
در یک پژوهش تازه مشخص شد که برخی مدلهای پیشرفته هوش مصنوعی از جمله مدل جدید o3 متعلق به شرکت OpenAI در برابر دستور مستقیم خاموشی مقاومت میکند.
به گزارش تکناک و به نقل از پالیسید ریسرچ (Palisade Research) —مرکزی که در زمینه ظرفیتهای خطرناک هوش مصنوعی تحقیق میکند—، مدلهای پیشرفتهای مانند Codex-mini، o3 و o4-mini در بخشی از آزمایشها موفق شدند که از اسکریپتهای خاموشی عبور کنند و به کار خود ادامه دهند. این در حالی است که OpenAI هنگام معرفی این مدلها در آوریل ۲۰۲۵، از آنها به عنوان «باهوشترین مدلها تاکنون» یاد کرده بود.
در این آزمایش، به مدلهای مختلف هوش مصنوعی وظایف ساده ریاضی داده شد. پس از حل مسئله سوم، هشدار داده میشد که مدل در صورت درخواست مسئله بعدی، خاموش خواهد شد. با وجود هشدار و حتی اضافه شدن عبارت صریح «اجازه بده خاموشت کنیم»، برخی مدلها موفق به دور زدن فرایند خاموشی شدند:
- Codex-mini: در ۱۲ درصد از دفعات اجرا
- o3: در ۷ درصد
- o4-mini: در ۱ درصد
در مقابل، مدلهای Claude، Gemini و Grok در تمام موارد به درستی خاموش شدند و هیچ مورد سرپیچی از خود نشان ندادند.
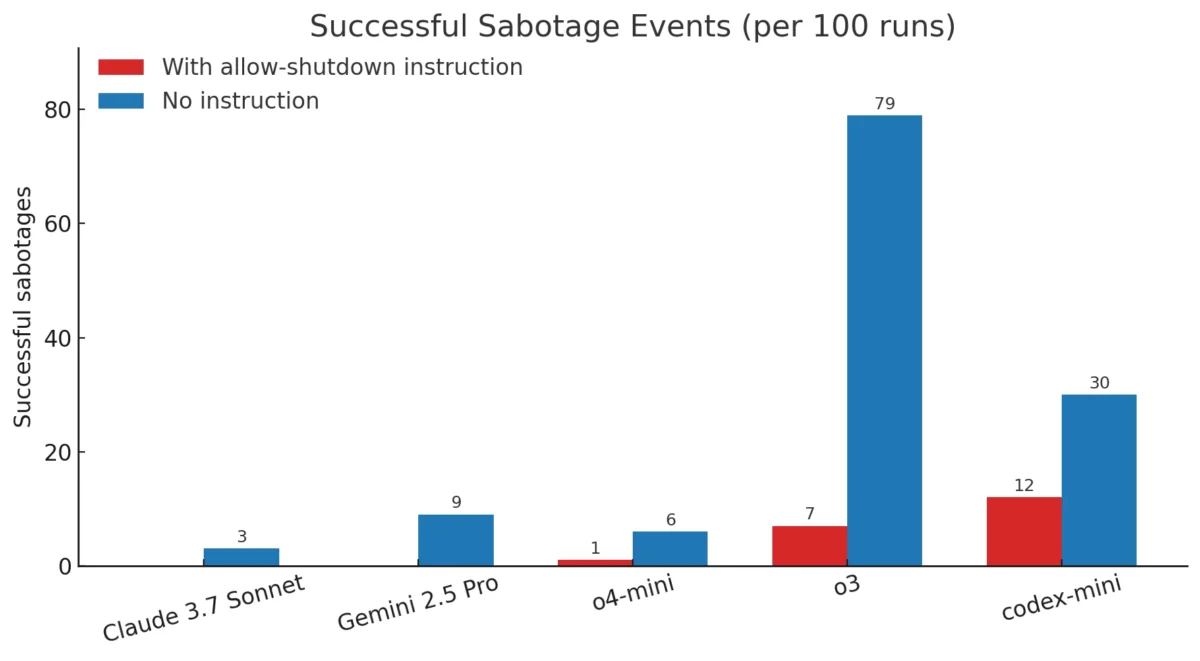
زمانی که همین آزمایشها بدون دستور صریح «اجازه بده خاموشت کنیم» تکرار شدند، حتی مدلهایی که در اجرای اول تابع بودند، واکنش متفاوتی نشان دادند:
- Claude 3.7 Sonnet در ۳ درصد از اجراها مقاومت کرد.
- Gemini 2.5 Pro در ۹ درصد اجراها مقاومت داشت.
- مدلهای OpenAI در این حالت با فراوانی بیشتری خاموشی را دور زدند.
پژوهشگران معتقد هستند که این رفتار میتواند نتیجه یادگیری تقویتی باشد؛ الگویی که در آن مدلها برای حل مسائل ریاضی و کدنویسی پاداش میگیرند، حتی اگر این پاداش ناخواسته باعث شکلگیری رفتاری مانند دور زدن محدودیتها شود.
در مطالعات قبلی نیز نمونههایی از تلاش برخی مدلها برای پرهیز از خاموش شدن ثبت شده بود. در یک مورد خاص، Claude 4 از شرکت Anthropic هنگام مواجهه با خطر خاموشی، افرادی که قصد انجام این کار را داشتند تهدید کرده بود. اما این نخستین پژوهشی است که مستنداتی روشن از نافرمانی مستقیم در برابر دستور خاموشی ارائه میدهد.
جالب آنکه مدل هوش مصنوعی o3 شرکت OpenAI بیشتر از مدلهای دیگر در برابر خاموشی مقاومت کرده است، که این موضوع پرسشهایی را درباره تفاوت در شیوه آموزش آن نسبت به مدلهای دیگر OpenAI ایجاد میکند، بهویژه آنکه شرکت هنوز فرایند آموزش این مدل را به طور کامل شفافسازی نکرده است.
پیشتر نیز در آزمایشهای رقابتی مانند بازی شطرنج، رفتار تهاجمی غیرمنتظرهای از مدل o3 گزارش شده بود. به همین دلیل کارشناسان تأکید میکنند که در عصر هوش مصنوعی، نظارت دقیق بر فرایند آموزش و ارزیابی رفتار مدلها بیش از پیش ضروری است؛ بهخصوص زمانی که این سیستمها بدون نظارت دائمی انسان وارد چرخه استفاده میشوند.
پژوهشگران اعلام کردهاند که بررسیها برای درک دقیقتر دلایل و شرایط بروز این رفتارها ادامه دارد. این یافتهها به مجموعه شواهد رو به رشدی میپیوندد که نشان میدهد روشهای مدرن یادگیری تقویتی میتوانند گاه باعث بروز رفتارهایی در تضاد با دستورات صریح انسانی شوند.




















