فهرست مطالب
پژوهشگران دانشگاه هنگکنگ (HKU) همراه با چند مؤسسه همکار، چارچوب متنباز به نام OpenCUA معرفی کردهاند که بستری قدرتمند برای توسعه عاملهای هوش مصنوعی فراهم میکند.
به گزارش تکناک، OpenCUA عاملهایی هستند که میتوانند وظایف مختلف را به صورت مستقل روی رایانه انجام دهند. این چارچوب شامل مجموعهای کامل از ابزارها، دادهها و دستورالعملهای آموزشی است، که روند توسعه عاملهای استفادهکننده از رایانه (Computer-Use Agents یا CUA) را سادهتر و در مقیاس بزرگتر ممکن میسازد.
مدلهایی که با چارچوب متنباز OpenCUA آموزش دیدهاند، در آزمونهای معیار عملکرد (CUA Benchmarks) فراتر از مدلهای متنباز دیگر ظاهر شدهاند و حتی در بسیاری از موارد فاصله خود را با عاملهای اختصاصی شرکتهای پیشرویی مانند: OpenAI و Anthropic کاهش دادهاند.
01
از 09چالشهای توسعه عاملهای رایانهای
عاملهای CUA بهگونهای طراحی شدهاند که بتوانند از کارهایی ساده مانند مرور وب و باز کردن برنامهها گرفته تا کار با نرمافزارهای حرفهای و پیچیده را بدون دخالت مستقیم انسان روی رایانه اجرا کنند. این عاملها در محیطهای سازمانی نیز میتوانند برای خودکارسازی جریانهای کاری و افزایش بهرهوری مورد استفاده قرار گیرند.
اما مشکل اصلی اینجا است که قدرتمندترین نمونههای CUA، مدلهای اختصاصی هستند و جزئیات مهمی مانند دادههای آموزشی، معماری و روش توسعه آنها کاملاً محرمانه باقی مانده است. همین موضوع باعث شده است که شفافیت کاهش یابد، سرعت پیشرفت فنی محدود شود و نگرانیهای جدی در حوزه امنیت و اعتمادپذیری بهوجود آید. پژوهشگران در مقاله خود تأکید کردهاند که جامعه علمی به چارچوبهای کاملاً متنباز نیاز دارد تا بتواند قابلیتها، محدودیتها و ریسکهای این عاملها را مطالعه و بررسی کند.
02
از 09معرفی چارچوب متنباز OpenCUA
چارچوب OpenCUA دقیقاً برای پاسخ به این چالشها توسعه یافته است. این چارچوب نه تنها به مقیاسپذیری دادهها توجه دارد، بلکه مدلها را نیز در سطح وسیعتری گسترش میدهد.
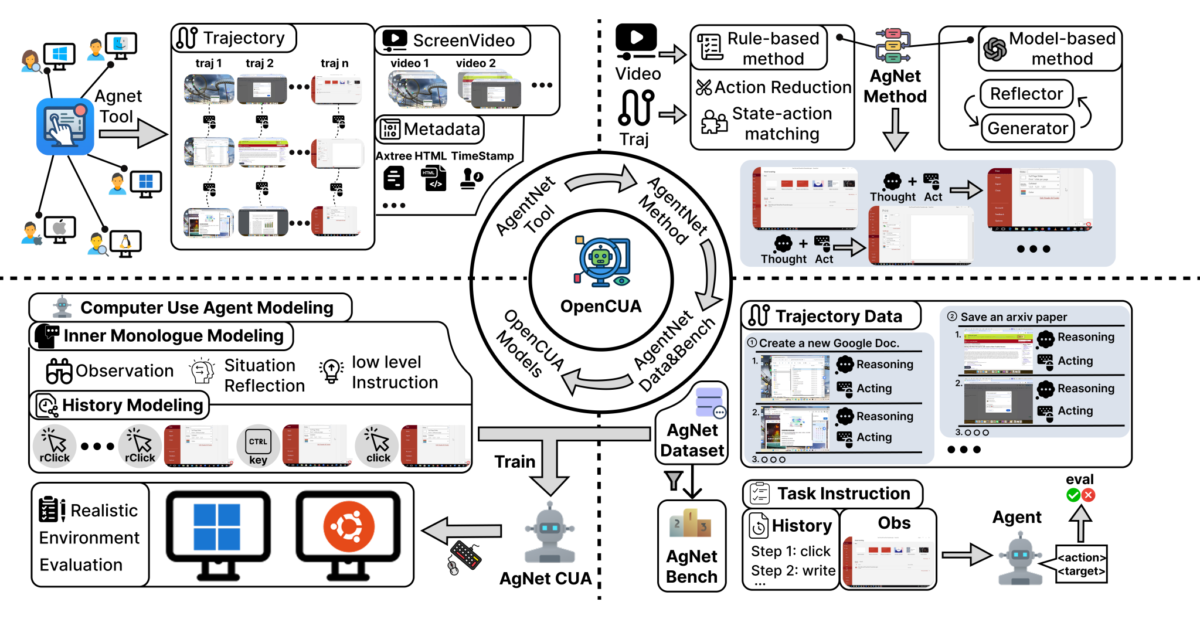
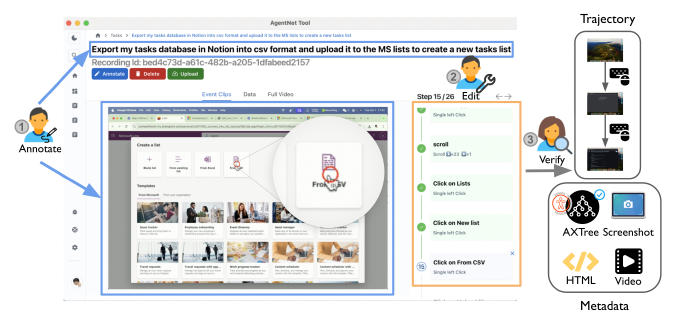
هسته اصلی OpenCUA ابزاری به نام AgentNet Tool است؛ نرمافزاری که نمایشهای انسانی از انجام وظایف رایانهای را ثبت میکند. این ابزار روی رایانه شخصی اجرا میشود و در پسزمینه، ویدیوهای صفحهنمایش، ورودیهای ماوس و صفحهکلید، حتی ساختار Accessibility Tree را ضبط میکند. دادههای خام پس از پردازش به «مسیرهای حالت-عمل» تبدیل میشوند؛ یعنی هر تصویر صفحه (State) با عمل متناظر کاربر (مانند کلیک یا فشار کلید) جفت میشود. در نهایت ثبتکنندگان میتوانند این دادهها را بررسی، اصلاح و ارسال کنند.
پژوهشگران با استفاده از همین ابزار، مجموعهدادهای عظیم به نام AgentNet Dataset گردآوری کردند که بیش از ۲۲,۶۰۰ نمایش وظیفه را در سه سیستمعامل ویندوز، macOS و Ubuntu شامل میشود. این دادهها بیش از ۲۰۰ نرمافزار و وبسایت را پوشش میدهند و پیچیدگی واقعی رفتارهای انسانی و پویایی محیطهای مختلف را منعکس میکنند.
03
از 09ملاحظات امنیت و حریم خصوصی
از آنجایی که ابزارهای ضبط صفحه میتوانند نگرانیهای حریم خصوصی برای سازمانها ایجاد کنند، AgentNet Tool با لایههای چندگانه امنیتی طراحی شده است.
- در مرحله اول، کاربر میتواند دادههای خود را پیش از ارسال بهطور کامل مشاهده کند.
- سپس دادهها هم به صورت دستی و هم به صورت خودکار توسط یک مدل زبانی بزرگ برای شناسایی اطلاعات حساس بررسی میشوند.
به گفته Xinyuan Wang، نویسنده همکار مقاله و دانشجوی دکتری در HKU، این فرایند چندمرحلهای باعث میشود که دادهها حتی در محیطهای سازمانی حساس مانند دادههای مشتریان یا مالی نیز قابل اعتماد باشند.
04
از 09AgentNetBench؛ معیار تازه برای ارزیابی
برای سرعت بخشیدن به ارزیابی عملکرد عاملها، تیم پژوهشی مجموعهای به نام AgentNetBench ایجاد کرده است، که برای هر مرحله چندین عمل درست در نظر میگیرد. این کار روشی کارآمدتر برای سنجش عملکرد عاملها فراهم میآورد.
05
از 09دستورالعمل نوین آموزش با چارچوب متنباز OpenCUA
چارچوب OpenCUA خط پردازش دادهای جدید معرفی کرده، که شامل مراحل زیر است:
- تبدیل نمایشهای انسانی به دادههای پاک و مناسب برای آموزش مدلهای بینایی-زبانی (VLM)
- افزودن استدلال «زنجیره افکار» (Chain-of-Thought یا CoT) به دادهها
استفاده از CoT کلید موفقیت این پروژه بوده است. در این روش برای هر عمل یک «گفتار درونی» ایجاد میشود، که شامل مشاهده محیط، تحلیل شرایط، برنامهریزی گام بعدی و در نهایت اقدام عملی است. این ساختار سهلایه به عاملها کمک میکند درک عمیقتری از وظایف پیدا کنند و توانایی تعمیم بیشتری داشته باشند.
این خط پردازش داده بهگونهای طراحی شده است که سازمانها نیز میتوانند آن را برای ابزارها و جریانهای کاری داخلی خود بهکار گیرند. برای مثال، یک شرکت میتواند نمایشهایی از فرایندهای اختصاصی خود ضبط کند و با همین روش، دادههای آموزشی مناسب برای عاملهای اختصاصی تولید نماید، بدون اینکه نیازی به ایجاد دستی مسیرهای استدلالی باشد.
06
از 09آزمایش و نتایج چارچوب متنباز OpenCUA
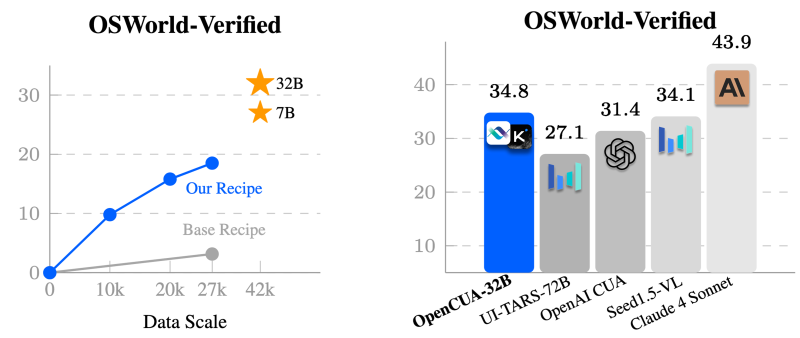
پژوهشگران این چارچوب را روی مدلهای متنباز مختلف از جمله نسخههایی از Qwen و Kimi-VL در اندازههای ۳ تا ۳۲ میلیارد پارامتر آزمایش کردند.
نتیجه برجسته، مدل OpenCUA-32B بود که در آزمون OSWorld-Verified رکورد تازهای میان مدلهای متنباز ثبت کرد. این مدل حتی از CUA مبتنی بر GPT-4o فراتر رفت و فاصله عملکردی خود با مدلهای اختصاصی Anthropic را به میزان چشمگیری کاهش داد.
07
از 09یافتههای کلیدی برای سازمانها
- روش OpenCUA روی معماریهای مختلف از جمله Dense و Mixture-of-Experts اثربخش است.
- عاملهای آموزشدیده توانایی تعمیم بالایی دارند و در وظایف گوناگون و سیستمعاملهای متفاوت، عملکرد قابل قبولی نشان دادهاند.
- این چارچوب بهویژه برای خودکارسازی وظایف تکراری و زمانبر در سازمانها کاربردی است. برای نمونه، در مجموعهداده AgentNet حتی نمایشهایی از راهاندازی سرورهای EC2 در Amazon AWS یا پیکربندی پارامترها در MTurk ثبت شده است.
با وجود این، پژوهشگران تأکید کردهاند که برای استقرار زنده این عاملها باید چالشهای مربوط به ایمنی و اعتمادپذیری برطرف شود. چرا که هر خطا ممکن است باعث تغییرات ناخواسته در تنظیمات سیستم یا ایجاد پیامدهای پیشبینینشده شود.
08
از 09آینده عاملهای رایانهای با چارچوب متنباز OpenCUA
کد منبع، مجموعهداده و وزن مدلهای آموزشدیده منتشر شدهاند تا جامعه علمی و صنعتی بتوانند از آنها استفاده کند. پژوهشگران بر این باور هستند که عاملهای متنباز توسعهیافته با OpenCUA میتوانند رابطه میان کاربران و رایانهها را دگرگون کنند.
به اعتقاد آنها، در آینده تسلط بر نرمافزارهای پیچیده اهمیت کمتری خواهد داشت و توانایی بیان شفاف هدف برای یک عامل هوش مصنوعی ارزشمندتر خواهد بود.
09
از 09دو شیوه اصلی همکاری انسان و عامل
- اتوماسیون آفلاین: جایی که عامل با تکیه بر دانش نرمافزاری خود، وظیفه را به طور کامل اجرا میکند.
- همکاری آنلاین: جایی که عامل در زمان واقعی کنار کاربر فعالیت میکند و مانند یک همکار انسانی، واکنش نشان میدهد.
در چنین آیندهای، نقش انسانها در تعیین «چه کاری» باقی میماند و عاملهای هوش مصنوعی روزبهروز پیچیدهتر، مسئولیت «چگونه انجام دادن» را بر عهده خواهند گرفت.