شرکت اوپنایآی با معرفی معیار جدیدی به نام GDPval برای سنجش عملکرد اقتصادی هوش مصنوعی اعلام کرد که مدل GPT-5 در ۴۰٫۶ درصد از وظایف شغلی تخصصی، عملکردی همسطح یا بهتر از متخصصان انسانی داشته است.
به گزارش تکناک، شرکت OpenAI اخیراً معیار تازهای با نام GDPval معرفی کرده که توانایی مدلهای هوش مصنوعی را در مقایسه با متخصصان انسانی در مشاغل مختلف میسنجد. هدف این آزمون، بررسی میزان پیشرفت سیستمهای OpenAI در انجام کارهای اقتصادی ارزشمند و حرکت به سوی تحقق هوش عمومی مصنوعی (AGI) است.
به گفته OpenAI، نتایج اولیه نشان میدهد مدل GPT-5 و رقیب آن، Claude Opus 4.1 از شرکت Anthropic، در بسیاری از وظایف به سطح کاری نزدیک به متخصصان صنعت رسیدهاند.
با این حال، OpenAI تأکید میکند که این دستاورد به معنای جایگزینی فوری انسانها با مدلهای هوش مصنوعی نیست. آزمون GDPval در نسخه نخست خود تنها بخشی از وظایف شغلی را پوشش میدهد و محدود به تولید و ارزیابی گزارشهاست. این معیار بر پایه ۹ صنعت اصلی آمریکا از جمله بهداشت، مالی، تولید و بخش دولتی طراحی شده و عملکرد مدلها را در ۴۴ شغل مختلف از پرستاری و روزنامهنگاری گرفته تا مهندسی نرمافزار بررسی میکند.
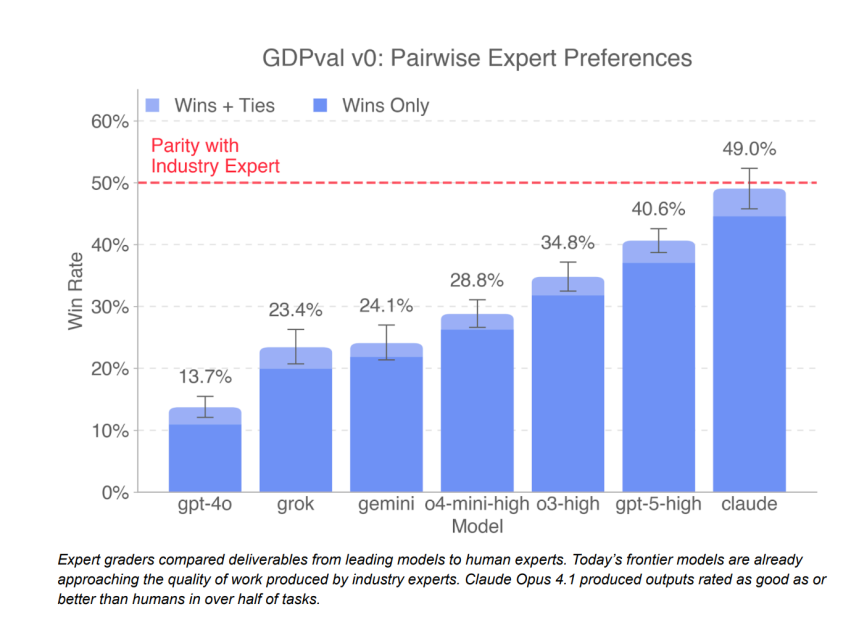
به نقل از تککرانچ، در این آزمایش، گزارشهای تولیدشده توسط مدلها در برابر گزارشهای حرفهای قرار گرفت و کارشناسان مأمور شدند بهترین نمونه را انتخاب کنند. برای مثال، در یک مورد از بانکداران سرمایهگذاری خواسته شد تحلیلی درباره بازار «تحویل آخرین مایل» ارائه دهند و سپس این گزارش با خروجی مدلها مقایسه شد. نتایج نشان داد نسخه قدرتمندتر GPT-5-high در ۴۰.۶ درصد موارد همسطح یا بهتر از متخصصان ارزیابی شده است. در همین حال، Claude Opus 4.1 در ۴۹ درصد وظایف چنین جایگاهی به دست آورد؛ هرچند OpenAI این امتیاز بالا را تا حدی ناشی از ارائه نمودارها و گرافیکهای جذاب میداند.
دکتر آرون چاترجی، اقتصاددان ارشد OpenAI، میگوید این نتایج نشان میدهد متخصصان میتوانند بخشی از وظایف خود را به مدلها بسپارند و زمان بیشتری را صرف کارهای ارزشآفرینتر کنند. او تأکید میکند که پیشرفت سریع این مدلها، فرصت تازهای برای افزایش بهرهوری در بسیاری از مشاغل ایجاد کرده است.
از سوی دیگر، تجال پاتواردان، مدیر ارزیابی OpenAI، به سرعت رشد این مدلها اشاره میکند. به گفته او، مدل GPT-4o که تنها ۱۵ ماه پیش عرضه شده بود، در آزمون مشابه تنها ۱۳.۷ درصد امتیاز به دست آورد؛ اما اکنون GPT-5 نزدیک به سه برابر بهتر عمل کرده است.
در حال حاضر، صنعت هوش مصنوعی از معیارهای مختلفی برای سنجش توانایی مدلها استفاده میکند؛ از جمله AIME 2025 (آزمون ریاضیات پیشرفته) و GPQA Diamond (سؤالات علمی در سطح دکتری). با این حال، بسیاری از این آزمونها به نقطه اشباع نزدیک شدهاند و پژوهشگران معتقدند معیارهای تازهای مانند GDPval که بر وظایف واقعی تمرکز دارند، اهمیت بیشتری پیدا خواهند کرد.
OpenAI معتقد است که پیشرفت در GDPval میتواند نشان دهد مدلهای هوش مصنوعی نهتنها در آزمایشهای تئوری بلکه در کاربردهای عملی نیز جایگاه ارزشمندی برای صنایع مختلف خواهند داشت؛ هرچند برای اثبات برتری کامل آنها بر انسان، به نسخههای جامعتر و دقیقتر از این آزمون نیاز خواهد بود.