
پردازندهی گرافیکی H200 با 141 گیگابایت HBM3e و پهنای باند 4.8 ترابایتبرثانیه، قدرتمندترین تراشهای است که انویدیا تاکنون ساخته است.
بهگزارش تکناک، انویدیا امروز در رویداد Supercomputing 23، سری محصولات H200 و GH200 را معرفی کرد. این تراشهها قدرتمندترین تراشههایی هستند که انویدیا تاکنون ساخته است. آنها برپایهی معماری Hopper H100 موجود ساخته شدهاند؛ اما با افزایش حافظه و قدرت محاسباتی بیشتر. این تراشهها قرار است نسل آیندهی اَبَریارانههای هوش مصنوعی را با بیش از 200 اگزافلاپس محاسبات هوش مصنوعی تغذیه کنند.
تامزهاردور مینویسد که پردازندهی گرافیکی H200 شاید ستارهی واقعی نمایش باشد. انویدیا جزئیات دقیقی از تمام مشخصات آن ارائه نکرده است؛ اما نکتهی اصلی بهنظر میرسد افزایش درخورتوجه در ظرفیت حافظه و پهنای باند بهازای هر پردازندهی گرافیکی باشد.

تراشهی جدید Nvidia H200 (American multinational technology company) از 141گیگابایت حافظهی HBM3e با سرعت 4.8 Gbps برخوردار است که درنتیجه، هر پردازندهی گرافیکی پهنای باند کلی 4.8 TB/s را فراهم میکند. این بهبودی چشمگیر درمقایسهبا H100 اصلی است که 80 گیگابایت حافظهی HBM3 و 3.35 TB/s پهنای باند داشت.
برخی از پیکربندیهای Nvidia H100 حافظهی بیشتری ارائه میکردند؛ مانند H100 NVL که دو برد را ترکیب میکرد و درمجموع 188 گیگابایت حافظه (94 گیگابایت در هر پردازنده گرافیکی) فراهم میکرد. بااینحال، درمقایسهبا H100 SXM، تراشهی جدید H200 SXM نزدیک به 76درصد ظرفیت حافظهی بیشتر و 43درصد پهنای باند بیشتری ارائه میدهد.
شایان ذکر است که عملکرد محاسباتی خام بهنظر میرسد تغییر چندانی نکرده است. تنها نموداری که انویدیا برای محاسبات نشان داد، پیکربندی هشت پردازندهی گرافیکی H200 DGX با 32 PFLOPS FP8 بهعنوان عملکرد کلی بود. H100 اصلی 3،958 ترافلاپس FP8 ارائه میداد؛ بنابراین، هشت پردازندهی گرافیکی اینچنینی بهطور تقریبی 32 پتافلاپس FP8 را فراهم میکنند.
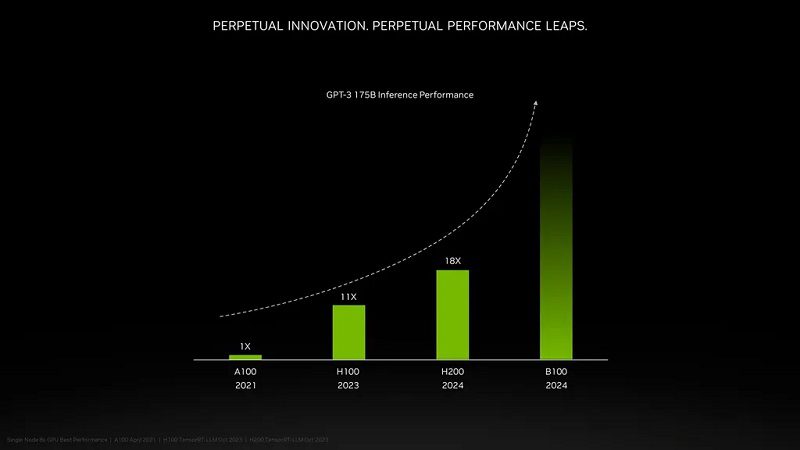
H200 درمقایسهبا H100 چقدر سریعتر خواهد بود؟ این به بار کاری بستگی خواهد داشت. برای مدلهای زبان بزرگی مانند GPT-3 که از افزایش ظرفیت حافظه بهره بسیار زیادی میبرند، انویدیا ادعا میکند عملکرد تا 18 برابر سریعتر از A100 اصلی خواهد بود؛ درحالیکه H100 تنها حدود 11 برابر سریعتر است.
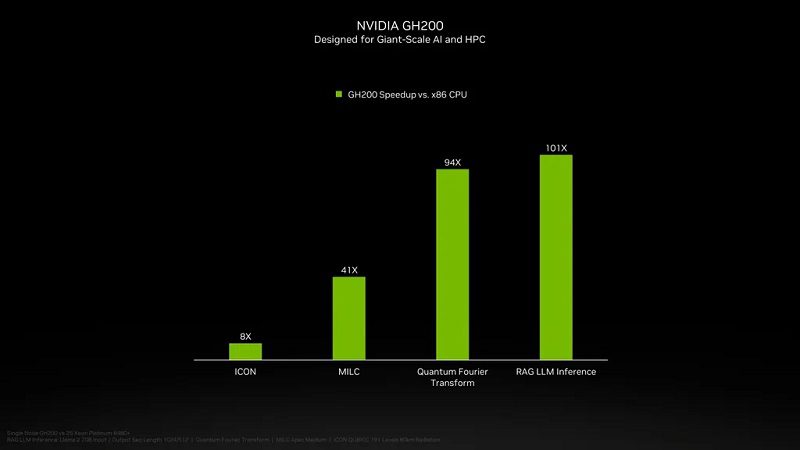
ناگفته نماند که تراشهی جدید Nvidia GH200 نیز در راه است که تراشهی H200 را با پردازندهی Grace ترکیب میکند. هر سوپرچیپ GH200 حاوی 624 گیگابایت حافظهی ترکیبی خواهد بود. تراشهی GH100 اصلی 480 گیگابایت حافظهی LPDDR5x برای پردازنده را با 96 گیگابایت حافظهی HBM3 ترکیب میکرد؛ درحالیکه نسخهی جدید از 144 گیگابایت حافظهی HBM3e استفاده میکند که قبلاً دربارهاش صحبت کردیم.

انویدیا GH200 با سیستمهای موجود H100 DGX سازگاری کامل دارد. این یعنی تراشهی H200 DGX را میتوان در همان تأسیسات برای افزایش عملکرد و ظرفیت حافظه استفاده کرد. Alps از مرکز ملی اَبَررایانه سوئیس بهاحتمال زیاد یکی از اولین اَبَررایانههای Grace Hopper که در سال آینده بهکار خواهد رفت، هنوز از GH100 استفاده میکند.
اولین سیستم انویدیا GH200 که در ایالات متحده بهکار خواهد رفت، اَبَررایانه Venado از آزمایشگاه ملی لوسآلاموس خواهد بود. سیستم Vista از مرکز محاسبات پیشرفتهی تگزاس (TACC) هم از پردازندههای Grace و سوپرچیپهای Grace Hopper استفاده خواهد کرد که امروز معرفی شد؛ اما هنوز واضح نیست که آنها H100 هستند یا H200.
شایان ذکر است که اَبَررایانه Jupiter از مرکز سوپرکامپیوتینگ یولیش (Jϋlich) حدود 24هزار سوپرچیپ GH200 را با مجموع 93 اگزافلاپس محاسبات هوش مصنوعی در خود جای خواهد داد و 1 اگزافلاپس محاسبات سنتی FP64 نیز فراهم خواهد کرد. این اَبَررایانه از بردهای چهارگانه GH200 استفاده میکند که شامل چهار سوپرچیپ GH200 هستند.



















