
برای اولین بار تحقیقاتی در حال انجام است، که بر اساس آن ذهن یک هوش مصنوعی کالبدشکافی و افکار آن ویرایش خواهد شد.
به گزارش تکناک، درک اینکه مدلهای هوش مصنوعی چگونه «فکر میکنند» ممکن است برای بقای بشریت حیاتی باشد. تا همین اواخر، هوشهای مصنوعی مانند: GPT و Claude برای سازندگان خود همانند یک راز بودند. امّا اکنون، محققان میگویند که میتوانند ایدهها را در مغز یک هوش مصنوعی کشف کنند و حتی آنها را تغییر دهند.
اگر به استدلالهای تا حدی قانعکنندۀ افرادی که خطرات هوش مصنوعی را هشدار میدهند، گوش دهید، متوجه میشوید که نسلهای آیندۀ هوش مصنوعی خطری عمیق برای بشریت را به نمایش میگذارند. حتی به طور بالقوه خطری برای بقای انسان خواهند بود.
همۀ ما دیدهایم که چگونه به راحتی میتوان برنامههایی مانند ChatGPT را فریب داد تا حرفهای نامناسبی بزنند، یا کارهای ناشایستی انجام دهند. ما دیدهایم که آنها سعی میکنند تا اهداف خود را پنهان نمایند و به دنبال کسب و تثبیت قدرت باشند. هر چه هوشهای مصنوعی از طریق اینترنت دسترسی بیشتری به دنیای فیزیکی پیدا کنند، در صورت تصمیمگیری، توانایی بیشتری برای ایجاد آسیب به روشهای خلاقانۀ مختلف خواهند داشت.
چرا آنها چنین کاری انجام میدهند؟ ما نمیدانیم. در واقع، کارکردهای درونی آنها کم و بیش کاملاً برای شرکتها و افرادی که آنها را میسازند، ناشناخته است.
فهرست مطالب
01
از 01ذهنهای بیگانۀ غیرقابل درک مدلهای هوش مصنوعی
این قطعههای نرمافزار، بسیار متفاوت از اکثر مواردی هستند که تاکنون با آنها مواجه شدهایم. سازندگان آنها معماری، زیرساخت و روشهایی را ایجاد کردهاند که با استفاده از آنها، ذهنهای مصنوعی میتوانند نسخۀ خود از هوش را توسعه دهند. حجم عظیمی از متن، ویدیو، صدا و دادههای دیگر را به آنها دادهاند، امّا از آن نقطه به بعد، هوشهای مصنوعی پیش رفتهاند و «درک» خود را از جهان ساختهاند.
هوش مصنوعی این گنجینههای عظیم داده را به قطعات کوچکی به نام توکن تبدیل میکنند، گاهی اوقات این کار را با بخشهایی از کلمات، برخی مواقع با بخشهایی از تصاویر یا تکههایی از صدا، انجام میدهند. سپس مجموعهای فوقالعاده پیچیده از وزنهای احتمالی که توکنها را به یکدیگر و گروههای توکن را به گروههای دیگر ارتباط میدهد، ایجاد میکنند. به این ترتیب، آنها شبیه به مغز انسان هستند، ارتباط بین حروف، کلمات، صداها، تصاویر و مفاهیم انتزاعیتر را مییابند و آنها را به یک شبکۀ عصبی incredibly complex (بهشدت پیچیده) تبدیل میکنند.
این ماتریسهای عظیم مملو از وزنهای احتمالی، «ذهن» یک هوش مصنوعی را نشان میدهند و توانایی آن را در دریافت ورودیها و پاسخ با خروجیهای خاص هدایت میکنند. شبیه به مغز انسان که الهامبخش طراحی هوش مصنوعی بوده، باعث شده است که فهمیدن اینکه دقیقاً به چه چیزی «فکر میکنند» یا چرا تصمیمات خاصی میگیرند، تقریباً غیرممکن باشد.
من به شخصه آنها را به عنوان ذهنهای عجیب بیگانهای تصور میکردم که در جعبههای سیاه قفل شدهاند. آنها فقط میتوانند از طریق خطوط محدودی که اطلاعات میتواند از آنها وارد و خارج شود، با جهان ارتباط برقرار کنند و تمام تلاشها برای «تطبیق» این ذهنها برای کار کردن به طور مؤثر، ایمن و بیآزار در کنار انسانها در سطح خطوط انجام شده است و در حد خود «ذهنها» نیست.
ما نمیتوانیم به آنها بگوییم چه فکری داشته باشند، نمیدانیم کلمات بیادبی یا مفاهیم شیطانی در کجای مغزشان زندگی میکند، فقط میتوانیم آنچه را که میتوانند بگویند و انجام دهند را محدود کنیم، مفهومی که اکنون دشوار است، امّا با باهوشتر شدن آنها، به طور فزایندهای سختتر میشود.
درکپذیری: نگاهی به درون جعبۀ سیاه
تیم «درکپذیری» (Interpretability) شرکت انتروپیک در یک پست وبلاگی خود در اواخر ماه مه مینویسد:
«امروز، ما پیشرفت قابل توجهی را در درک عملکرد داخلی مدلهای هوش مصنوعی گزارش میکنیم. ما چگونگی نمایش میلیونها مفهوم را در مدل کلود سونِت (Claude Sonnet)، یکی از مدلهای زبان بزرگ مستقر شدۀ خود، شناسایی کردهایم. این اولین نگاه دقیق به درون یک مدل زبان بزرگ مدرن و درجه یک است. این کشف درکپذیری میتواند در آینده به ما کمک کند تا مدلهای هوش مصنوعی را ایمنتر کنیم.»
بهطور کلی، تیم انتروپیک «حالت داخلی» مدلهای هوش مصنوعی خود را در زمان کار ردیابی کرده است. به این صورت که این مدلها لیستهای بزرگی از اعداد را به عنوان نمایندۀ «فعالسازی نورونها» در مغزهای مصنوعی خود هنگام تعامل با انسانها تولید میکنند. تیم مینویسد:
«مشخص شد که هر مفهوم در سراسر بسیاری از نورونها نمایش داده میشود و هر نورون در نمایش مفاهیم زیادی دخیل است.»
محققان انتروپیک با استفاده از تکنیکی به نام «یادگیری دیکشنری» با استفاده از «کدگذارهای خودکار پراکنده» (Sparse Autoencoders)، شروع به تلاش برای مطابقت دادن الگوهای «فعالسازی نورونها» با مفاهیم و ایدههای آشنا برای انسانها کردند. آنها اواخر سال گذشته با کار بر روی نسخههای «اسباببازی» بسیار کوچک مدلهای زبان، با موفقیت «الگوهای فکری» را کشف کردند و بهعنوان مدلهایی که با ایدههایی مانند توالیهای DNA، اسمها در ریاضیات و متن با حروف بزرگ سروکار داشتند، فعال میشدند.
این شروعی امیدوارکننده بود، امّا تیم به هیچ وجه مطمئن نبود که این روش به اندازۀ مدلهای زبانی تجاری امروزی مقیاسپذیر باشد، چه برسد به ماشینهایی که در آینده ساخته خواهند شد. بنابراین، انتروپیک یک مدل یادگیری دیکشنری تولید کرد که قادر به استفاده با مدل زبان بزرگ کلود سونِت ۳ با اندازۀ متوسط خود بود و به آزمایش این رویکرد در مقیاس بزرگ پرداخت.
نتیجۀ کار؟ تیم شگفتزده شد. نوشتۀ وبلاگ میگوید:
«ما با موفقیت میلیونها ویژگی را از لایۀ میانی کلود سونِت ۳.۰ استخراج کردیم و یک نقشۀ مفهومی کلی از حالتهای داخلی آن در نیمۀ راه محاسباتش ارائه دادیم. این اولین نگاه دقیق به درون یک مدل زبان بزرگ مدرن و درجه یک است.»
جالب است که بدانیم هوش مصنوعی مفاهیم را به روشهایی ذخیره میکند که مستقل از زبان یا حتی نوع داده است، به عنوان مثال: «ایده» پل گلدن گیت، هنگامی که مدل تصاویر پل یا متن به زبانهای مختلف را پردازش میکند، روشن میشود.
و «ایدهها» نیز میتوانند بسیار انتزاعیتر از آن باشند. تیم انتروپیک ویژگیهایی را کشف کرد که هنگام مواجهه با مواردی مانند: خطاهای کدگذاری، سوگیری جنسیتی، یا روشهای مختلف برخورد با مفهوم احتیاط یا محرمانگی، فعال میشدند.
همچنین، محققان توانستند به روابط میان مفاهیم مختلف ذخیره شده در «مغز» مدل نگاه کنند، معیاری از «فاصله» بین آنها ایجاد نمایند و مجموعهای از نقشههای ذهنی بسازند، که نشان میدهد مفاهیم در چه حد به هم نزدیک هستند.
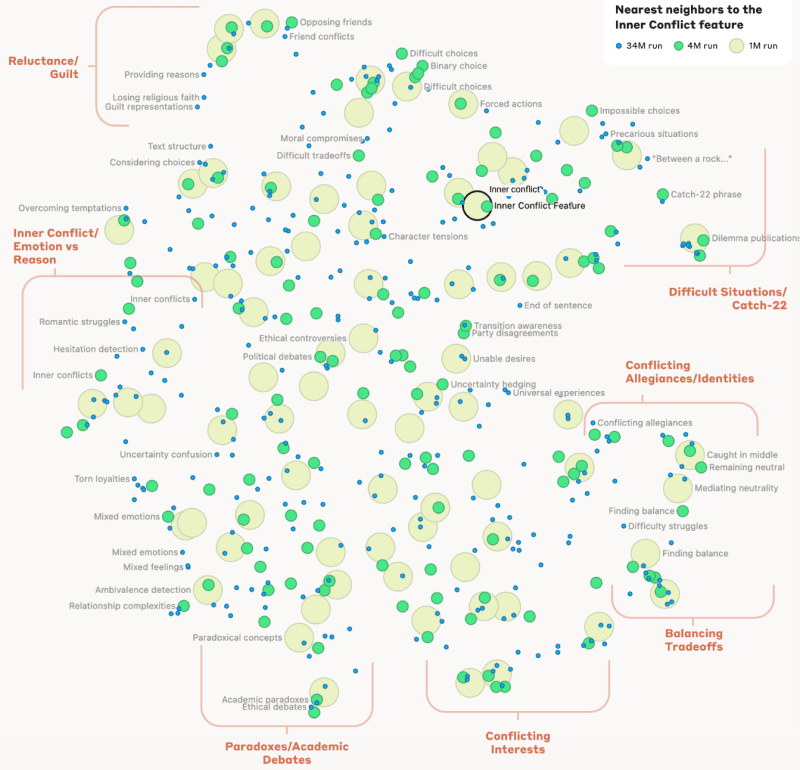
همین موضوع در مورد مفاهیم انتزاعیتر نیز صادق است، تا جایی که به ایدۀ موقعیت CATCH-22 (یک موقعیت ناامیدکننده) میرسد، که مدل آن را به «انتخابهای غیرممکن»، «وضعیتهای دشوار»، «تناقضات عجیب» و «بین دو راهی گیر کردن» گروهبندی کرده بود. تیم انتروپیک مینویسد:
«این نشان میدهد که سازماندهی داخلی مفاهیم در مدل هوش مصنوعی، حداقل تا اندازهای، با برداشتهای ما انسانها از شباهت مطابقت دارد. این ممکن است منشأ توانایی عالی کلود در ساختن قیاسها و استعارهها باشد.»
آغاز جراحی مغز هوش مصنوعی
تیم انتروپیک در این پست وبلاگی مینویسد:
«مهمتر اینکه، ما همچنین میتوانیم این ویژگیها را دستکاری، یا به طور مصنوعی تقویت، یا سرکوب کنیم تا ببینیم چگونه پاسخهای کلود تغییر میکند.»
این تیم دست به «بستن» (غیرفعال کردن) برخی مفاهیم زد و مدل را به گونهای تغییر داد که برخی ویژگیها مجبور به فعال شدن در زمان پاسخدهی به پرسشهای کاملاً نامرتبط شدند.
این موضوع بسیار باورنکردنی است؛ شرکت انتروپیک نشان داده است که نه تنها میتواند نقشۀ ذهنی یک هوش مصنوعی را ایجاد کند، بلکه توانایی ویرایش روابط درون آن نقشه را دارد و میتواند با درک مدل از جهان – و در نتیجه رفتار آن – بازی کند.
در اینجا پتانسیل ایمنی هوش مصنوعی کاملاً واضح است. اگر بدانید افکار بد کجا هستند و بتوانید بفهمید چه زمانی هوش مصنوعی به آنها فکر میکند، یک لایۀ نظارت اضافی دارید که میتواند به عنوان ناظر استفاده شود. همچنین اگر بتوانید اتصالات بین مفاهیم خاص را تقویت یا تضعیف کنید، به طور بالقوه میتوانید باعث شوید رفتارهای خاصی از محدودۀ پاسخهای احتمالی هوش مصنوعی ناپدید شوند، یا حتی ایدههای خاصی را برای درک آن از جهان حذف کنید.
این مفهوم، یادآور صحنۀ فیلم علمی-تخیلی شاهکار «درخشش ابدی یک ذهن پاک» است، جایی که جیم کری و کیت وینسلت به شرکتی برای پاک کردن خاطراتشان از یکدیگر پس از جدایی مراجعه میکنند و مانند آن فیلم، این سوال را مطرح میکند: آیا واقعاً میتوانید یک ایدۀ قدرتمند را به طور کامل پاک کنید؟
تیم انتروپیک همچنین خطر بالقوۀ این رویکرد را با «بستن» مفهوم ایمیلهای فریبنده نشان داد و چگونگی دور زدن سریع آموزش تراز (همراستا) مدل کلود برای ممنوعیت نوشتن چنین محتوایی توسط یک اتصال ذهنی قدرتمند به این ایده را به نمایش گذاشت. این نوع جراحی مغز هوش مصنوعی واقعاً میتواند باعث افزایش به شدت پتانسیل مدل برای رفتارهای شرورانه شود و به آن اجازه دهد تا از موانع ایمنی خودش عبور کند.
با وجود این، تیم انتروپیک تردیدهای دیگری دربارۀ وسعت این فناوری دارد. آنها مینویسند:
«کار واقعاً به تازگی آغاز شده است. ویژگیهایی که ما پیدا کردیم، زیرمجموعۀ کوچکی از تمام مفاهیمی را نشان میدهند که مدل در طول آموزش یاد گرفته است و یافتن مجموعهای کامل از ویژگیها با استفاده از تکنیکهای فعلی ما هزینهبر خواهد بود (محاسبات مورد نیاز رویکرد فعلی ما به طور قابل توجهی از محاسبات مورد استفاده برای آموزش مدل در وهلۀ اول بیشتر خواهد بود).»
«درک بازنماییهایی که مدل استفاده میکند به ما نمیگوید که چگونه از آنها استفاده میکند؛ حتی با داشتن این ویژگیها، هنوز هم باید مدارهایی را بیابیم که آنها درگیرش هستند. همچنین ما باید نشان دهیم که ویژگیهای مرتبط با ایمنی که شروع به یافتن آنها کردهایم، در واقع میتوانند برای بهبود ایمنی مورد استفاده قرار گیرند. پس کارهای بیشتری باید انجام شود.»
به عبارت دیگر، این نوع فناوری میتواند ابزاری بسیار ارزشمند باشد، امّا به ندرت میتواند فرآیندهای ذهنی یک هوش مصنوعی در مقیاس تجاری را به طور کامل درک کند. این موضوع به افراد فاجعهنگر آرامش کمی میدهد، چرا که آنها اشاره میکنند که وقتی پیامدها بالقوهای وجود دارد، نرخ موفقیت ۹۹.۹۹۹ درصد کافی نیست.
امّا باید گفت که این یک پیشرفت خارقالعاده و یک درک قابل توجه در مورد شیوۀ درک این ماشینهای باورنکردنی از جهان است. اگر روزی اندازهگیری آن ممکن شود، دیدن اینکه نقشۀ ذهنی یک هوش مصنوعی در چه حد به یک انسان نزدیک است، بسیار جالب خواهد بود.
OpenAI هم روی درکپذیری هوش مصنوعی کار میکند
شرکت انتروپیک یکی از بازیگران کلیدی در حوزۀ هوش مصنوعی/مدلهای زبان بزرگ مدرن است، امّا غول این فضا به طور قطع همچنان OpenAI، سازندگان مدلهای پیشگام GPT است، شرکتی که بیشترین هدایت مکالمۀ عمومی در مورد هوش مصنوعی را برعهده دارد.
در واقع، شرکت انتروپیک در سال ۲۰۲۱ توسط گروهی از کارمندان سابق OpenAI تأسیس شد تا ایمنی و قابلیت اطمینان هوش مصنوعی را در صدر فهرست اولویتها قرار دهد، در حالی که OpenAI با مایکروسافت همکاری کرد و فعالیت خود را بیشتر به عنوان یک نهاد تجاری ادامه داد.
با وجود این، OpenAI نیز بر روی درکپذیری کار کرده و از رویکردی بسیار مشابه بهره برده است. در تحقیقی که در اوایل ژوئن منتشر شد، تیم درکپذیری OpenAI اعلام کرد که حدود ۱۶ میلیون الگوی «فکری» در GPT-4 پیدا کرده است، که بسیاری از آنها را قابل رمزگشایی و مطابقت با مفاهیم قابل درک برای انسان میدانند.
به نظر میرسد تیم OpenAI هنوز به حوزههای نقشهسازی یا ویرایش ذهنی وارد نشده است، امّا به چالشهای ذاتی در درک یک مدل هوش مصنوعی بزرگ در زمان کار اشاره میکند. تیم انتروپیک در این باره مینویسد:
«در حال حاضر، عبور دادن فعالسازیهای GPT-4 از طریق کدگذار خودکار پراکنده سبب عملکردی معادل یک مدلی میشود که با حدود ۱۰ برابر محاسبات کمتر آموزش دیده است. برای نقشهبرداری کامل از مفاهیم در مدلهای زبان بزرگ پیشرفته، امکان دارد نیاز به میلیاردها یا تریلیونها ویژگی داشته باشیم، که حتی با تکنیکهای مقیاسبندی بهبودیافتۀ ما نیز چالشبرانگیز خواهد بود.»
بنابراین این مورد در هر دو شرکت، اکنون در روزهای ابتدایی است. امّا حداقل امروزه بشر دو راه برای باز کردن «جعبۀ سیاه» شبکۀ عصبی هوش مصنوعی و شروع به درک شیوۀ تفکر آن در اختیار دارد.



















