پلتفرم Blackwell GB300 انویدیا در بنچمارک جدید AA-AgentPerf رکورد جدیدی در عملکرد هوش مصنوعی ثبت کرده است.
به گزارش سرویس سخت افزار تکناک، این بنچمارک برای اندازهگیری عملکرد جریانهای کاری هوش مصنوعی مبتنی بر عامل یا Agentic AI طراحی شده است.
بر اساس گزارش Artificial Analysis، بنچمارک تازهای با نام AA-AgentPerf معرفی شده است که بررسی میکند یک استقرار استنتاجی تا چه تعداد عامل فعال را میتواند در شرایط کاری واقعی پشتیبانی کند. این سناریوها شامل چندین ویژگی مهم هستند.
در این آزمایشها از مسیرهای واقعی عاملها استفاده میشود؛ یعنی جلسات چندمرحلهای کدنویسی که در آنها فرایند استدلال، فراخوانی ابزارها و طول متغیر کانتکست به صورت درهمتنیده انجام میشود و پرامپتهای مصنوعی و یکنواخت نیستند.
همچنین بار کاری همزمان و پایدار شبیهسازی میشود؛ به این معنا که عاملهای مجازی به طور مداوم درخواستهای فعال در جریان دارند تا سازوکارهایی مانند استفاده مجدد از KV Cache، دیکودینگ پیشبینیگر و رفتار زمانبند سیستم تحت فشار قرار بگیرند.
سطوح عملکرد مورد انتظار یا SLO نیز بر اساس دادههای بنچمارک API بدون سرور Artificial Analysis تعریف شدهاند تا سطوح واقعی کیفیت سرویس که میان ارائهدهندگان مختلف مشاهده میشود منعکس شود.
نتایج این بنچمارک پلتفرم Blackwell GB300 انویدیا به طور مداوم بهروزرسانی میشوند تا با ورود سختافزارهای جدید، پشتههای نرمافزاری تازه و نسخههای جدید مدلها همگام باقی بمانند.
در نهایت، مدلها با بهینهسازیهای واقعی فعال و در توپولوژیهای استقرار در مقیاس تولید آزمایش میشوند تا نتایج به شرایط واقعی نزدیک باشند.
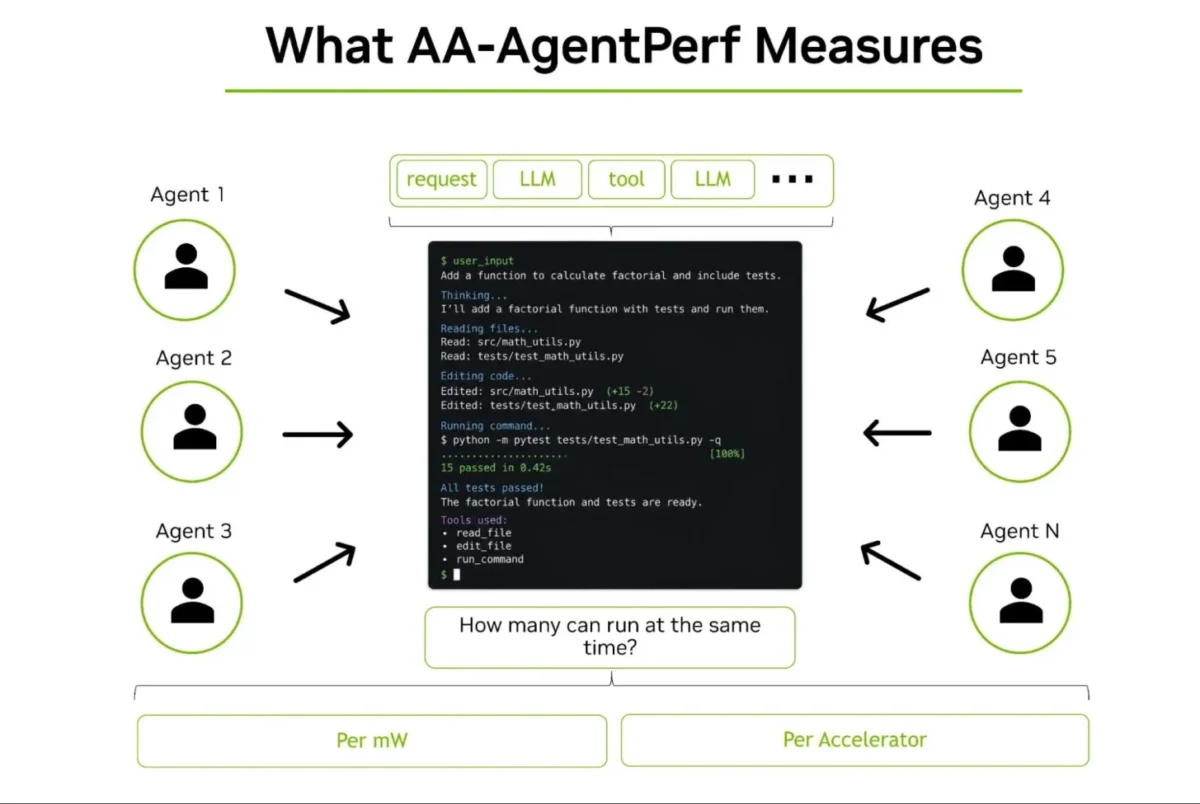
در نموداری با عنوان «AA-AgentPerf چه چیزی را اندازه میگیرد»، مجموعهای از عاملها در حال انجام یک وظیفه کدنویسی نمایش داده شدهاند که خروجیهایی مانند «۱۵ تست در ۰.۴۲ ثانیه پاس شد» و «تمام تستها با موفقیت انجام شد» تولید میکنند. در این نمودار پرسشی مطرح میشود: «چه تعداد از این عاملها میتوانند به طور همزمان اجرا شوند؟» و معیارهایی مانند «به ازای هر میلیوات» و «به ازای هر شتابدهنده» نمایش داده شده است.
بنچمارک AA-AgentPerf سه شاخص کلیدی را اندازهگیری میکند که پایه بسیاری از استقرارهای مدرن هوش مصنوعی به حساب میآیند.
- اولین شاخص Time to First Token یا TTFT است که مدت زمان بین ارسال درخواست تا دریافت اولین توکن خروجی را برای هر درخواست اندازهگیری میکند.
- شاخص دوم Output Speed است که سرعت تولید توکنهای خروجی در هر ثانیه را پس از دریافت اولین توکن محاسبه میکند.
- شاخص سوم System Output Throughput است که مجموع توکنهای خروجی تولیدشده در هر ثانیه توسط همه عاملهای همزمان را اندازه میگیرد.
شرکت انویدیا اکنون نخستین نتایج خود در بنچمارک AgentPerf را با استفاده از مدل DeepSeek V4 Pro روی پلتفرم GB300 NVL72 منتشر کرده است. این مدل نمونهای از مدلهای Frontier محسوب میشود که امروزه موتور اصلی بسیاری از عاملهای هوش مصنوعی هستند و کاربرد گستردهای در حوزه AI دارند.
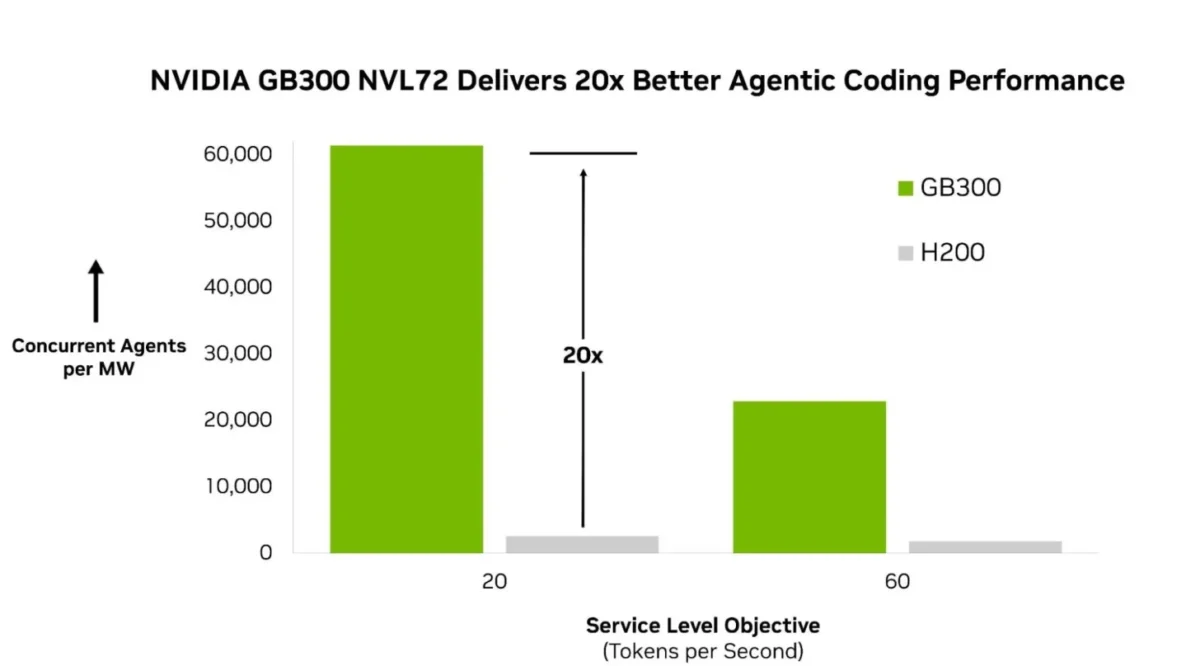
در یک نمودار میلهای با عنوان «پلتفرم NVIDIA GB300 NVL72 عملکرد کدنویسی مبتنی بر عامل را ۲۰ برابر بهبود میدهد»، نشان داده شده است که GB300 از نظر تعداد عاملهای همزمان به ازای هر مگاوات عملکرد بسیار بهتری نسبت به H200 دارد.
در نخستین دور آزمایشها، پلتفرم GB300 انویدیا سریعترین عملکرد ثبتشده را ارائه داده و در معیار عملکرد به ازای هر مگاوات، حدود ۲۰ برابر جلوتر از پلتفرم قدیمیتر HGX H200 قرار گرفته است. این سیستم میتواند تا حدود ۶۰ هزار عامل همزمان به ازای هر مگاوات انرژی را پشتیبانی کند که جهشی بسیار بزرگ نسبت به معماری Hopper محسوب میشود.
بر اساس دادههای بنچمارک، شاخص Concurrent agents per MW که بهرهوری انرژی را اندازه میگیرد و نشان میدهد یک سیستم با بودجه انرژی مشخص از چند عامل فعال پشتیبانی میکند، برای پلتفرم GB300 NVL72 برابر با ۶۱.۴ هزار عامل ثبت شده، در حالی که این عدد برای H200 حدود ۲.۶ هزار عامل است.
همچنین در شاخص Concurrent agents per GPU که میزان ظرفیت سرویسدهی هر GPU را نشان میدهد، GB300 توانسته است به عدد ۵۷.۵ عامل همزمان به ازای هر GPU برسد، در حالی که این رقم برای H200 تنها حدود ۱.۴ عامل گزارش شده است.
بر اساس گزارش Wccftech، انویدیا اعلام کرده است که این نتایج نشان میدهد پلتفرم GB300 NVL72 و معماری Blackwell توانایی اجرای بارهای کاری بزرگ کدنویسی مبتنی بر عامل را دارند و در عین حال میتوانند GPUها را در چندین جلسه همزمان عاملها به طور کامل درگیر نگه دارند.
در ادامه مسیر توسعه، معماری Rubin انویدیا نیز در افق نزدیک قرار دارد و انتظار میرود این برتری عملکرد را بیش از پیش افزایش دهد. این معماری جدید با یک طراحی بسیار قدرتمند برای هوش مصنوعی عرضه خواهد شد که توان محاسباتی ۵۰ پتافلاپس را از طریق NVFP4 ارائه میدهد. همچنین با استفاده از پردازنده Vera، فراخوانی ابزارهای LLM و عملکرد سرتاسری سیستم نیز بهبود چشمگیری در سرعت و بهرهوری خواهند داشت.