و نسخهی بهروزشدهی TPU ابری v5p را نیز معرفی کرد.
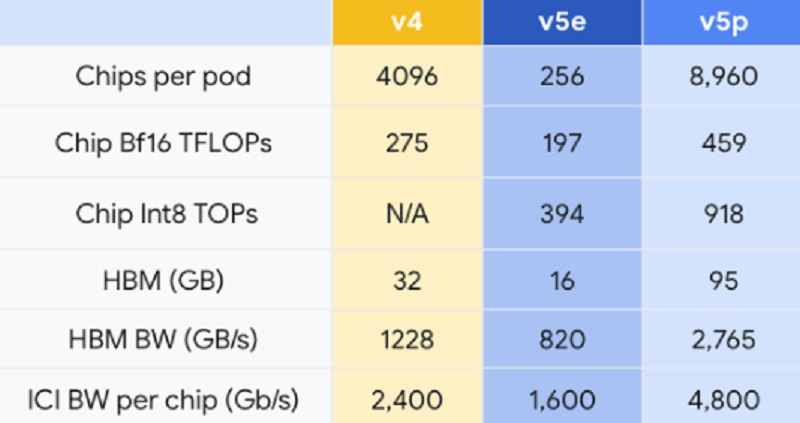
بهگزارش تکناک،این نسخهی بهروزشدهای از TPU ابری v5e است که ابتدای امسال بهطور عمومی منتشر شد. هر پاد v5p شامل 8،960 تراشه است و از سریعترین اتصال داخلی گوگل با سرعت حداکثر 4،800 گیگابیتبرثانیه در هر تراشه پشتیبانی میکند.
تککرانچ مینویسد تعجبی ندارد که گوگل ادعا میکند این تراشهها بسیار سریعتر از TPU v4 هستند. اهالی مانتینویو میگویند که v5p از بهبود دوبرابری در عملکرد FLOPS و بهبود سهبرابری در حافظه با پهنای باند بالا برخوردار است. این موضوع کمی شبیه به مقایسهی مدل جدید Gemini با مدل قدیمی OpenAI GPT 3.5 است.
بااینحال، خود گوگل درحالحاضر وضعیت را به عقب انتقال داده است و بهعبارتدیگر، پادهای v5e در بسیاری از موارد با 256 تراشهی v5e در هر پاد درمقابل 4096 در پادهای v4 و مجموعاً عملکرد نقطهی شناور 16 بیتی 197 TFLOPs در هر تراشه v5e درمقابل 275 برای تراشههای v4 نسخهی ضعیفتری از پادهای v4 بودند. برای v5p جدید گوگل حداکثر 459 TFLOPs از عملکرد نقطهی شناور 16 بیتی را با اتصال سریع قول داده است.
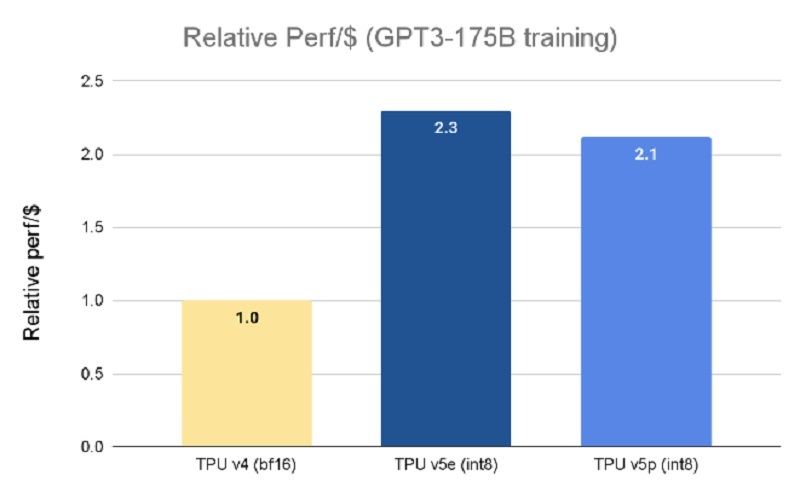
گوگل میگوید که همهی اینها بدینمعناست که TPU v5p میتواند مدل زبان بزرگی مانند GPT3-175B را 2.8 برابر سریعتر از TPU v4 آموزش و این کار را با هزینهای کمتر نیز انجام دهد. اگرچه TPU v5e کُندتر است، درمقایسهبا v5p عملکرد نسبی بیشتری در هر دلار ارائه میدهد.
جف دین، دانشمند ارشد گوگل دیپمایند و گوگل ریسرچ مینویسد:
در مراحل اولیهی استفاده، گوگل دیپمایند و گوگل ریسرچ درمقایسهبا عملکرد نسل TPU v4، دو برابر افزایش سرعت برای بارهای کاری آموزش LLM با استفاده از تراشههای TPU v5p را مشاهده کردهاند. پشتیبانی قوی از چهارچوبهای یادگیری ماشین (JAX و PyTorch و TensorFlow) و ابزارهای هماهنگسازی به ما امکان میدهد تا موثرتر در v5p مقیاسبندی کنیم.
با نسل دوم SparseCores نیز بهبود درخورتوجهی در عملکرد بارهای کاری سنگین مشاهده میشود. TPUها برای تحقق بزرگترین تلاشهای تحقیقاتی و مهندسی ما در مدلهای پیشرفته مانند Gemini بسیار حیاتی هستند.
تراشهی TPU v5p جدید هنوز بهطور عمومی دردسترس نیست؛ بنابراین، توسعهدهندگان باید با مدیر حساب گوگل خود تماس بگیرند تا در فهرست درخواستها قرار بگیرند.