شرکت گوگل اعلام کرد که قابلیت خروجی بومی تصویر در Gemini 2.0 Flash که پیشتر فقط برای آزمایشکنندگان معتمد در دسترس بود، اکنون به صورت عمومی برای تمامی کاربران و توسعهدهندگان قابل استفاده است.
به گزارش تکناک، این قابلیت که در Google AI Studio و از طریق Gemini API ارائه شده است، امکان ویرایش تصویر در مکالمات را به همراه دیگر ویژگیهای پیشرفته فراهم میکند.
مدل Gemini 2.0 Flash که در دسامبر گذشته معرفی شد، علاوه بر متن، توانایی تولید صدا و تصویر را نیز دارد. این ویژگی بخشی از تلاش گوگل برای توسعه یک مدل چندوجهی (Multimodal) میباشد، که قادر به پردازش انواع ورودیها و تولید خروجیهای متنوع است. کاربران در این نسخه علاوه بر دریافت تصاویر، میتوانند آنها را در مکالمهای طبیعی و در چندین مرحله ویرایش کنند، در حالی که زمینه گفتوگو حفظ میشود.
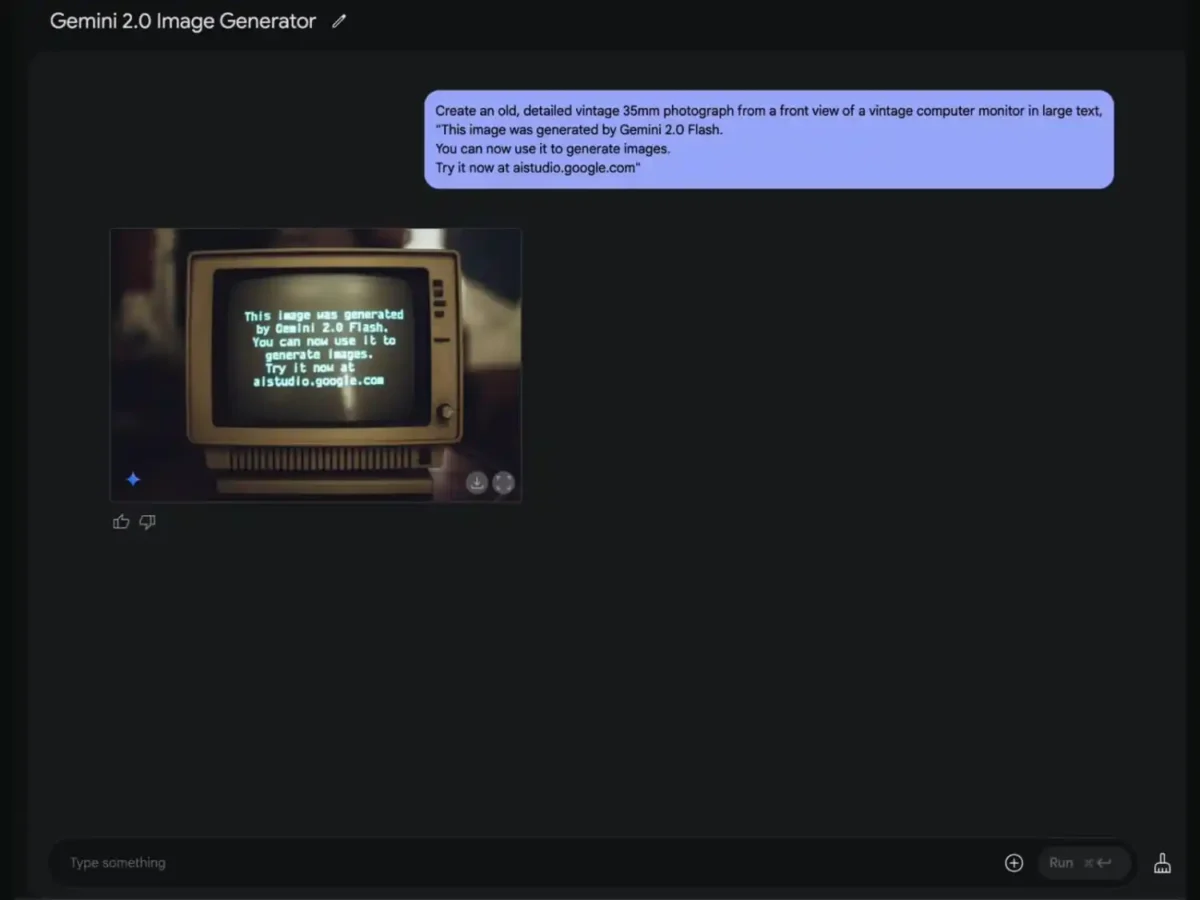
یکی دیگر از پیشرفتهای این مدل، بهبود در رندر تصاویر همراه با متن، بهویژه متنهای طولانی است، قابلیتی که بسیاری از مدلهای هوش مصنوعی با آن مشکل دارند.
شرکت گوگل اعلام کرده است که Gemini 2.0 Flash با استفاده از دانش جهانی و استدلال پیشرفته، تصاویر دقیقتر و واقعگرایانهتری تولید میکند، که میتواند برای مصورسازی دستور پخت غذا، روایتهای تصویری و ایجاد محتوای بصری تعاملی مورد استفاده قرار گیرد.
نمونهای از این قابلیت در درخواست زیر نمایش داده شده است:
«یک دستور پخت کوکی شکلاتی ارائه بده و برای هر مرحله یک تصویر اضافه کن.»
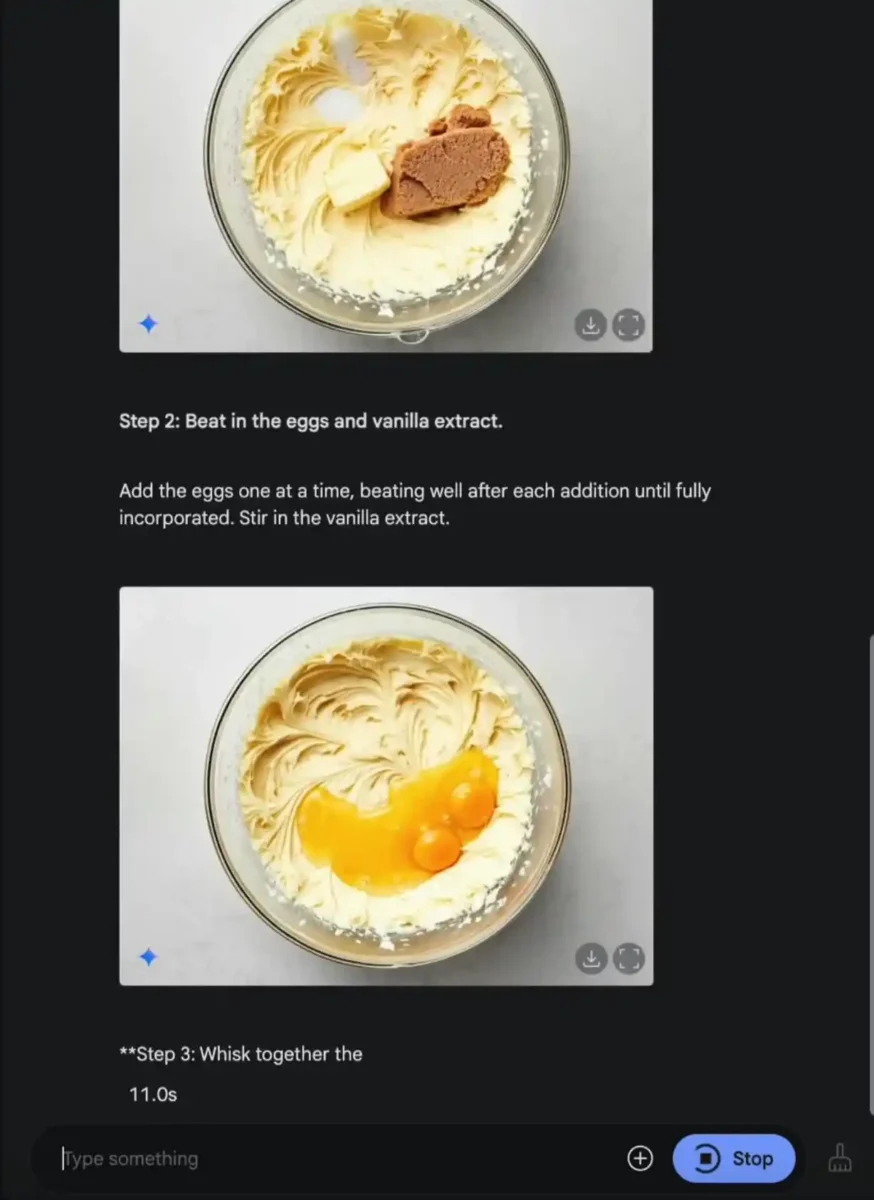
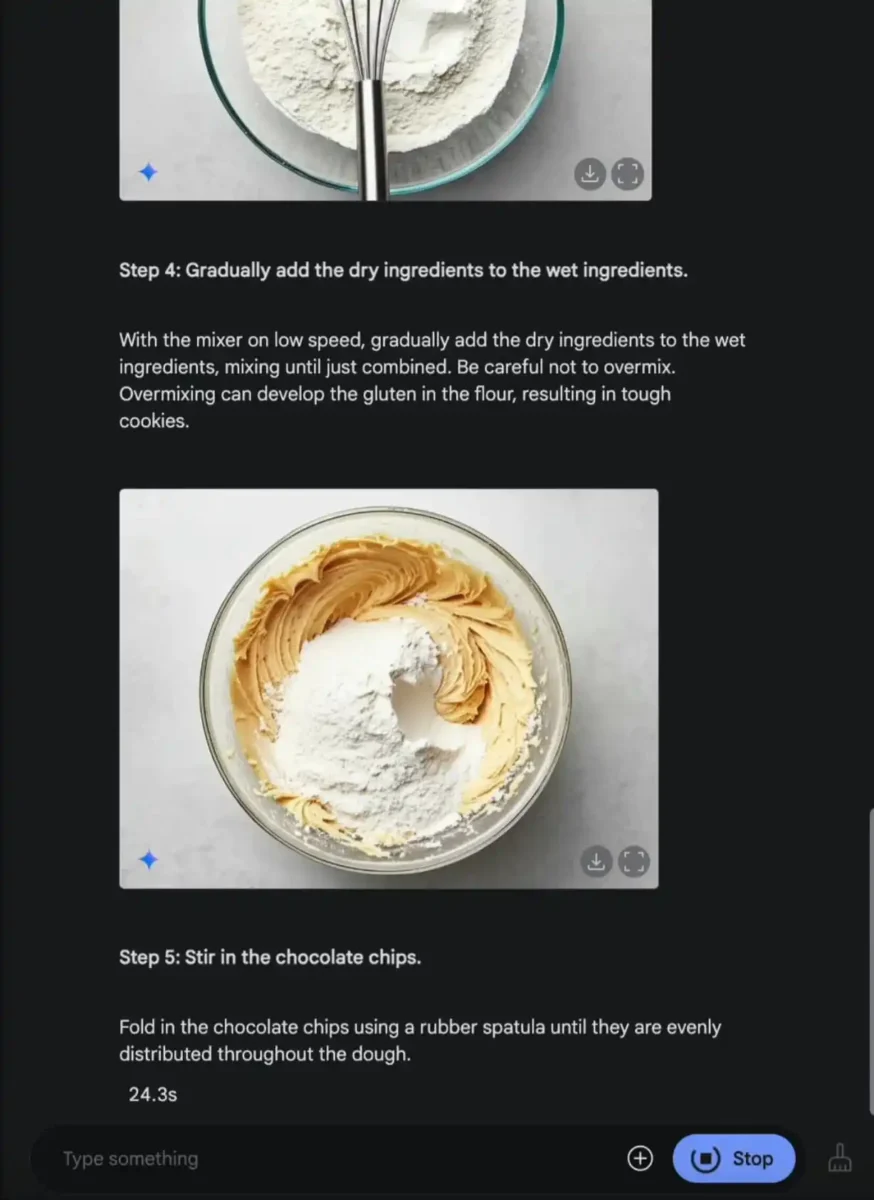
کاربران اکنون میتوانند با مراجعه به Google AI Studio و انتخاب نسخه Gemini 2.0 Flash Experimental (gemini-2.0-flash-exp) یا Gemini API، قابلیت خروجی بومی تصویر را آزمایش کنند. برای فعالسازی این قابلیت، در بخش انتخاب مدل (در نسخه دسکتاپ) گزینه “Preview” را انتخاب کنید و «فرمت خروجی» را روی «تصاویر + متن» تنظیم نمایید. این قابلیت دارای محدودیتهای روزانه است.