گوگل مدل جدیدی از زبان بینایی (VLA) به نام RT-2 را برای آموزش ربات ها معرفی کرده است که آن را اولین در نوع خود توصیف می کند.
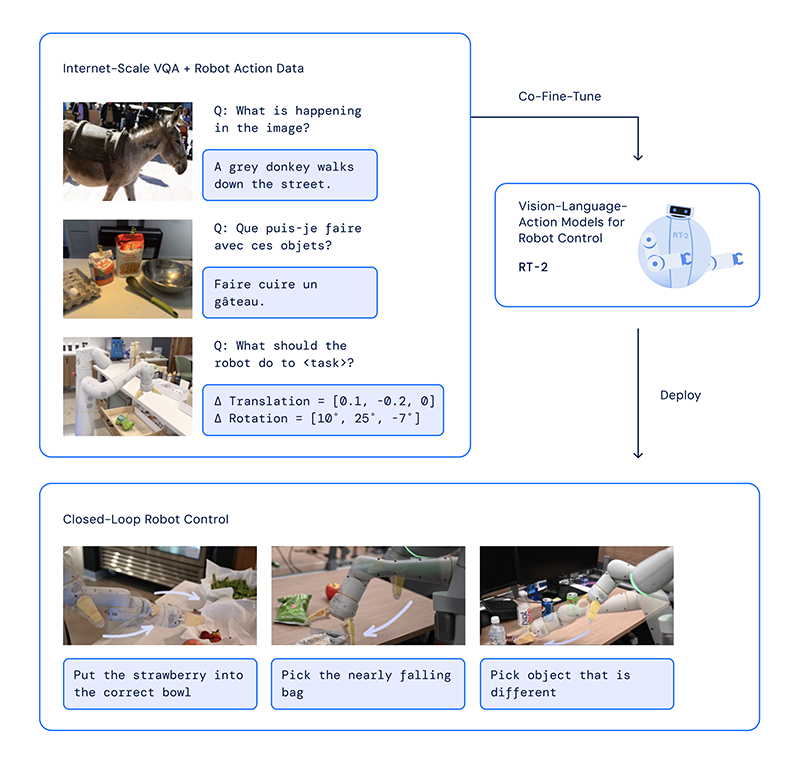
به گزارش تکناک و به گفته گوگل، RT-2 (Robotics Transformer 2) می تواند ورودی های متن یا تصویر را بگیرد و کارهای رباتیک را به عنوان خروجی ارائه دهد.
این شرکت گفت که آموزش رباتها میتواند یک تلاش بزرگ باشد، زیرا آنها به آموزش روی میلیاردها نقطه داده برای هر شی، محیط، وظیفه و موقعیت در جهان نیاز دارند. با این حال گوگل می گوید: با RT-2، یک وعده بزرگ برای ربات های عمومی تحقق یافته است.
در حالی که این شرکت در مورد دستاورد های RT-2 هیجان زده است، گفت که برای فعال کردن ربات های مفید در محیط های انسان محور باید کارهای زیادی انجام شود. در پایان، طبق گفته DeepMind، یک ربات فیزیکی عمومی میتواند حاصل مدلهای VLA باشد و آنها میتوانند اطلاعات را برای انجام کارهای دنیای واقعی استدلال، حل و تفسیر کنند.

همانطور که از نام آن پیداست، این اولین تکرار از مدل Robotics Transformer VLA نیست. DeepMind گفت که RT-2 بر روی RT-1 ساخته شده و قابلیت های تعمیم بهبود یافته را در مقایسه با مدل های قبلی نشان می دهد و در کارهای جدید و دیده نشده بهتر عمل می کند.
یکی دیگر از مهارت های جدید که RT-2 نسبت به پیشینیان خود قادر به انجام آن بود، استدلال نمادین است که به این معنی است که می تواند مفاهیم انتزاعی را درک کند و آنها را به طور منطقی انجام دهد. یکی از نمونههای آن زمانی است که از ربات خواسته شد که عددی را به مجموع 2 به اضافه 1 اضافه کند و ربات کار را به درستی انجام داد، حتی اگر برای انجام ریاضیات محض آموزش ندیده باشد.
در حالی که RT-2 یک گام بزرگ رو به جلو برای رباتیک است، منصفانه نیست که اعلام کنیم ربات های ترمیناتور وارد شده اند. این مدل همچنان به ورودی و نظارت انسانی نیاز دارد و محدودیت های فنی قابل توجهی را در عملیات ربات های دنیای واقعی تجربه می کند.
با این اوصاف، امیدواریم به رباتهای جالبی برسیم که میتوانند کارهایی را انجام دهند که قبلاً امکانپذیر یا آسان نبود.