نتایج بنچمارکها نشان میدهند که موتور CoreAI اپل در مدلهای کوچک سریعتر از MLX عمل میکند، اما در مدلهای بزرگتر اختلاف عملکرد کاهش مییابد.
به گزارش سرویس سختافزار تکناک، شرکت اپل در سال ۲۰۱۷ فریمورک CoreML را به عنوان زیرساخت اصلی یادگیری ماشین روی دستگاه معرفی کرد که بیشتر برای اجرای محاسبات سبک و ایستا نظیر image classification و tree ensembleها طراحی شده بود. موتور CoreAI اپل به عنوان نسل جدید این فریمورک، با تمرکز بر هوش مصنوعی و استتناج روی دستگاه، جایگزین معماری قبلی به حساب میآید. در مقابل، MLX یک موتور پردازشی است که بیشتر برای پژوهش و آموزش مدلها طراحی شده و به معماری GPU متال و حافظه یکپارچه اپل وابسته است.
بر اساس نتایج یک بنچمارک جدید، ارزیابی عملکرد CoreAI اپل نکات قابل توجهی را نشان میدهد. در مدلهای کوچک مانند Qwen3 با ۰.۶ میلیارد پارامتر، CoreAI در وظایف دیکودینگ روی مک M4 حدود ۲.۴۷ برابر سریعتر از MLX عمل میکند. همچنین روی آیفون ۱۷ پرو، همین موتور حدود ۱.۶ برابر سریعتر از MLX در دیکودینگ ظاهر شده است. اما با افزایش اندازه مدل به سطح کاربردیتر ۸ میلیارد پارامتر (Qwen3 8B روی مک M4 Max)، برتری موتور CoreAI اپل تقریبا از بین میرود و تنها حدود ۱.۰۵ برابر سریعتر از MLX عمل میکند. نکته جالب این است که در بارهای محاسباتی سنگین روی آیفون ۱۷ پرو، GPU بهسرعت دچار افت عملکرد حرارتی میشود و در نتیجه ترکیب CoreML و Apple Neural Engine از نظر پایداری عملکرد جلو میافتد. این ترکیب کمترین مصرف حافظه را دارد، اما در سرعت دیکودینگ کندترین گزینه محسوب میشود.
بیشتر بخوانید: قیمت حافظههای DDR5 تا ۲۰۲۷ بالا می ماند
خبر پیشنهادی: سامسونگ جایگاه نخست خود را در بازار حافظه حفظ کرد
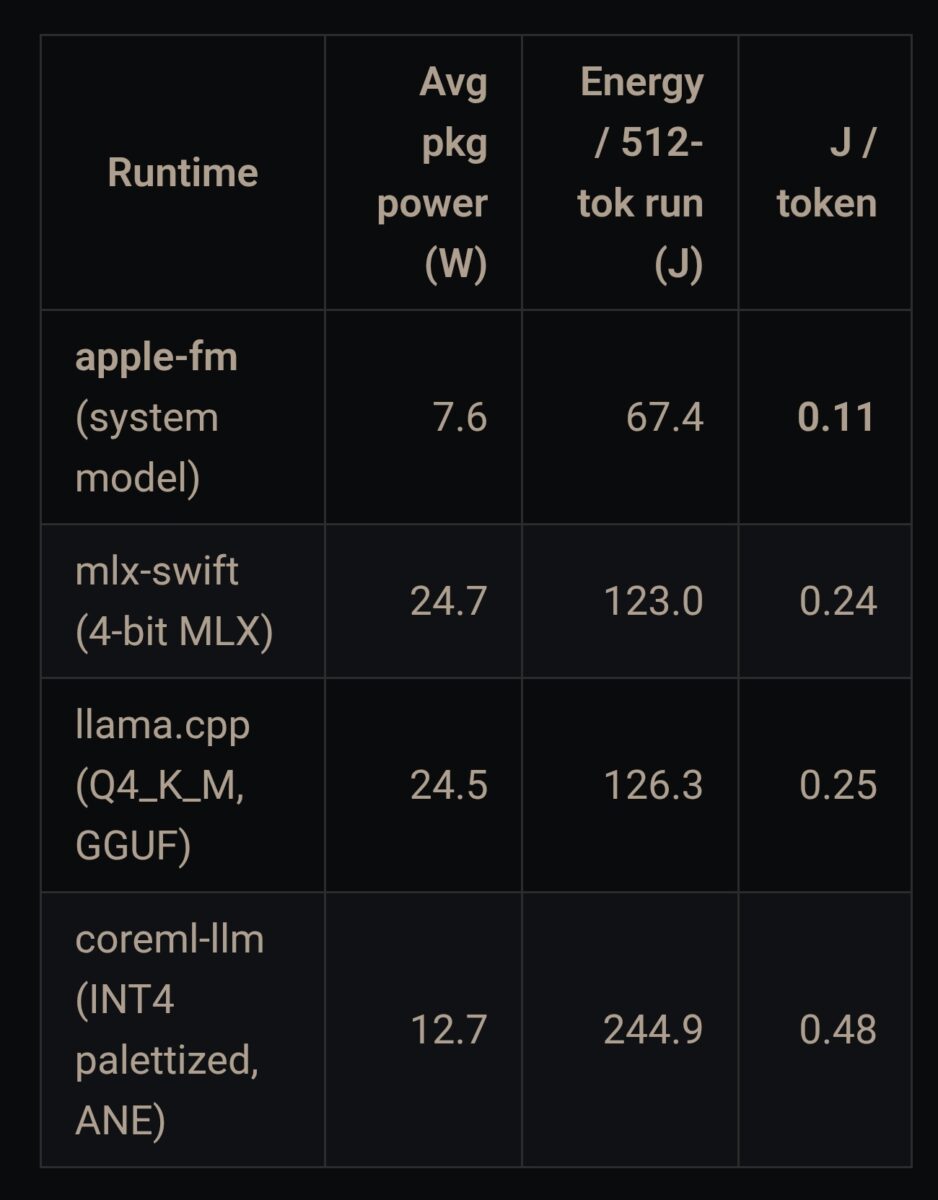
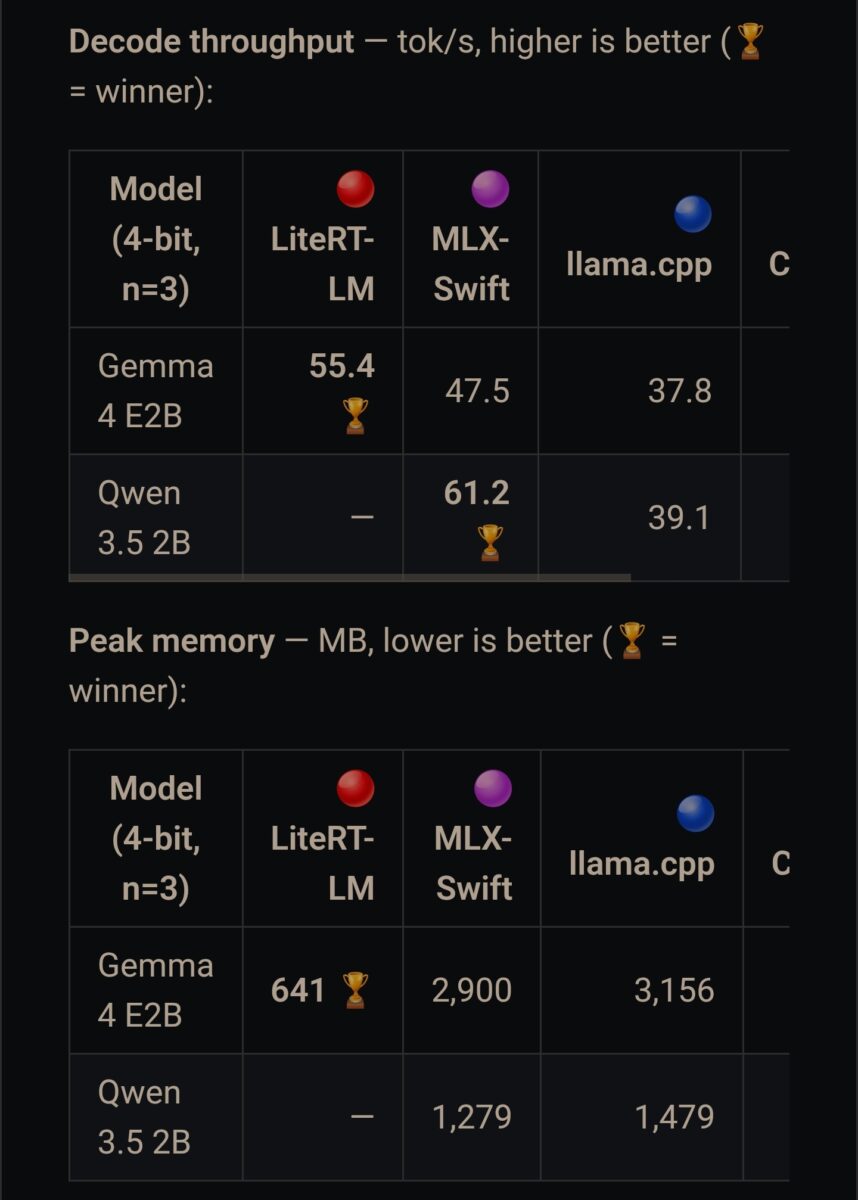
موتورهایی که برای مدلهای خاص یک شرکت بهینه شدهاند معمولا از موتورهای عمومی عملکرد بهتری دارند. برای مثال، موتور LiteRT-LM گوگل هنگام اجرای مدل Gemma در آیفون ۱۷ پرو نهتنها سریعترین عملکرد را با ۵۵.۴ توکن بر ثانیه ثبت کرده، بلکه ۴.۵ برابر کمتر از چارچوب MLX اپل حافظه مصرف کرده است (۶۴۱ مگابایت در برابر ۲.۹ گیگابایت). در نهایت، مدلهای پایه اپل از نظر مصرف انرژی به ازای هر توکن حدود دو برابر بهینهتر از اجراهای مبتنی بر GPU و حدود چهار برابر بهینهتر از ترکیب CoreML/ANE عمل میکنند.